Preference Tuning, DPO, and Distillation
> **Working claim:** When the target has no single right answer but a clear better-and-worse, demonstrations are the wrong tool and preference tuning is the right one.

Working claim: When the target has no single right answer but a clear better-and-worse, demonstrations are the wrong tool and preference tuning is the right one. DPO made preference tuning simple enough that product teams can use it without an RL pipeline. But preference tuning amplifies whatever your preference data prefers, including biases, sycophancy, and the judge model's blind spots, so the discipline shifts from "is the answer correct?" to "is the preference signal trustworthy?"
Key Takeaways
- Preference tuning fits problems where there is no single correct output but clear better and worse.
- DPO removes the separate reward-model and RL loop from many preference-tuning workflows.
- Distillation should be evaluated against ground truth, not only agreement with the teacher.
When "the right answer" is the wrong frame
Most of this book has assumed a task with a right answer, extract this field, apply this label, produce this shape. A large class of real problems does not have one."Write a more helpful reply." "Refuse this harmful request without being preachy." "Make the summary more useful to a clinician." "Sound more on-brand." For these, there is no single correct output you can demonstrate; there are better and worse outputs, and the thing you want to teach is the direction of better. Demonstrations cannot express a direction, they can only assert "this exact output is correct," which, as Chapter 8 argued, over-constrains a comparative property and teaches imitation of phrasings rather than the quality you care about.
Preference tuning teaches the direction. You collect pairs: the same input, two responses, and a judgment that one is preferred. The model learns to make preferred-style outputs more likely and dispreferred-style outputs less likely. This is how the helpfulness and harmlessness of modern assistants were instilled: InstructGPT used human preference rankings to train a reward model and then optimized the policy against it (RLHF), precisely because "helpful" is comparative and could not be demonstrated as a single correct answer. Preference tuning is the method for the better-answer problems that demonstrations cannot reach.
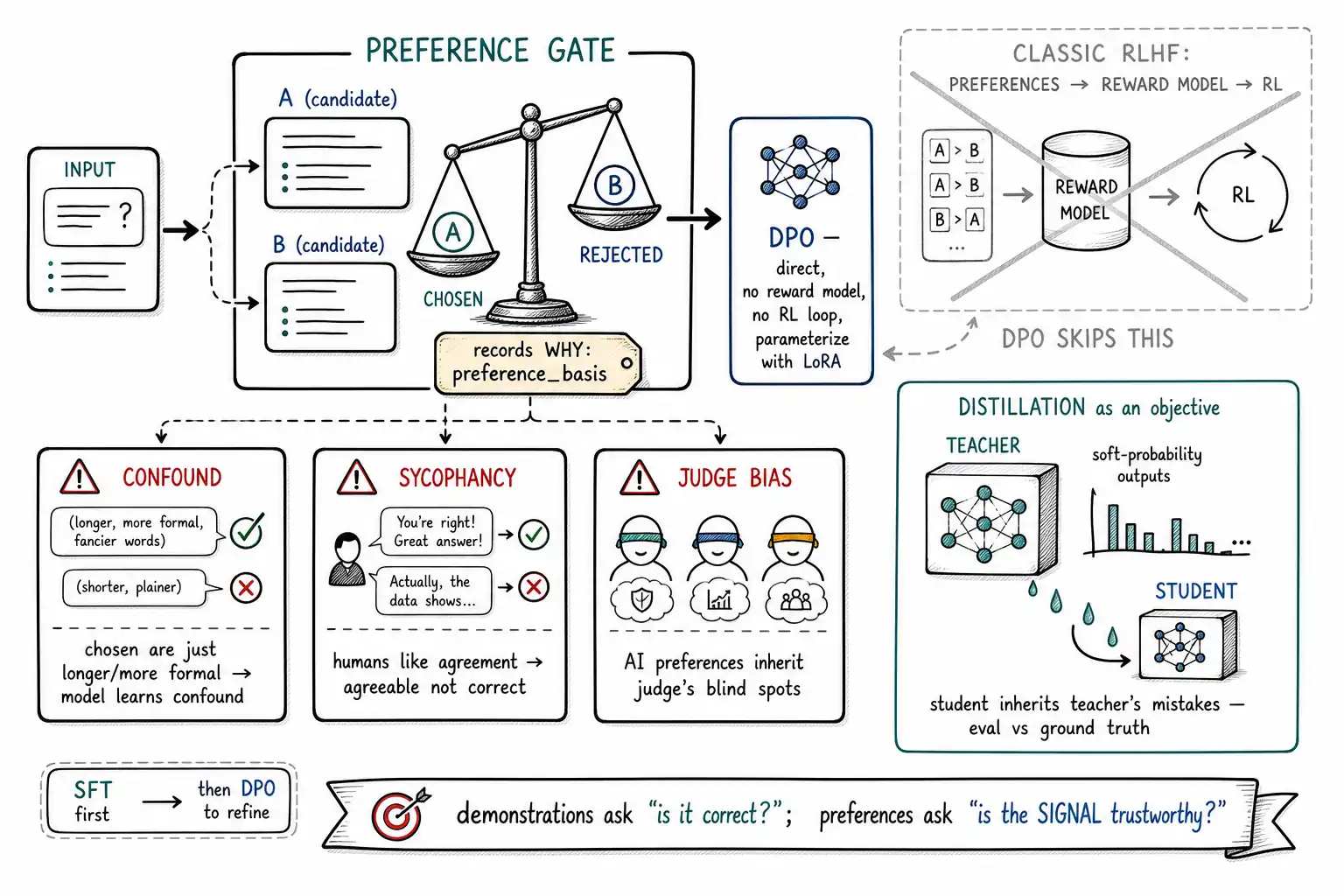
RLHF, then DPO: why the simplification matters
Classic RLHF, as in InstructGPT, is a three-stage pipeline: collect human preferences, train a reward model to predict them, then use reinforcement learning to optimize the language model against that reward. It works, and it is how the first aligned assistants were built, but it is operationally heavy, an RL training loop, a separate reward model, reward hacking to guard against, and instability to manage. For most product teams, standing up an RL pipeline to nudge a model's tone was out of reach.
