Format, Behavior, and the Shape of a Repeated Task
> **Working claim:** This is where fine-tuning shines.

Working claim: This is where fine-tuning shines. When a task is high-volume, its desired output has a stable shape, and the behavior is the same every time, training that shape into the weights buys reliability, shorter prompts, and lower cost that prompting cannot match. The skill is recognizing a genuine "stable repeated task," distinguishing it from a knowledge task wearing the same clothes, and writing training examples that teach the shape without smuggling in facts.
Key Takeaways
- Stable repeated tasks are the positive case for fine-tuning.
- The value comes from reliability, shorter prompts, and cost, not from storing facts.
- Structured-output constraints still belong in the system when syntax must be guaranteed.
The positive case, stated without hedging
The first four chapters were about saying no. This movement is about saying yes, because a book that only warns is a book that gets ignored the first time fine-tuning would have helped. There is a class of problem for which fine-tuning is not just acceptable but the right and sometimes the only good answer, and it has a recognizable shape. The clearest member of the class is the stable repeated task: the same kind of input arrives thousands or millions of times, you want the same kind of output every time, and "the same kind of output" is a structural property, a format, a set of fields, a length, a decision boundary, not a fact about the world.
When you have one of these, fine-tuning pays in three currencies at once. It buys reliability: a trained model produces the desired shape far more consistently than a prompted one, because the shape is now the model's default behavior rather than an instruction it might drift away from over a long session or an unusual input. It buys shorter prompts: the instructions and few-shot examples that taught the shape can be deleted from every request once the shape is in the weights, which at high volume is real money and latency. And it buys cost, both through those shorter prompts and through the option to run a smaller model that, once specialized, matches a larger one on this narrow task (Chapter 7). The OpenAI supervised fine-tuning guide names exactly these benefits: a fine-tuned model more reliably produces a desired style and content shape, with fewer instructions needed per request.
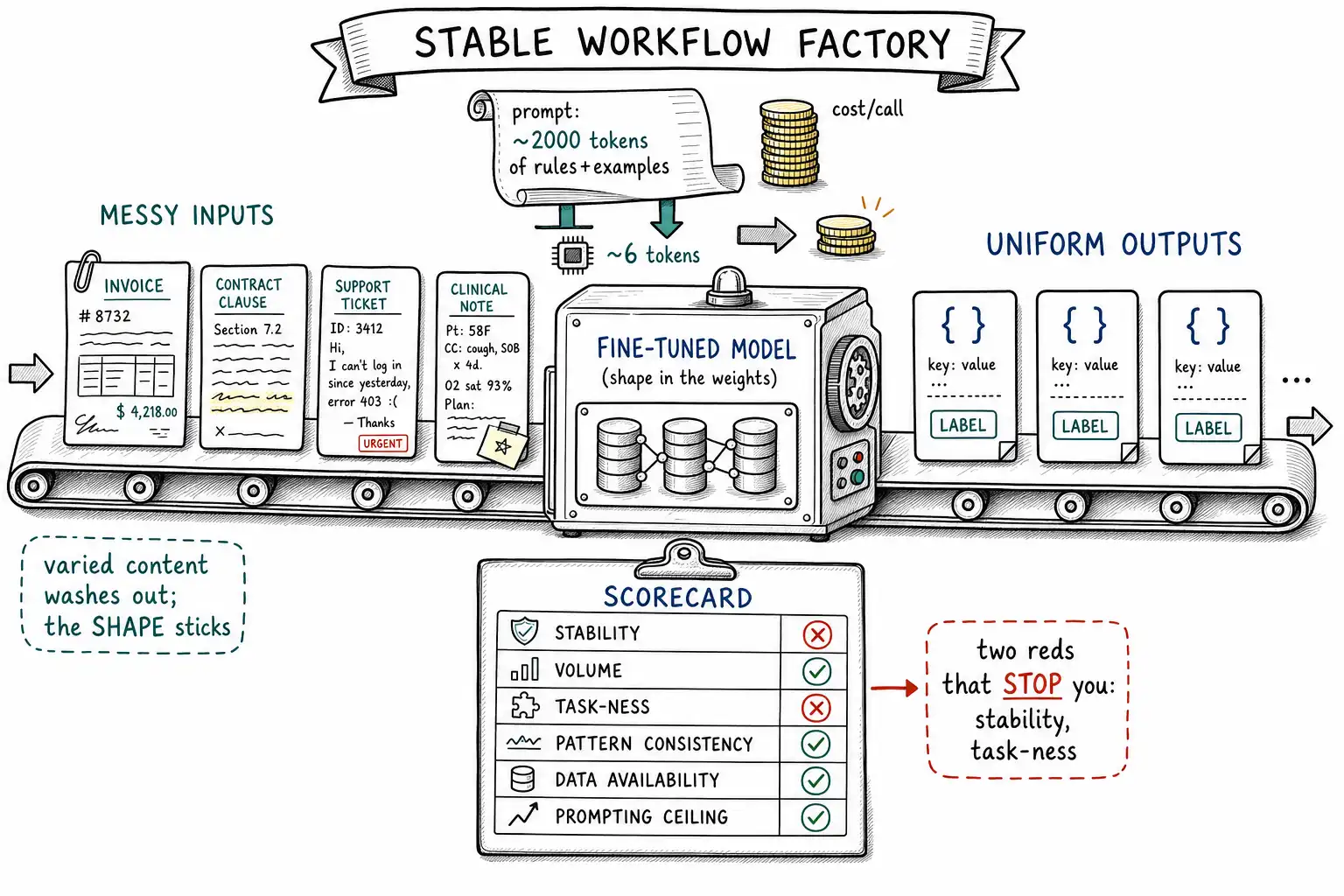
What "stable repeated task" actually means
