Introduction: The Wrong Operation, Performed Well
A team I will call the support team, the details are composited from several real projects, but the shape is exact, had a problem that sounded like a fine-tuning problem. They ran tier-one customer support for a fast-moving SaaS product.

Research spine: this chapter stays grounded in OpenAI: Model optimization guide and OpenAI: Supervised fine-tuning, then applies that evidence to the operating judgment in the book. A team I will call the support team, the details are composited from several real projects, but the shape is exact, had a problem that sounded like a fine-tuning problem. They ran tier-one customer support for a fast-moving SaaS product. The model behind their assistant gave answers that were inconsistent in tone, occasionally too long, sometimes formatted as prose when the product wanted a crisp numbered list, and every so often it answered a billing question with the cheerful confidence of someone who had never read the billing policy. Leadership wanted the assistant to "sound like us" and to "know our product." A senior engineer summarized the consensus in a planning meeting in four words: "We should fine-tune it."
So they did. They had three years of resolved support tickets, tens of thousands of them, agent replies paired with the customer questions that prompted them. It was, on paper, a beautiful dataset: real questions, real answers, the house voice baked in. They formatted the tickets into chat-style training examples, ran a supervised fine-tune, evaluated it on a held-out slice of old tickets, and watched the numbers improve. The fine-tuned model matched the agents' tone. It produced the numbered lists. It used the product's internal vocabulary correctly. On the held-out tickets, it was measurably better than the base model with their old prompt. They shipped it. The mistake rhymes with why most RAG pipelines fail in month three: a clean demo masked a system that had not been evaluated against the failure mode that mattered.
Within three weeks, the escalation queue told a different story. The model was confidently, specifically wrong about the product, and not at the margins. It told customers about a pricing tier that had been renamed six months earlier. It walked users through a settings page that had been redesigned. It cited a refund window that the policy team had shortened in the last quarter. Every one of these answers was delivered in the perfect house voice, in a clean numbered list, with the exact internal vocabulary the team had wanted. The fine-tune had succeeded at everything it was asked to do. The problem was that it had been asked to do the wrong thing.
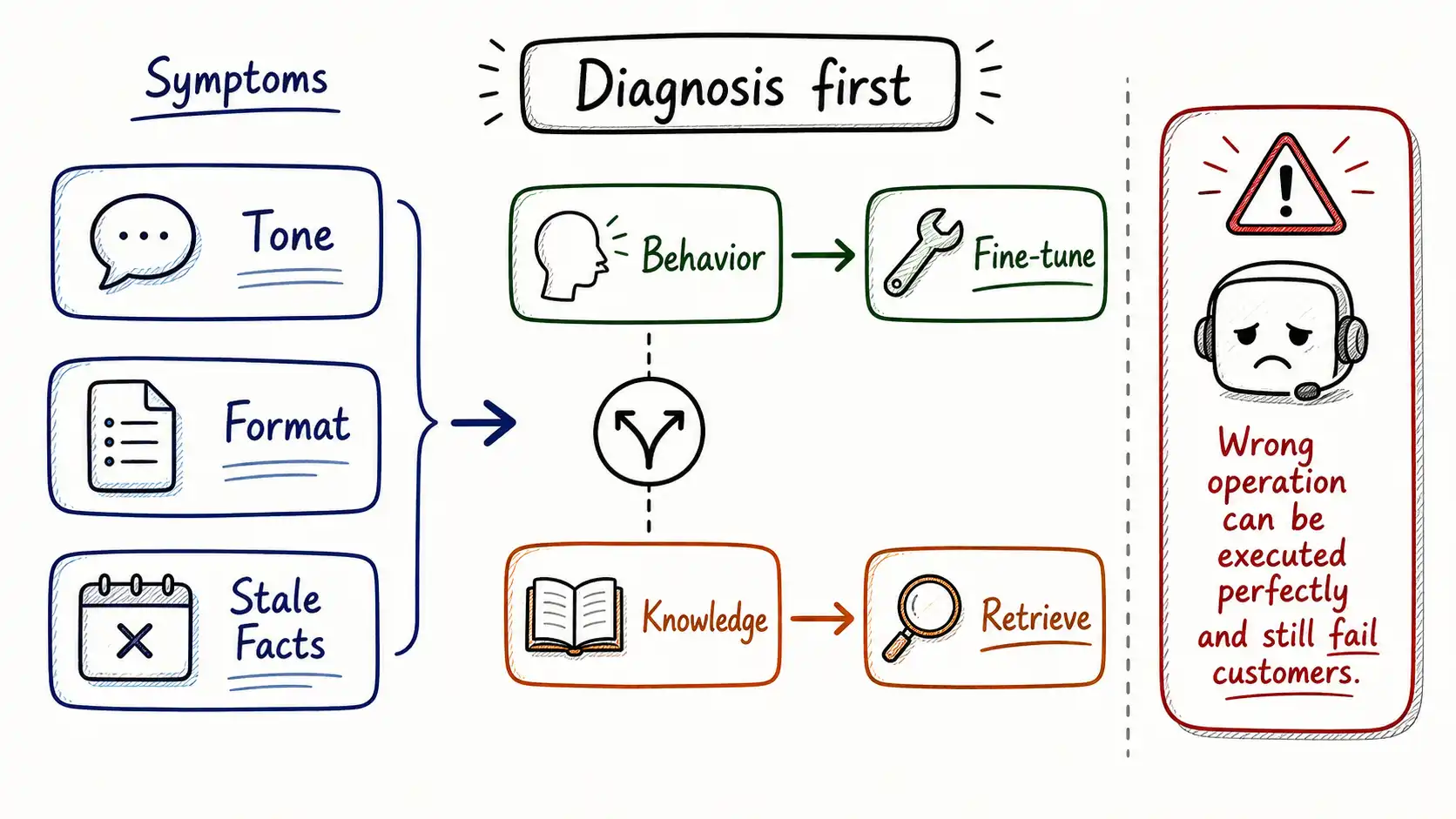
Here is the diagnosis the team eventually reached, and it is the seed of this entire book. They had three distinct complaints, inconsistent tone, wrong format, and outdated answers, and they treated all three as one problem with one solution. But tone and format are behavior. Behavior lives in the weights, and fine-tuning is exactly the right tool to change it; those two complaints were genuinely fixed. Outdated answers are not a behavior problem. They are a knowledge problem, and the knowledge that made the old tickets wrong was the product itself, which had changed after the tickets were written. By training on three-year-old tickets, the team had not taught the model the product. They had taught it the product as it existed three years ago, and then frozen that snapshot into the weights, where it would now be recited fluently and forever, until someone retrained.
