Demonstrations, Corrections, and Preferences
> **Working claim:** A fine-tuning dataset is the model update, compiled.

Working claim: A fine-tuning dataset is the model update, compiled. Three kinds of training signal, demonstrations, corrections, and preferences, answer three different questions and feed three different methods, and using the wrong kind for your problem is a category error that no amount of tuning fixes. Before you collect a single example, decide which signal your problem needs, because that decision determines everything downstream.
Key Takeaways
- A fine-tuning dataset is the model update, compiled.
- Demonstrations, corrections, and preferences are different signals with different failure modes.
- Corrections are high-value examples because they come from failures the system already made.
The data is the model
There is a sentence worth carving over the door of every fine-tuning project: the fine-tune is the data. The training algorithm is nearly commoditized, SFT, LoRA, the configs in Chapter 12 are largely interchangeable knobs, and the base model is whatever you picked. What makes one fine-tune good and another a disaster is almost entirely the dataset. A clean, consistent, well-targeted dataset produces a clean model; a contradictory, contaminated, or mis-specified dataset produces a confidently broken one, and runs through the exact same algorithm with the exact same loss curve. You cannot inspect the weights to find the problem; you can only inspect the data, which is why this movement is four chapters and the methods movement is three. The OpenAI fine-tuning best practices put it bluntly: building a robust, representative dataset is essential, and it is where the results come from.
This chapter starts the movement by making a distinction that decides what data you even collect: the kind of training signal. There are three, they are not interchangeable, and most failed fine-tunes use the wrong one.
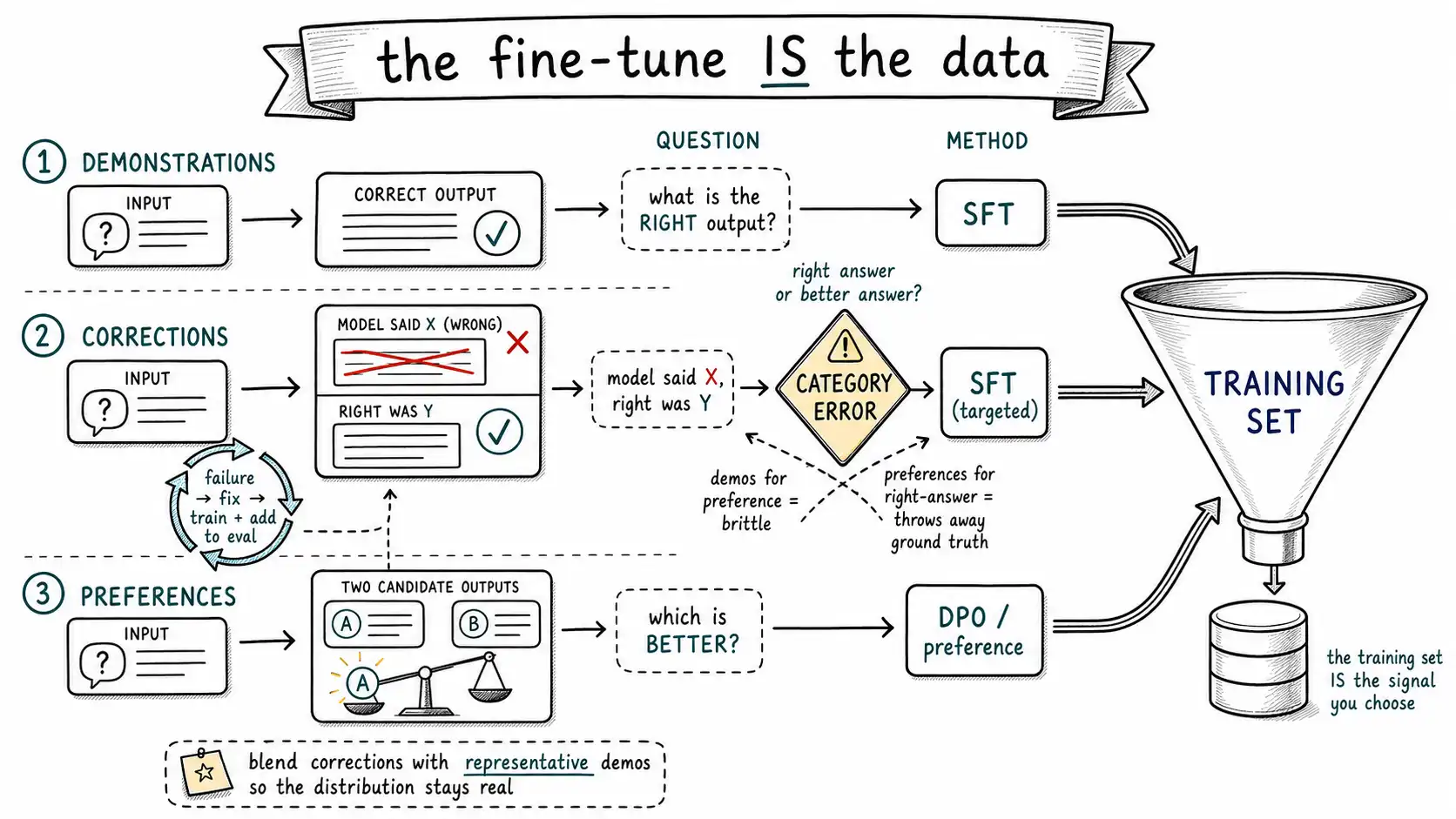
Three signals, three questions
Demonstrations answer "what is the right output for this input?" A demonstration is an input paired with the correct, complete output, the invoice and its JSON, the ticket and its category, the question and the ideal answer. It is the signal for supervised fine-tuning (Chapter 12), and it is what you reach for when there is a right answer you can show. Demonstrations teach the model to imitate: produce this given that. They are the workhorse of behavior fine-tuning and the right signal for most of the tasks in Movement II.