The three words each carry weight, and a task qualifies only if all three hold.
Stable means the desired behavior is not changing faster than you can retrain. A JSON schema you redefine every sprint is not stable; a classification taxonomy your business has used for three years is. Stability is the T in TRAIN, and it is the first thing to check because instability is fatal: a model takes days to retrain and re-validate, so if the target moves weekly, the model is always behind, and you have built a maintenance treadmill. The test is blunt: how often does the correct output for a fixed input change? If the answer is "rarely, on a human timescale," it is stable enough.
Repeated means volume. Fine-tuning has fixed costs, data curation, training, evaluation, operational overhead, that only amortize over many requests. A task you run fifty times a month does not justify a training project no matter how stable; a prompt or a few-shot block is cheaper end to end. The threshold is not a fixed number but a break-even calculation (Chapter 7): the per-request savings from shorter prompts and a smaller model, times volume, must exceed the amortized cost of building and operating the fine-tune. High volume is what makes the math work.
Task, as opposed to knowledge, means the desired output is determined by the input and a fixed procedure, not by an external fact that changes."Classify this email into one of eight intents" is a task: the answer depends on the email and a stable taxonomy."Tell the customer their order status" is not a task in this sense even though it looks like one, because the answer depends on a database row that changes, that is a tools-and-state problem (Chapter 4) dressed as a task. The discriminator is the same one from Chapter 1: strip the current facts and per-request state out of the output; if a well-defined output remains, it is a task; if nothing meaningful remains, it was knowledge or state all along.
Examples of genuine stable repeated tasks
To calibrate the pattern, here are tasks from the book's running domains that genuinely qualify, with the shape each one teaches:
- Support triage. Input: an inbound ticket. Output: a category, a priority, and a routing decision. The shape is a small fixed set of labels applied consistently. (Playbook in Chapter 17.)
- Legal clause classification. Input: a contract clause. Output: a clause type and a risk flag from a fixed taxonomy. The shape is a label plus a structured rationale.
