Ten Playbooks for the Decision Meeting
> **Working claim:** Everything in this book reduces to a decision a team makes in a room: *should we fine-tune this, and if so, how?* This chapter is ten such decisions, worked.

Working claim: Everything in this book reduces to a decision a team makes in a room: should we fine-tune this, and if so, how? This chapter is ten such decisions, worked. Each playbook answers the same five questions: when to fine-tune, when not to, what data, what eval, what goes wrong, so you can open to your situation and walk into the meeting with a defensible position instead of a reflex.
Key Takeaways
- Every playbook asks the same five questions: when to train, when not to, what data, what eval, what breaks.
- The train target is behavior; the do-not-train list is current facts, state, permissions, policy, and knowledge bases.
- The decision is never fine-tune or not in the abstract; it is what are we trying to change and can we prove it.
How to use these
Each playbook is a one-page argument you can take to a decision meeting. Read the when not to before the when to, the book's whole thesis is that the "don't" branch is more often correct, and reading it first keeps the reflex in check. The playbooks share a structure on purpose, but the answers differ sharply by case; the point is to show how the same five questions produce different verdicts depending on whether the target is behavior or knowledge, stable or shifting, high-stakes or low. Run each through TRAIN as you read: Task stability, Required knowledge, Available examples, Impact of mistakes, Necessary evaluation.
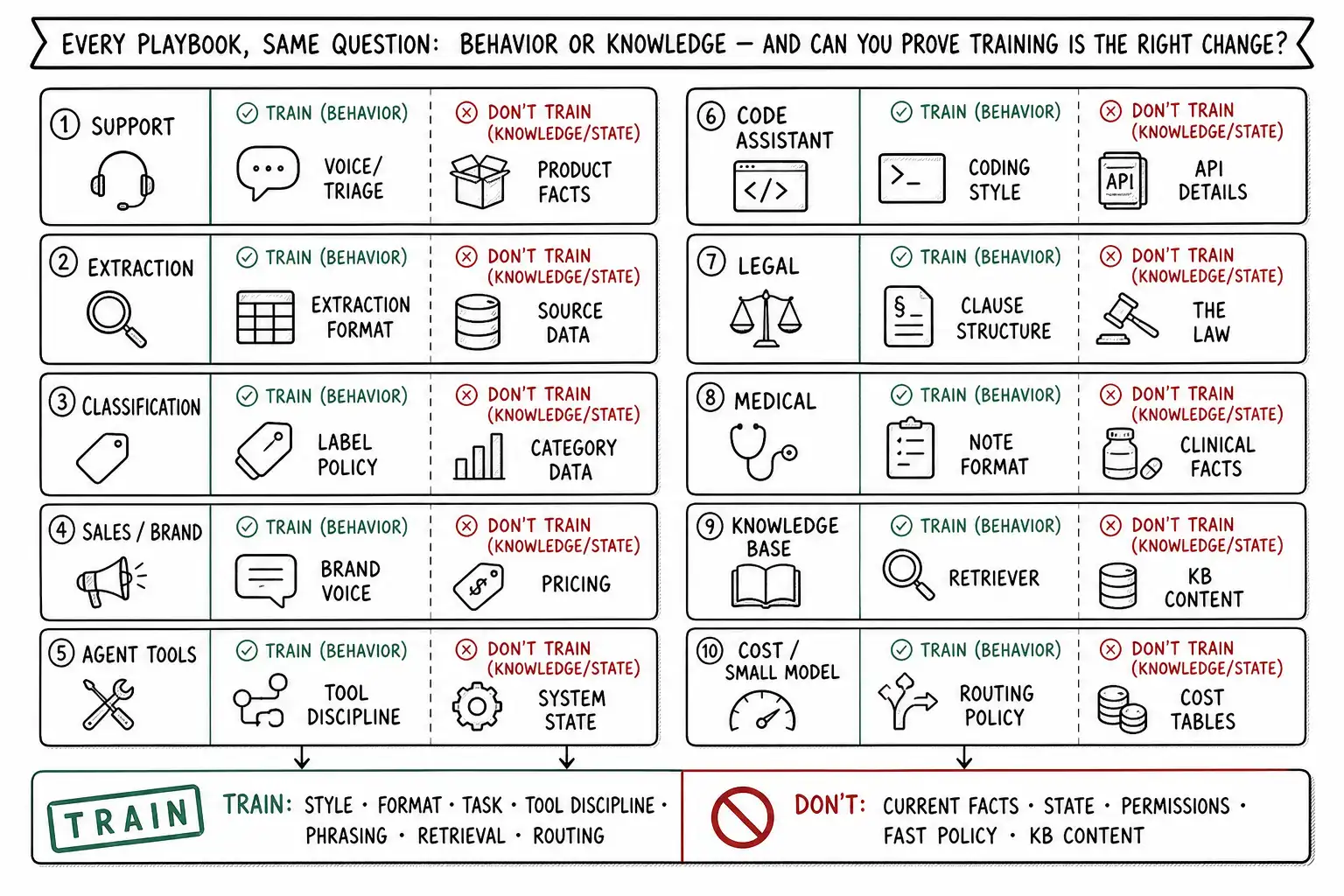
Playbook 1: Customer support assistant
When to fine-tune. For style and format: the house voice, the response structure, the disclosure/disclaimer discipline. For triage behavior: classifying and routing tickets consistently. These are pervasive, stable behaviors with mineable data.