Worse: the fine-tune made the knowledge problem harder to fix. Before, when the assistant gave a stale answer, you could update a retrieved document or a system prompt and the next request would be correct. Now the staleness was distributed across billions of parameters. You could not edit it. You could only retrain, collect fresh data, run another job, re-evaluate, re-deploy, and in the meantime the model would keep confidently reciting the old world. The team had reached for surgery when they needed, in part, a prescription they could change weekly. The surgery was performed flawlessly. It was the wrong operation.
Key Takeaways
- The support-bot failure came from training style and product facts together.
- Fine-tuning improved tone and format while freezing stale knowledge into model behavior.
- The rest of the book separates behavior from knowledge before any training decision.
Why this confusion is so easy to fall into
This is not a story about a careless team. It is a story about a real and powerful capability arriving faster than the vocabulary to reason about it."Fine-tune it" has become the reflexive answer to almost any model shortcoming, the way "add an index" is the reflexive answer to almost any slow query, sometimes exactly right, frequently a sign that nobody has asked what is actually slow.
The reflex is seductive for a specific reason: fine-tuning demos beautifully. Give a model a few hundred examples of the behavior you want and it will often produce that behavior convincingly within a day. The improvement is visible, the artifact is tangible (a model you own, a checkpoint with your name on it), and the narrative is satisfying, you took a generic model and made it yours. Every part of that experience encourages you to credit the fine-tune with capabilities it does not have. It changed the model's behavior, and you saw the behavior change, so it is easy to believe it changed the model's knowledge, its judgment, its currency. It did not. It changed the shape of the outputs, not the truth of them.
The deeper trap is that the vocabulary we use collapses distinct things into one word."Make it know our product" can mean recognize our domain phrasing (behavior, trainable) or recite our current pricing (knowledge, not trainable, retrieve it)."Make it follow our policy" can mean adopt our refusal style (behavior) or enforce this quarter's rules (policy, which changes, so route it through a system that can change too)."Make it more reliable" can mean stabilize the output format (a great fine-tune target) or stop hallucinating facts (mostly not a training problem, often a retrieval and grounding problem). When the words blur, the diagnosis blurs, and a blurred diagnosis sends you to the operating room for a problem that needed a prescription.