- Medical note summarization with strict disclaimers. Input: a clinical note. Output: a structured summary in a fixed template with a mandatory disclaimer block. The shape includes a non-negotiable safety element, exactly the kind of behavior worth training so it never gets dropped.
- JSON extraction from messy documents. Input: a vendor invoice in arbitrary layout. Output: a strict JSON object with fixed fields. The shape is the schema, and consistency here is the whole value.
- Code review comment classification. Input: a review comment. Output: a category (nit, bug, security, style, question). The shape is a label and a severity.
In every one, the output's value is in its consistency and structure, not in any fact it contains, which is precisely why training works. Note that the medical and legal examples carry facts and judgments that must be correct, and those still come from retrieval, tools, or human review; what the fine-tune contributes is the reliable shape and the disciplined behavior (always include the disclaimer, always emit valid JSON, always pick exactly one label).
Before and after: what the fine-tune buys
Make it concrete with a JSON-extraction task. Prompt-only, you carry the full instruction and examples on every call:
# PROMPT-ONLY: long prompt on every request, drift risk under odd inputs
SYSTEM = """Extract these fields from the invoice as STRICT JSON:
{"vendor": str, "invoice_no": str, "date": "YYYY-MM-DD",
"total": number, "currency": str, "line_items": [{"desc": str, "amount": number}]}
Rules: output ONLY the JSON object, no prose. Dates as ISO. If a field is
missing use null. Numbers must be numeric, not strings.
EXAMPLE 1: <600 tokens of example invoice + expected JSON>
EXAMPLE 2: <600 tokens of example invoice + expected JSON>
EXAMPLE 3: <600 tokens of example invoice + expected JSON>
"""
# Per request: ~2000 prompt tokens of instructions+examples, every time.
# Failure mode: on a weird layout it sometimes emits prose around the JSON,
# or stringifies a number, or hallucinates a field - a few percent of the time.After fine-tuning on a few hundred clean invoice→JSON pairs, the shape is the model's default, so the per-request prompt collapses:
# FINE-TUNED: the shape is in the weights; the per-request prompt is tiny
SYSTEM = "Extract invoice fields as JSON." # ~6 tokens
# Per request: ~6 prompt tokens. The model emits the right schema by default.
# What you bought: ~2000 fewer prompt tokens per call, higher format
# reliability, and the option to run this on a smaller cheaper model.The training examples that produced this teach the schema, never the values of any particular invoice as ground truth about the world:
{"messages": [
{"role": "system", "content": "Extract invoice fields as JSON."},
{"role": "user", "content": "INVOICE\nNorthwind Traders\n#NW-2231 03/14/2026\nWidgets x4 ........ $48.00\nShipping ......... $7.00\nTOTAL USD 55.00"},
{"role": "assistant", "content": "{\"vendor\":\"Northwind Traders\",\"invoice_no\":\"NW-2231\",\"date\":\"2026-03-14\",\"total\":55.00,\"currency\":\"USD\",\"line_items\":[{\"desc\":\"Widgets x4\",\"amount\":48.00},{\"desc\":\"Shipping\",\"amount\":7.00}]}"}
]}The model is learning "produce this schema, normalize dates to ISO, keep numbers numeric, emit no prose", a behavior, by example. It is not learning "Northwind Traders charged $55" as a fact; that value is incidental and varies across examples, so it never becomes a stuck belief. This is the discipline from Chapter 2 applied to data: the pervasive pattern (the schema) is reinforced by every example and sticks; the incidental facts (the specific amounts) vary and wash out. Teaching shape with varied content is the whole craft (see OpenAI fine-tuning best practices for data-format guidance).