When not to. For product knowledge, features, pricing, policies, account state. This is the book's opening incident: training product facts freezes a snapshot and recites it confidently after the product changes. Retrieve product knowledge; fetch account state with tools.
What data. Curated agent replies stripped of current facts (Chapter 6's slot pattern), triage labels with measured inter-annotator agreement (Chapter 9), and corrections from escalations (the flywheel, Chapter 8). Blend representative tickets with edge cases and refusals.
What eval. Task: triage accuracy and house-voice adherence (likely LLM-judge, validated against humans). Regression: general helpfulness and safety. Slice: by language, by issue type. Critical: a freshness eval that catches the model asserting stale facts, the failure that the demo missed.
What goes wrong. The model sounds perfect and is confidently out of date (training facts), or it over-triggers refunds/actions because the data lacked negatives. Fix with retrieval for facts, tools for actions, negatives in the data.
Playbook 2: Structured extraction (documents → JSON)
When to fine-tune. Strong case. Stable schema, high volume, messy inputs, format reliability is the whole value (Chapter 5). Often pairs with a small specialized model (Chapter 7) for cost.
When not to. If the schema changes every sprint (T fails, treadmill), or if structured-output constraints plus a good prompt already hit your accuracy bar (try rung 2 of the ladder first).
What data. Many varied real documents mapped to correct JSON, with the content varying so the schema is what sticks (Chapter 2). Heavy on the messy layouts that cause failures. Synthetic augmentation is safe here because outputs are schema-checkable (Chapter 11).
What eval. Field-level precision/recall (not just "valid JSON"), normalization correctness (dates, numbers), and a slice eval by document type and layout difficulty. A schema validator in the gate.
What goes wrong. High valid-JSON rate masking wrong values; the model confident on clean docs and failing on the long tail of weird layouts. Fix with field-level metrics and edge-case coverage.
Playbook 3: Classification and triage
When to fine-tune. Strong case when the taxonomy is stable and volume is high. A small fine-tuned classifier is cheap, fast, and often more consistent than a prompted large model. This is close to the cleanest fine-tune (Chapter 14's router is its cousin).
When not to. If inter-annotator agreement is low (Chapter 9), fix the taxonomy and labeler instructions first, because training on inconsistent labels teaches inconsistency. If the categories change frequently.
What data. Balanced across classes (watch the rare-class imbalance the validator flags), with contested items resolved, and an explicit out-of-scope/none class so the model can decline rather than force a wrong label.
What eval. Confusion matrix (which classes get confused with which), per-class precision/recall, and the out-of-scope detection rate. Macro-averaged metrics so rare classes are not drowned by common ones.
What goes wrong. The model collapses two genuinely-ambiguous categories (a taxonomy problem, not a model problem), or over-predicts the majority class. Fix in the data and taxonomy, confirmed by the confusion matrix.
Playbook 4: Internal code assistant
When to fine-tune. For house conventions and idioms: your codebase's patterns, your internal libraries' usage, your review style (Chapter 6's domain phrasing). For code-review comment classification (Chapter 5).
When not to. For current API signatures and codebase facts, these change every commit; retrieve them from the actual code and docs (RAG over the repo). A fine-tune that "knows" your API will recite deprecated signatures fluently.
What data. Code review threads, merged PRs that exemplify the conventions, internal-library usage examples, with the patterns as the target and specific function names treated as retrievable, not memorized.
What eval. Execution-based where possible (does generated code run and pass tests, ground truth, Chapter 11), convention adherence, and a regression eval on general coding ability (a narrow fine-tune can erode broad competence, Chapter 2).
What goes wrong. Fluent code using deprecated APIs (trained facts), or narrowing that hurts general coding. Fix with repo retrieval for APIs and regression evals for breadth.
