The Customization Menu and a Decision Tree
> **Working claim:** Fine-tuning is one item on a menu of nine customization techniques, most of which are cheaper, faster, and more reversible.

Working claim: Fine-tuning is one item on a menu of nine customization techniques, most of which are cheaper, faster, and more reversible. A mature team treats them as an ordered toolkit, reaching for the lightest tool that can solve the problem and escalating only when it provably can't. This chapter lays out the full menu, the order to try them in, and a decision tree that routes a diagnosed problem to an intervention, ending at fine-tuning only when the lighter tools have been ruled out.
Key Takeaways
- Fine-tuning is one rung on a ladder, not the default customization move.
- Cost of change, reversibility, and composability worsen as you climb the ladder.
- The decision tree routes facts, state, and permissions away from training immediately.
The menu, from lightest to heaviest
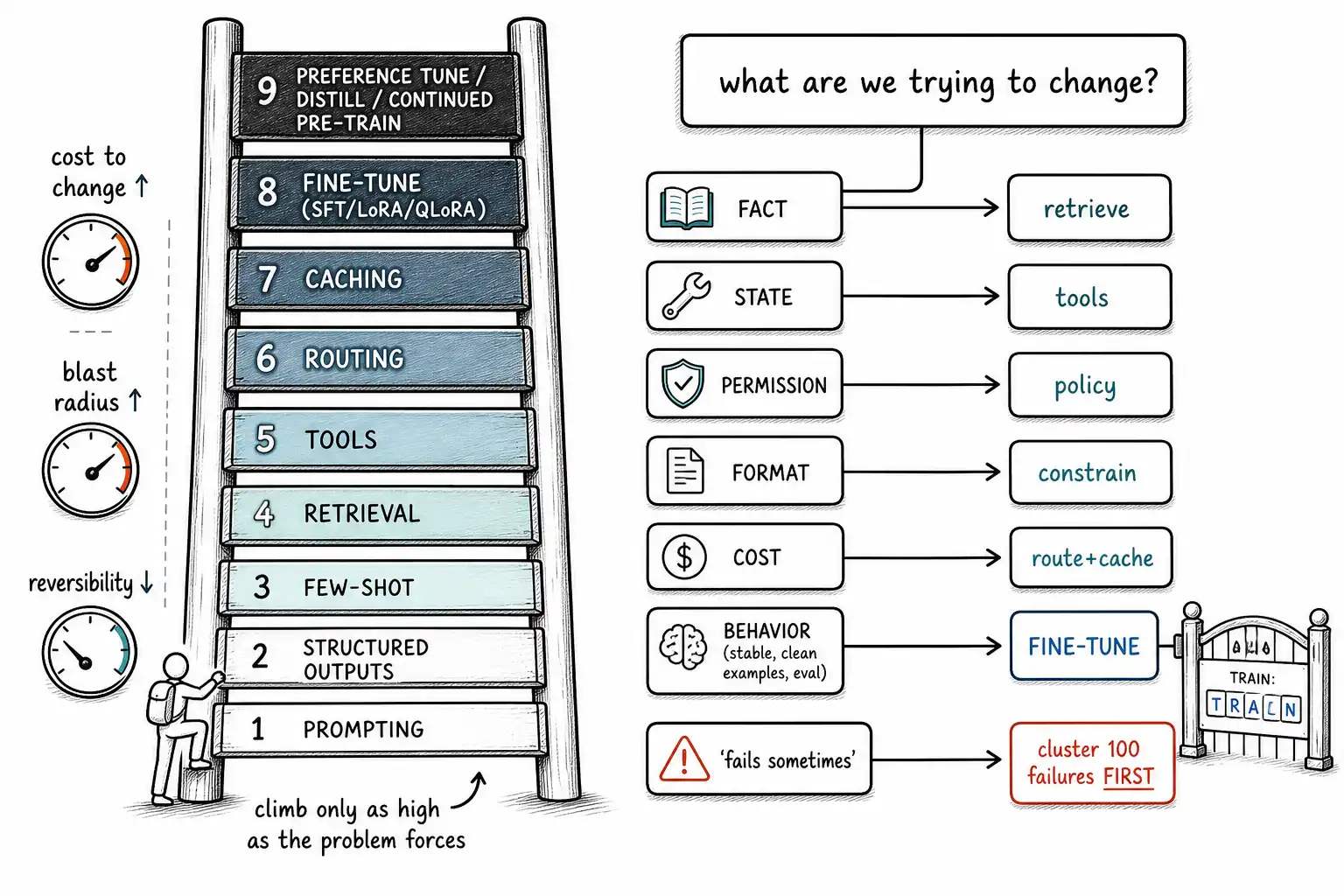
Customizing a model is not a binary between "use it as-is" and "fine-tune it." There is a spectrum, and the right mental model is a ladder: each rung is more powerful and more expensive than the one below, and you climb only as high as the problem forces you to. Here is the full menu, ordered by cost-to-change and reversibility, the lightest tools first.