Corrections answer "the model did X; the right output was Y." A correction is a demonstration with a history, it captures a specific failure and its fix. Operationally a correction often becomes a demonstration (you train on the corrected output Y), but treating corrections as a distinct category matters because they are targeted: they come from real production failures, they cover the exact cases the model gets wrong, and they are the highest-value examples per row because they sit precisely where the model needs to change. A dataset built from corrections is a dataset aimed at your actual error distribution rather than at the average case.
Preferences answer "between these two outputs, which is better?" A preference is an input with two or more candidate responses and a judgment about which is preferred, not "what is correct" but "which is better." This is the signal for preference tuning and Direct Preference Optimization, and it is what you reach for when there is no single right answer but there is a clear better and worse: a more helpful phrasing, a safer refusal, a more on-brand tone, a more concise summary. Preferences are how InstructGPT and RLHF taught models to be helpful and harmless, because "be helpful" has no single demonstrable right answer, but humans can reliably say which of two responses is more helpful.
The three map cleanly onto when to use each:
| Signal | Question it answers | Use when | Feeds |
|---|---|---|---|
| Demonstration | What is the right output? | There is a correct, showable answer | SFT (Ch. 12) |
| Correction | The model said X; right was Y | You have real production failures to fix | SFT (targeted) |
| Preference | Which output is better? | No single right answer, but clear better/worse | DPO / preference tuning (Ch. 13) |
The category error
The most common dataset mistake at the kind level is using demonstrations for a preference problem, or preferences for a demonstration problem. They fail in opposite, instructive ways.
Using demonstrations for a preference problem over-constrains the model. If the goal is "be more helpful and on-brand," and you collect demonstrations of the one helpful on-brand answer to each input, you are teaching the model that there is exactly one acceptable response per input, which is false and brittle. The model learns to imitate your specific phrasings rather than to internalize the quality dimension you actually care about, and it generalizes poorly to inputs you did not demonstrate. Helpfulness is a comparative property; freezing it into single "correct" demonstrations loses the comparison that defines it. This is precisely why RLHF and DPO exist: for properties that are relative, you teach the relation, not a point.
Using preferences for a demonstration problem under-constrains the model. If the task has a right answer, extract this field, apply this label, and you collect preference pairs ("output A is better than output B") instead of demonstrations of the correct output, you are throwing away the ground truth you have. You know the answer; show it. Preference tuning on a task with a correct answer is a roundabout, weaker way to teach something you could state directly, and it can leave the model preferring the "better" of two wrong answers. When you have ground truth, demonstrate it.
The decision is upstream of all data collection: does my problem have a right answer, or a better answer? Right answer → demonstrations (and corrections). Better answer → preferences. Get this wrong and you will collect thousands of expensive, carefully labeled examples of the wrong kind, and the fine-tune will fail in a way no hyperparameter rescues.
Anatomy of a good demonstration
Most fine-tunes use demonstrations, so it is worth being precise about what a good one looks like, beyond "input and output." The format is the chat-message schema:
{"messages": [
{"role": "system", "content": "Classify the support ticket into exactly one category."},
{"role": "user", "content": "I was charged twice for my subscription this month and want a refund for the duplicate."},
{"role": "assistant", "content": "{\"category\": \"billing_dispute\", \"priority\": \"high\", \"refund_requested\": true}"}
]}A good demonstration has properties that a naive one lacks, and each property prevents a specific failure:
- The output is exactly what you want at inference time: same format, same length discipline, same structure. The model imitates what it sees; if your demonstration includes a chatty preamble you do not want in production, you are training the preamble in.