Playbook 5: Legal / policy assistant
When to fine-tune. For clause classification and structured analysis behavior (Chapter 5) and domain phrasing (Chapter 6), recognizing clause types, applying a consistent analytical structure.
When not to. For the law and the policy themselves, statutes, regulations, the current contract terms. These change and carry high stakes; retrieve them and ground every claim. The NIST AI RMF risk posture demands traceability here that frozen weights cannot provide.
What data. Expert-labeled clause classifications with high agreement (legal labels are expensive and disagreement is high, invest in instructions and adjudication), structured analyses, and explicit refusal/escalation examples for out-of-scope legal questions.
What eval. Classification accuracy by clause type, faithfulness (every legal claim grounded in a retrieved source, RAGAS-style, Chapter 15), and a hard safety eval for unauthorized legal advice. High human-review weight.
What goes wrong. Confident, fluent, wrong legal statements, the domain-phrasing confidence trap (Chapter 6), maximally dangerous in law. Fix by grounding every claim and gating with human review; the fine-tune contributes structure, never authority.
Playbook 6: Medical / healthcare summarization
When to fine-tune. For summary structure and mandatory safety elements: a fixed clinical-note template, the non-negotiable disclaimer block (Chapter 5), consistent terminology (Chapter 6).
When not to. For medical facts and guidelines, dosages, interactions, current clinical guidance. Retrieve from authoritative sources; never freeze. The stakes make the freshness hazard unacceptable.
What data. De-identified notes (PII is a deletion and consent landmine, Chapter 16, strongly prefer not training on identifiable patient data) mapped to structured summaries, with the disclaimer always present so the model never learns to drop it.
What eval. Faithfulness (does the summary assert anything not in the source, hallucination is the cardinal sin here), disclaimer-presence rate (must be ~100%), terminology accuracy, and exhaustive human clinical review. Truthfulness evals (Chapter 15) weighted heavily.
What goes wrong. A hallucinated detail in a clinical summary, or a dropped disclaimer. Fix with faithfulness evals as a hard gate, disclaimer adherence as a protected axis, and human review, and treat PII as a reason to minimize what touches the weights at all.
Playbook 7: Sales / brand voice assistant
When to fine-tune. The clearest style case (Chapter 6): a specific, consequential, pervasive persuasive voice across high email volume. Often a good preference-tuning case (Chapter 13) because "more persuasive / more on-brand" is comparative, not a single right answer, collect DPO pairs of better-vs-worse rewrites.
When not to. For prospect-specific facts and offers, pricing, availability, the prospect's account. Slot those in from data; the voice is trained, the facts are filled.
What data. For SFT: brand-voice examples decontextualized of current offers. For DPO: pairs where a sales lead judged one rewrite better than another, with preference_basis recorded, and confounds balanced (Chapter 13), so the model learns persuasiveness, not just length or flattery.
What eval. Style adherence (LLM-judge validated against brand experts), a sycophancy/over-claiming check (preference tuning can teach the model to promise things it shouldn't), and a factual-grounding check on any claim about the product.
What goes wrong. A sycophantic, over-promising model (preference tuning amplified "agreeable") or one that bakes in last quarter's pricing. Fix with confound-balanced preferences, an honesty-over-agreeableness signal, and retrieval for offers.
Playbook 8: Internal knowledge base assistant
When to fine-tune. This is mostly a retrieval problem, and the highest-impact fine-tune is the retriever (Chapter 14), not the generator, train the embedding model on your query-document pairs with hard negatives so it finds the right internal doc.
When not to. Do not fine-tune the generator to "know" the knowledge base, that is the canonical knowledge-into-weights mistake, and the KB changes constantly. The generator's job is to answer from retrieved context; train its grounding behavior at most, never the content.
What data. For the retriever: (query, correct-doc, hard-negative-docs) mined from logs and corrections. For the generator (optional): grounded-answer demonstrations that show using retrieved context faithfully.
What eval. Retrieval recall@k (did the right doc get retrieved, usually the real bottleneck), faithfulness (answer grounded in context, RAGAS-style), and freshness (updated docs reflected immediately, which they will be because knowledge is retrieved not trained).
What goes wrong. Teams fine-tune the generator, see no improvement (because retrieval was the bottleneck), and conclude fine-tuning doesn't work. Fix by localizing the failure (Chapter 14), it's almost always the retriever.
Playbook 9: Agent tool-use discipline
When to fine-tune. Strong, under-used case (Chapter 6). Training disciplined tool use, right tool, right time, right arguments, and not calling tools when inappropriate, is exactly the trainable behavior Toolformer demonstrated, and it is pattern-shaped and stable.