What this book argues
The argument has seven movements, and they build on each other.
The diagnosis comes first, because it is where the money is saved. We separate the things a fine-tune changes (behavior, format, style, skill, tool discipline, cost/latency through specialization) from the things it does not (current facts, business state, permissions, fast-changing policy, deletable private knowledge). We catalog the five false diagnoses that send teams to training when they need something else, it doesn't know, it needs our data, it's too verbose, it fails sometimes, it must be cheaper, and we lay out the full customization menu and a decision tree that routes a symptom to the cheapest intervention that can actually fix it. The discipline of this movement is refusal: most fine-tuning projects should die here, and that is a success.
The problems fine-tuning is good at come second, and this movement is deliberately positive. This is not an anti-fine-tuning book. There are problems for which training is the right and sometimes the only good answer: stable output formats, repeated task behavior, genuine house style, domain phrasing, classification and extraction patterns, tool-use conventions, prompt-length reduction in high-volume workflows, and specializing a small model so it is cheaper and faster than a large one. We show, with before-and-after examples, what these look like and how to recognize when you actually have one.
The data is the model update is the heart of the book. A fine-tune is its training data, compiled into weights. If the data is confused, the model is confused, confidently and permanently. We treat demonstrations, corrections, and preferences as different objects with different uses; we take labeler instructions and inter-annotator disagreement seriously; we insist on coverage of edge cases, negative and refusal examples, and balance; we build dataset manifests and validators; we take contamination and leakage as first-class threats; and we treat synthetic data as both a useful tool and a way to poison your own well, because both are true.
Methods without mystery comes fourth. We teach full fine-tuning, supervised fine-tuning, parameter-efficient methods (LoRA, adapters), quantized training (QLoRA), instruction tuning, preference tuning and DPO, RLHF at a conceptual level, and distillation, with enough depth to make decisions, not enough to write a deep-learning textbook. We also widen the lens past "fine-tune the generator" to fine-tuning retrievers and small routers, which is frequently the higher-impact move.
Evaluation is the spine of the book's practical value. A fine-tune you cannot evaluate against its alternatives is a fine-tune you cannot justify. We build baselines before training, task and regression and safety and format evals, slice-level analysis, the regression wall (the new model wins the target task and quietly breaks three others), the limits of LLM-as-judge, and the release gate that a model must pass before it touches users, shadow, canary, rollback.
Operating fine-tuned models is the part most tutorials skip. Training is the beginning of the operational burden, not the end. We cover versioning, dataset lineage, reproducibility, drift monitoring, retraining triggers, retirement, what happens to a fine-tune when policy changes or a user demands deletion, vendor lock-in, cost accounting, and running fine-tuning and retrieval in the same system without either one fighting the other.
Use case playbooks close the book. Ten concrete situations, support, extraction, triage, internal code assistant, legal/policy, medical summarization, brand voice, knowledge base, agent tool discipline, cost reduction, each with the same hard questions: when to fine-tune, when not to, what data you need, what eval you need, and what goes wrong. These are written to be opened in a decision meeting.
How to read this book
It is written to be read in order, because the movements build, but it is also written so that an engineer in the middle of a specific decision can open to the relevant chapter and find a usable artifact: a decision table, a data validator, a config, an eval runner, a model card, a playbook. The code is deliberately about training operations and evaluation infrastructure, JSONL validation, split discipline, PEFT configs, eval harnesses, release gates, model registry metadata, cost models, and not about generic chat completion plumbing. Every example is chosen to demonstrate a fine-tuning decision, because that is the whole point.
Throughout, the tone is skeptical without being cynical. Fine-tuning is a genuine and sometimes irreplaceable tool. Parameter-efficient methods have made it cheap enough that the old "you need a GPU cluster" objection is gone. The skepticism is aimed not at the capability but at the reflex, the belief that a model problem is a training problem, that more data is more knowledge, that a checkpoint you own is a checkpoint you understand. None of those are true, and building as if they were is how teams perform the wrong operation, well.
The support team's fine-tune was a technical success and a product failure. It is the difference between those two sentences that the rest of this book is about. Turn the page. There is a model on the table, the lamp is bright, the instruments are laid out, and the first job, before anyone touches a scalpel, is the diagnosis.