- The input resembles real production inputs: same messiness, same distribution. Demonstrations written by your team in clean prose teach the model to handle clean prose, then it meets a real ticket full of typos and forwarded email cruft and fails. Train on the inputs you will actually see.
- It is internally consistent with every other demonstration: the same input pattern maps to the same output pattern across the whole dataset. Inconsistency is the most damaging dataset property and the subject of the next chapter; here it suffices to say that two demonstrations that disagree about how to handle the same case teach the model to be confused about that case.
- It does not leak current facts as ground truth: the Chapter 1 discipline. The assistant output above classifies; it does not assert a refund amount or a policy, which would be facts to retrieve.
Corrections: mining the error distribution
Corrections deserve their own emphasis because they are the highest-impact demonstrations and the most natural source of new training data once a model is live. A correction is born when the system gets something wrong, a human (a reviewer, an agent, the user) fixes it, and you capture both the wrong output and the right one. Two disciplines make corrections valuable.
First, train on the fix, but keep the failure for evaluation. The corrected output becomes a demonstration you train on; the original failure becomes a test case you add to the regression suite (Chapter 15), so the next model is verified to no longer make that mistake. Corrections thus feed both halves of the loop, they improve the training set and harden the eval set, which is why a mature fine-tuning operation is a correction flywheel: production failures become corrections, corrections become training data and eval cases, the next model is better and verified, and its new failures feed the next round.
-- A corrections table: the substrate of the flywheel
CREATE TABLE corrections (
correction_id TEXT PRIMARY KEY,
input TEXT NOT NULL, -- the production input
model_output TEXT NOT NULL, -- what the model said (the failure)
corrected_output TEXT NOT NULL, -- what it should have said
corrected_by TEXT NOT NULL, -- reviewer / agent / user
failure_cluster TEXT, -- which error class (Ch. 3 clustering)
use_for_training BOOLEAN DEFAULT TRUE, -- some corrections are too rare/odd to train
use_for_eval BOOLEAN DEFAULT TRUE, -- nearly all belong in the regression suite
created_at TIMESTAMPTZ NOT NULL
);Second, do not let corrections overwhelm the distribution. Corrections concentrate on failures, so a dataset built only from corrections over-represents the hard cases and can teach the model that the rare hard case is common, degrading it on the easy majority. Blend corrections with representative demonstrations so the training distribution still resembles production. Corrections aim the fine-tune at the errors; representative demonstrations keep it calibrated to reality. You need both.
Preferences and the limits of demonstration
When the problem genuinely has no single right answer, preferences are the signal, and a subtlety from the alignment literature is worth carrying forward to Chapter 13. Preferences can come from humans (expensive, high-quality) or from AI judges. Constitutional AI showed you can generate preference signal from a model critiquing its own outputs against a set of written principles, reducing the human labeling burden. This is powerful and dangerous in the same way distillation is: AI-generated preferences inherit the judge model's biases and blind spots, so an AI-preference dataset must be spot-checked against human judgment, especially on the high-stakes slices. The Self-Instruct lineage applies the same idea to demonstrations, generate them with a model, filter aggressively, and carries the same caveat, which is the whole subject of Chapter 11. The point for now: whether your signal is demonstrations, corrections, or preferences, who or what produced it is a property you must record and govern, because the quality of the signal is the quality of the model.
Chapter summary
The fine-tune is the data, compiled: the algorithm is commoditized and the base is whatever you chose, so dataset quality decides whether a model is clean or confidently broken, and you debug it by inspecting the data, not the weights. The first dataset decision, upstream of collecting anything, is the kind of signal. Demonstrations answer "what is the right output?" and feed SFT: the workhorse for tasks with a showable correct answer. Corrections answer "the model said X, the right answer was Y," are the highest-value demonstrations because they target your actual error distribution, and they power a flywheel: production failures become both training data and regression cases. Preferences answer "which output is better?" and feed DPO/preference tuning, the signal for properties that are comparative (helpful, on-brand, safe) with no single right answer, the way RLHF taught helpfulness. The category error, demonstrations for a preference problem (over-constrains, brittle) or preferences for a right-answer problem (throws away ground truth), fails in opposite ways that no hyperparameter fixes, so decide first whether your problem has a right answer or a better answer. Good demonstrations match production output and input distributions, stay internally consistent, and never leak current facts. Corrections must be blended with representative demonstrations so the training distribution stays realistic. And whatever the signal, record who or what produced it, because AI-generated demonstrations and preferences inherit the producer's biases, the hazard Chapter 11 is about.