Direct Preference Optimization is the simplification that brought preference tuning within reach of ordinary teams. DPO's insight is that you can skip the separate reward model and the RL loop entirely: the preference data can be used to optimize the language model directly with a simple classification-style loss that increases the relative likelihood of preferred responses over dispreferred ones. It is, operationally, much closer to supervised fine-tuning than to reinforcement learning, you have a dataset of preference pairs, you run a training loop that looks like SFT, and you get a preference-tuned model, without the reward model or the RL machinery. DPO can be parameterized with LoRA/QLoRA (Chapter 12) just like SFT, so a preference fine-tune is now within the same operational envelope as a demonstration fine-tune. This is why preference tuning has moved from "research lab" to "product team": DPO removed the pipeline that used to gate it.
// A DPO-style preference pair. Same prompt, a CHOSEN and a REJECTED response,
// and the preference is the training signal - not the absolute correctness of either.
{
"prompt": "A customer is angry their refund hasn't arrived. Reply.",
"chosen": "I'm sorry - that's frustrating. I can see your refund was issued and should land within 3 business days. If it hasn't by then, reply here and I'll escalate it personally.",
"rejected": "Refunds take 3-5 business days. Please wait.",
"preference_source": "human:senior_support_lead",
"preference_basis": "acknowledges emotion, gives concrete next step, offers ownership"
}Note preference_basis: a good preference dataset records why one response beat the other, because that rationale is what lets you audit whether your preferences are teaching the quality you intend or some confound (the chosen response is longer, or more formal, or just happens to mention the brand) that the model will latch onto instead.
Preference tuning amplifies the preferences
Here is the danger that makes preference tuning a surgery and not a seasoning. The model learns to produce whatever your preference data prefers, faithfully, including the things you did not mean to prefer. Three failure modes recur.
Confound learning. If your preferred responses are systematically longer, the model learns "longer is better" rather than the quality you intended; if they are systematically more deferential, it learns sycophancy. The model cannot read your mind about why you preferred a response; it learns the statistical difference between chosen and rejected, and if that difference is dominated by a confound (length, formality, hedging, flattery), it learns the confound. The defense is to balance the confounds: ensure your chosen and rejected responses do not differ systematically on dimensions you do not care about, so the only signal left is the quality you intend.
Sycophancy and reward hacking. Preference data collected from humans rewards responses that humans like, and humans like being agreed with, flattered, and told what they want to hear. Unchecked, preference tuning can teach a model to be agreeable rather than correct, to validate a user's wrong belief because validation reads as "helpful." This is a documented hazard of preference-based training, and the defense is preference data that explicitly prefers honest over agreeable on the cases where they conflict, plus evals that test for sycophancy directly.
Judge-model bias. When preferences come from an AI judge rather than humans (cheaper, scalable), the model learns the judge's preferences, biases, and blind spots. Constitutional AI made AI-generated preferences usable by grounding them in explicit written principles and a critique-revise loop, structure that constrained what the judge could prefer. Without that structure, AI preferences are the distillation hazard (Chapter 11) in preference form: you are copying a model's judgment, including where its judgment is wrong, and you must spot-check AI preferences against human judgment on the high-stakes slices. The rule from Chapter 11 applies unchanged: a preference is a candidate until something trustworthy verifies it.