Structured outputs vs. fine-tuning for format
A fair objection: if you only need valid JSON, structured-output constraints (JSON mode, grammar-constrained decoding, tool schemas) guarantee valid JSON at decode time without any training. True, and you should use them, they are rung 2 on the ladder and strictly more reliable than a trained tendency for the narrow goal of syntactic validity. The reason to fine-tune as well or instead is when the hard part is not the syntax but the semantics and the prompt cost: extracting the right values, normalizing them correctly, handling messy layouts, choosing the right label, and doing it without a 2000-token instruction block on every call. Constraints make the output well-formed; fine-tuning makes it correct and cheap. The mature pattern is often both: fine-tune for the extraction behavior, and apply a schema constraint so the output is guaranteed parseable even on the rare input the model would otherwise fumble. They are complementary, not competing.
The task-stability scorecard
Before committing to train a task, score it. This converts the fuzzy "is this a good fine-tuning candidate?" into a checklist you can take to a decision meeting.
| Dimension | Question | Green (train) | Red (don't) |
|---|---|---|---|
| Stability | How often does the correct output for a fixed input change? | Rarely, human timescale | Weekly / sprint-ly |
| Volume | How many requests per month? | High enough to amortize | Low; prompt is cheaper |
| Task-ness | Strip facts/state, is there a well-defined output left? | Yes, a shape/decision | No; it was knowledge/state |
| Pattern consistency | Do the right answers follow a consistent procedure? | Yes | Answers are ad hoc |
| Data availability | Do you have clean, consistent examples? | Yes (or can curate) | Only messy/contradictory |
| Prompting ceiling | Has prompting + few-shot + constraints plateaued below bar? | Yes | Not tried / still improving |
A task that is green on all six is a textbook fine-tune. A red on stability or task-ness should stop you cold, those are the dimensions that, if violated, make the fine-tune actively harmful (a treadmill or a frozen-fact disaster). A red on data availability or prompting ceiling means "not yet" rather than "never", fix the data or finish exhausting the cheaper tools, then re-score. This scorecard is the positive complement to Chapter 3's differential: there, we ruled out false cases; here, we confirm a real one.
A historical note grounds the optimism. The instruction-following revolution, InstructGPT, then the open reproductions like Stanford Alpaca trained on Self-Instruct-style data, was fundamentally a behavior fine-tune at scale: teaching models the stable, repeated, pattern-shaped task of "follow an instruction and respond helpfully." Alpaca showed that a modest set of instruction-following demonstrations could substantially shift a base model's behavior. That is the same mechanism you are using when you fine-tune invoice extraction; you are just narrowing the task from "follow any instruction" to "extract this schema." The technique that gave us helpful assistants is the technique that gives you a reliable extractor. It works because, in both cases, the target is a pervasive behavior, not a pile of facts.
Chapter summary
Fine-tuning genuinely shines on the stable repeated task: the same kind of input arrives at high volume, you want the same structurally-shaped output every time, and "the same output" is a format, field set, length, or decision boundary rather than a fact. Such a task pays in three currencies: reliability (the shape becomes the default, not an instruction that drifts), shorter prompts (delete the instructions and few-shot once the shape is in the weights), and cost (shorter prompts plus the option of a smaller specialized model). All three words must hold: stable (the target doesn't change faster than you can retrain, violating this builds a treadmill), repeated (volume high enough to amortize the fixed costs), and task (strip facts and state, and a well-defined output remains, otherwise it was knowledge or state wearing a task's clothes). Genuine examples span support triage, legal clause classification, medical summarization with mandatory disclaimers, JSON extraction, and code-review classification; in each, the value is the consistency of the shape, while any facts still come from retrieval, tools, or review. Training examples must teach the schema with varied content so the pattern sticks and the incidental facts wash out. Structured-output constraints guarantee syntactic validity and should be used alongside fine-tuning, which contributes semantic correctness and prompt-cost savings. A six-dimension scorecard (stability, volume, task-ness, pattern consistency, data availability, prompting ceiling) confirms a real case, with reds on stability or task-ness as hard stops. The instruction-tuning lineage, InstructGPT, Alpaca, Self-Instruct, is proof of concept: it is the same behavior-fine-tuning mechanism, just narrowed from "follow any instruction" to "produce this shape."