- Prompting. Change the instructions. Zero training, instant to edit, infinitely reversible. Fixes a startling fraction of behavior complaints (tone, format, scope) and costs nothing but tokens.
- Structured outputs. Constrain the decode to a schema (JSON mode, function/tool schemas, grammars). Guarantees shape without hoping the model complies. Instant, reversible, reliable for format.
- Few-shot examples. Put demonstrations of the desired behavior in the prompt. Teaches patterns at inference time with no training; costs prompt tokens. The "free trial" of fine-tuning: if few-shot fixes it, you've learned the behavior is learnable without touching weights.
- Retrieval (RAG). Inject relevant current knowledge from an external store, per Lewis et al.. The correct home for facts, current state, and anything that changes. Edit a document, not a model.
- Tools / function calling. Let the model call code to fetch state, do math, take actions, per the Toolformer line of work. The correct home for business state, permissions-checked actions, and anything that must be computed rather than recalled.
- Routing. Send each request to the cheapest model that can handle it; escalate hard cases. Captures cost savings with no training. Often the answer to "it must be cheaper."
- Caching. Reuse computation for stable prompt prefixes; reuse answers for repeated questions. A cost and latency tool, not a behavior tool.
- Fine-tuning (SFT / LoRA / QLoRA). Change the weights to internalize a stable behavior, format, style, or skill (Chapters 12). Reversible only by rollback to a previous checkpoint; changeable only by retraining.
- Preference tuning / distillation / continued pre-training. The heaviest interventions: align to preferences (DPO/RLHF, Chapter 13), compress a large model's behavior into a small one (distillation, Chapter 7), or push new domain distribution into a base model. Most expensive, most specialized, least reversible.
The OpenAI model optimization guide compresses this into three moves it recommends in order, optimize prompt and context, add retrieval for missing information, then fine-tune for consistency and efficiency, which is the same ladder collapsed to its three load-bearing rungs. The fuller menu matters because real systems mix rungs: a production assistant might use prompting (1), structured outputs (2), retrieval (4), tools (5), routing (6), caching (7), and a fine-tune (8) at once, each doing the job it is best at.
The ordering rule: lightest tool that works
The discipline is not "always avoid fine-tuning." It is "reach for the lightest tool on the ladder that can provably solve the problem, and escalate only when it can't." This rule has three justifications, and they compound.
Cost of change. A prompt edit ships in a deploy. A retrieval document edits in seconds. A fine-tune takes a data-collection-train-eval-deploy cycle measured in days. The lighter the tool, the faster you iterate, and iteration speed is usually worth more than the marginal quality a heavier tool buys.
Reversibility. A prompt change is undone by reverting the prompt. A bad retrieval doc is fixed by editing it. A bad fine-tune is undone only by rolling back to a previous checkpoint, and if you trained without keeping the base, or without a registry of checkpoints, you may not be able to (Chapter 16). Lighter tools fail safe.
Composability. The lighter tools stack cleanly. You can add retrieval to a prompted system without disturbing anything. Fine-tuning changes the substrate everything else runs on, so it interacts with your prompts (your few-shot examples may now be redundant or conflicting), your retrieval (the model may now behave differently on retrieved context), and your evals (your whole suite must be re-run). Heavier tools have wider blast radius.
This is why the menu is ordered and why the order is the recommendation. Climbing the ladder is monotonic in cost, risk, and blast radius; you want to stop climbing as early as the problem allows.
A worked routing of common problems
The menu becomes useful when you route concrete problems through it. Here is a table mapping frequent symptoms to the lightest adequate intervention, with fine-tuning appearing only where it genuinely earns its place.
| Problem | Lightest adequate tool | Why not fine-tune |
|---|---|---|
| Answers about current pricing are wrong | Retrieval (4) | Pricing changes; freezing it in weights guarantees staleness |
| Output isn't valid JSON | Structured outputs (2) | Decode-time constraint is more reliable than a trained tendency |
| Needs this user's account balance | Tools (5) | Per-request state; never a weight |
| Too expensive at high volume | Routing (6) + caching (7) | No training risk; captures most savings immediately |
| Tone drifts occasionally | Prompting (1), then few-shot (3) | Try the free tools before paying for surgery |
| Can't reason through multi-step questions | Few-shot CoT (3) | Chain-of-thought prompting often elicits latent reasoning without training |
| Tone must be perfect across millions of calls, prompt-engineering plateaus | Fine-tune (8) | Style is pervasive behavior; prompting has provably plateaued; volume justifies it |
| Need a stable extraction format at high volume, cheaply | Fine-tune a small model (8) | Repeated task behavior + cost specialization; the strong case (Ch. 5, 7) |
| Large model is overkill but small model is close | Fine-tune the small model (8) | Closing a measured gap on a specialized task at real savings |
Read the table top to bottom and a pattern appears: fine-tuning shows up only when the problem is behavior (not knowledge or state), stable (not changing weekly), high-volume or quality-critical (worth the overhead), and proven to need it (lighter tools fell short on an eval). Anywhere those conditions are not all met, a lighter tool wins.