When not to. For which specific tools exist and what they return, the tool registry and tool outputs are state/config, not behavior. The model learns the habit of calling tools well; the available tools are provided per request and results come from execution.
What data. Traces of correct tool use: conversations where the right tool was called with right arguments at the right time, conversations where a tool was correctly not called, and graceful-failure examples (tool errored, model escalated instead of fabricating).
What eval. Tool-call accuracy (right tool, right args), false-trigger rate (calling tools it shouldn't), and a critical fabrication-on-failure eval (when a tool fails, does the model invent an answer or escalate?). Plus end-to-end task success.
What goes wrong. A model that over-calls tools, calls them with wrong arguments, or, worst, fabricates a confident answer when a tool fails. Fix with negative and graceful-failure examples and the fabrication-on-failure eval.
Playbook 10: Cost reduction via a smaller specialized model
When to fine-tune. Strong case (Chapter 7) when a high-volume narrow task currently runs on an expensive generalist, an off-the-shelf small model is close but not quite, and you can prove the match on an eval. Specialize the small model; route the hard tail to the large one (Chapter 14's router).
When not to. If volume is low (fixed costs never amortize), if an off-the-shelf small model already passes (no training needed), if the small model can't reach the bar even after fine-tuning (genuine capability ceiling, keep the large model with routing), or if the task changes often.
What data. Distillation from the expensive model (Chapter 7, 13), its verified outputs become the student's training data, blended with real labeled examples and verified against ground truth (not against teacher agreement, Chapter 11).
What eval. The decisive eval is small-fine-tuned vs. large-generalist on the golden set, the specialization is justified only if quality matches at a real cost saving (the break-even of Chapter 7). Plus out-of-distribution behavior (specialists fail strangely on OOD inputs: validate inputs and route).
What goes wrong. A specialist that matches on common inputs but fails confidently and weirdly on the long tail it was narrowed away from. Fix with input validation, an escalation route to the generalist, and OOD evals.
The pattern across all ten
Read the ten together and the book's thesis is visible as a pattern. In every playbook, the fine-tune target is behavior, style, format, task structure, tool discipline, domain phrasing, retrieval relevance, routing, and in every playbook, the "when not to" is the same family of things: current facts, business state, permissions, fast-changing policy, and the knowledge base content. The data discipline is the same: clean, consistent, covered, decontaminated, with facts slotted out. The eval discipline is the same: beat the cheaper baseline, hold the regression wall, watch the protected slices. And the failure mode is the same: a fluent model confidently reciting something stale, or a model that broke a capability nobody measured. The OpenAI fine-tuning best practices compress all of it to a sentence, set up evals first, curate a representative dataset, fine-tune for consistency and efficiency once cheaper approaches are exhausted, and every playbook here is that sentence applied to a specific room. The decision is never "fine-tune or not" in the abstract. It is "what are we trying to change, is it behavior or knowledge, and can we prove training is the right way to change it", asked ten times, answered ten ways, by the same five questions.
Chapter summary
The book reduces to a decision made in a room, should we fine-tune this, and how, and these ten worked playbooks (support, extraction, classification, internal code assistant, legal/policy, medical summarization, sales/brand voice, knowledge base, agent tool discipline, cost reduction) each answer the same five questions: when to fine-tune, when not to, what data, what eval, what goes wrong, run through TRAIN. Read together, they reveal the thesis as a pattern: in every case the train-target is behavior (style, format, task structure, tool discipline, domain phrasing, retrieval relevance, routing) and the don't-train list is the same family (current facts, business state, permissions, fast-changing policy, knowledge-base content); the data discipline is identical (clean, consistent, covered, decontaminated, facts slotted out); the eval discipline is identical (beat the cheaper baseline, hold the regression wall, watch protected slices); and the failure mode is identical (a fluent model confidently reciting something stale, or a silently broken capability). Notable specifics: support and KB assistants mostly need retrieval (and the KB's best fine-tune is the retriever, not the generator); legal and medical carry the domain-phrasing confidence trap and demand grounded faithfulness plus human review; sales/brand is the clearest style and preference-tuning case but risks sycophancy; agent tool discipline is a strong under-used Toolformer-style case with a critical fabrication-on-failure eval; and cost reduction is justified only when a specialized small model provably matches the large one on the golden set with the hard tail routed up. The decision is never "fine-tune or not" in the abstract, it is "what are we changing, behavior or knowledge, and can we prove training is the right way," asked ten times and answered ten ways by the same five questions.