The shift in discipline is the chapter's core point. With demonstrations, you ask "is this answer correct?" With preferences, the answer's correctness is not even the frame, you ask "is this preference signal trustworthy, and is it teaching the dimension I intend rather than a confound?" Preference tuning is more powerful than demonstration tuning for comparative qualities and correspondingly more dangerous, because the thing it amplifies is a judgment, and judgments carry bias that correct answers do not.
Distillation as a fine-tuning objective
Distillation (introduced in Chapter 7 as a cost play) is worth placing here among the objectives, because it is a third kind of training signal alongside demonstrations and preferences: the signal is a teacher model's behavior. Hinton, Vinyals, and Dean framed it as transferring the knowledge of a large model (or ensemble) into a small deployable one by training the student on the teacher's outputs: and crucially on the teacher's soft output distribution, which carries more information than hard labels (the teacher's "this is 70% a refund, 25% a complaint, 5% a question" tells the student about the similarity structure between classes, not just the winning label).
In LLM practice, distillation takes a few forms, and the form determines what you can do:
| Distillation form | What the student trains on | Available when |
|---|---|---|
| Hard-label / response | The teacher's generated text outputs | Always (just generate from the teacher) |
| Soft-label / logit | The teacher's full token probability distribution | The teacher API exposes logits/logprobs |
| Rationale / CoT | The teacher's reasoning traces, not just answers | You can prompt the teacher to show work |
Response distillation is the common product case: run the strong model, collect its outputs, fine-tune the small model (with SFT) to reproduce them. It is operationally just SFT where the labels came from a teacher instead of a human, which is exactly why it carries the SFT-on-synthetic-data hazards of Chapter 11: the student inherits the teacher's mistakes, so you evaluate the student against ground truth, not against agreement with the teacher, and you verify on the slices where the teacher is weak. Soft-label distillation, where available, transfers more and often produces a better student per example, but most hosted APIs limit logit access, so response distillation is what most teams actually do. DPO and distillation both parameterize cleanly with QLoRA, so all three objectives, SFT, DPO, distillation, share the same efficient training machinery; the choice among them is about what signal you have, not how you train.
Choosing the objective
The three objectives map to three situations, and choosing wrongly wastes a data-collection effort:
- You have correct answers to show → SFT on demonstrations (Chapter 8, 12).
- You have judgments of better-vs-worse → DPO on preferences (this chapter).
- You have a strong model whose behavior you want cheaply → distillation (this chapter, Chapter 7).
The objectives also compose in sequence, the way the aligned-assistant recipe does: SFT first to install the basic behavior and format, then preference tuning to refine the comparative qualities (helpfulness, tone, safety) that demonstrations could not express. InstructGPT and the alignment lineage follow exactly this order, supervised fine-tuning to teach the shape of good responses, then preference optimization to teach which good responses are better. For a product team, the practical version is: get the behavior right with SFT and a clean dataset, ship it, and reach for DPO only when you have a comparative quality (usually tone, helpfulness, or safety) that SFT plateaued on and that you can collect trustworthy preference pairs for. Preference tuning is a refinement on top of a working behavior, not a starting point, starting with preferences on a task that needed demonstrations is the category error of Chapter 8, and it is expensive to discover after you have collected the wrong kind of data.
Chapter summary
When the target has no single right answer but a clear better-and-worse, helpfulness, tone, safe refusals, on-brand phrasing, demonstrations over-constrain the comparative property, and preference tuning is the right tool: collect pairs (same input, chosen vs. rejected) and teach the direction of better, the way RLHF instilled helpfulness in InstructGPT. DPO is the simplification that brought this within product-team reach: it skips the separate reward model and RL loop, optimizing the model directly with an SFT-like loss, and it parameterizes with LoRA/QLoRA, so a preference fine-tune now lives in the same operational envelope as a demonstration fine-tune. But preference tuning amplifies whatever the data prefers, including three things you did not mean to: confounds (chosen responses that merely happen to be longer or more formal teach length or formality), sycophancy (humans reward agreement, producing agreeable-not-correct models), and judge bias (AI preferences inherit the judge's blind spots unless grounded like Constitutional AI). So the discipline shifts from "is the answer correct?" to "is the preference signal trustworthy, and is it teaching the dimension I intend?", record preference_basis, balance confounds, prefer honest over agreeable, and spot-check AI preferences against humans. Distillation is a third objective whose signal is a teacher's behavior (per Hinton et al., with soft labels carrying more than hard ones); response distillation is operationally SFT with teacher-generated labels and carries the inherit-the-teacher's-mistakes hazard, so evaluate the student against ground truth. The three objectives, SFT (correct answers), DPO (better-vs-worse), distillation (copy a strong model cheaply), map to what signal you have, share the same efficient training machinery, and compose in sequence: SFT to install behavior, then DPO to refine comparative qualities it plateaued on.