The decision tree
Here is the routing as an explicit tree. It is deliberately blunt, the goal is to get most problems off the fine-tuning path quickly and onto the right cheaper path, leaving a small, well-justified set of genuine training cases.
START: What are we trying to change?
├─ A current FACT, or per-request STATE, or a PERMISSION?
│ └─ NOT a fine-tune. Ever.
│ ├─ Fact that changes → RETRIEVAL (index it, update it)
│ ├─ Per-request state → TOOLS (fetch it)
│ └─ Permission → POLICY in code (check it per request)
│
├─ KNOWLEDGE the model lacks?
│ └─ Does the right document in the prompt fix it?
│ ├─ Yes → RETRIEVAL (it was a knowledge gap, not a weight gap)
│ └─ No, it's a reasoning/skill gap → go to BEHAVIOR branch
│
├─ Output SHAPE/FORMAT wrong?
│ └─ Does instruction + schema constraint + few-shot fix it ≥~95%?
│ ├─ Yes → STRUCTURED OUTPUTS + PROMPTING (ship it)
│ └─ No, and it's high-volume → candidate FINE-TUNE (Ch. 5)
│
├─ Too EXPENSIVE / slow?
│ └─ Can routing + caching + a smaller off-the-shelf model hit the bar?
│ ├─ Yes → ROUTING + CACHING (no training)
│ └─ Close but not quite, high volume → FINE-TUNE small model (Ch. 7)
│
├─ BEHAVIOR/STYLE/SKILL inconsistent?
│ └─ Does prompting + few-shot reach the bar?
│ ├─ Yes → PROMPTING (ship it)
│ └─ No, prompting has plateaued, behavior is STABLE, you have
│ CLEAN examples, and you can EVAL the improvement
│ └─ Now run the TRAIN gate (T,R,A,I,N). If all pass → FINE-TUNE
│ else → fix the failing dimension first (usually data or eval)
│
└─ "It fails SOMETIMES"?
└─ STOP. Cluster 100 failures first, then route each cluster
through this tree."Sometimes" is not a node; it's unfinished triage.Two properties of this tree are deliberate. First, the fact/state/permission branch dead-ends immediately at "not a fine-tune, ever", these are the cases that cause the most damage when trained, so they get the bluntest treatment. Second, every path to fine-tuning passes through a gate that checks for cheaper options and for readiness, prompting must have plateaued, behavior must be stable, examples must be clean, and the improvement must be measurable. You cannot fall into a fine-tune by default; you have to be routed there by elimination and clear the TRAIN gate to enter.
Where the heaviest tools live
The bottom rungs, preference tuning, distillation, continued pre-training, are off the main tree because they are rarely the first customization a team needs and they presuppose you have already climbed the ladder. Preference tuning (Chapter 13) is for when demonstrations cannot express what you want and you need to teach the model which of two responses is better. Distillation (Chapter 7) is for when you have a working large-model behavior and want it cheaply in a small model: it presupposes the large model already does the job. Continued pre-training is for when you genuinely need to shift a base model's distribution toward a new domain or language at scale, which is a rare, expensive, research-adjacent undertaking that most product teams should not attempt. LoRA and its quantized cousin QLoRA sit between SFT and these, lowering the cost of the fine-tuning rung enough that it is no longer gated by GPU budget, which is exactly why the discipline of the ladder matters more now than it did when fine-tuning was expensive enough to self-limit.
That last point deserves emphasis. The reason this chapter exists is that parameter-efficient methods removed the natural cost barrier that used to keep teams off the fine-tuning rung. When fine-tuning required a cluster and a week, the expense itself forced a differential diagnosis. Now that a LoRA run is cheap and fast, nothing external stops a team from training reflexively, so the discipline has to be internal. The ladder, the ordering rule, and the decision tree are that internal discipline made explicit.
Chapter summary
Customization is a ladder of nine tools ordered by cost-to-change and reversibility: prompting, structured outputs, few-shot, retrieval, tools, routing, caching, fine-tuning, and the heaviest interventions (preference tuning, distillation, continued pre-training). The discipline is not to avoid fine-tuning but to reach for the lightest tool that can provably solve the problem and escalate only when it can't, justified by cost of change, reversibility, and composability, all of which worsen as you climb. Routing common problems through the menu shows fine-tuning earning its place only when the target is behavior (not facts, state, or permissions), stable, high-volume or quality-critical, and proven to need training by an eval. The decision tree makes this concrete: the fact/state/permission branch dead-ends at "not a fine-tune, ever"; format routes through constraints and prompting first; cost routes through routing and caching first; behavior reaches fine-tuning only after prompting plateaus and the TRAIN gate passes; and "it fails sometimes" is not a node but unfinished triage that must be clustered first. The heaviest tools sit off the main tree because they presuppose you have already climbed the ladder. The deeper point: parameter-efficient methods removed the cost barrier that used to force a differential diagnosis, so the ladder must now be an internal discipline rather than an external one.