Versioning, Lineage, Drift, and Retirement
> **Working claim:** Training a model is the beginning of the operational burden, not the end. A fine-tuned model is a thing you now version, reproduce, monitor, retrain, retire, and answer for, to auditors, to regulators, to the on-call engineer at 3 a.

Working claim: Training a model is the beginning of the operational burden, not the end. A fine-tuned model is a thing you now version, reproduce, monitor, retrain, retire, and answer for, to auditors, to regulators, to the on-call engineer at 3 a.m. The teams that skip this build a model they cannot reproduce, cannot roll back, cannot explain, and cannot delete from. Operability must be designed in before training, because retrofitting it is a migration nightmare.
Key Takeaways
- Training creates an operational asset you now version, reproduce, monitor, retrain, and retire.
- Dataset cards, model cards, and adapter registries make governance concrete.
- Deletion, vendor lock-in, and drift are design-time problems, not future chores.
The day-two problem
The fine-tuning literature, the tutorials, and most internal project plans end at the moment the eval passes. Production begins there. A shipped fine-tune is not an artifact you set down; it is a system you now operate, and the operational questions arrive whether or not you prepared for them: Which dataset produced this model? Can we reproduce it? It's behaving worse than last month, why? A user demanded we delete their data, is it in the weights? The policy changed, is the model still compliant? The vendor deprecated the base model, now what? Each of these is answerable cheaply if you designed for it before training and expensively or not at all if you didn't. This chapter is the day-two checklist, and its theme is that operability is a design-time decision masquerading as a future problem.
The NIST AI Risk Management Framework frames this as the difference between building a model and governing one, and governance is the part that distinguishes a fine-tune you can defend from one you merely shipped. The artifacts below are how governance becomes concrete.
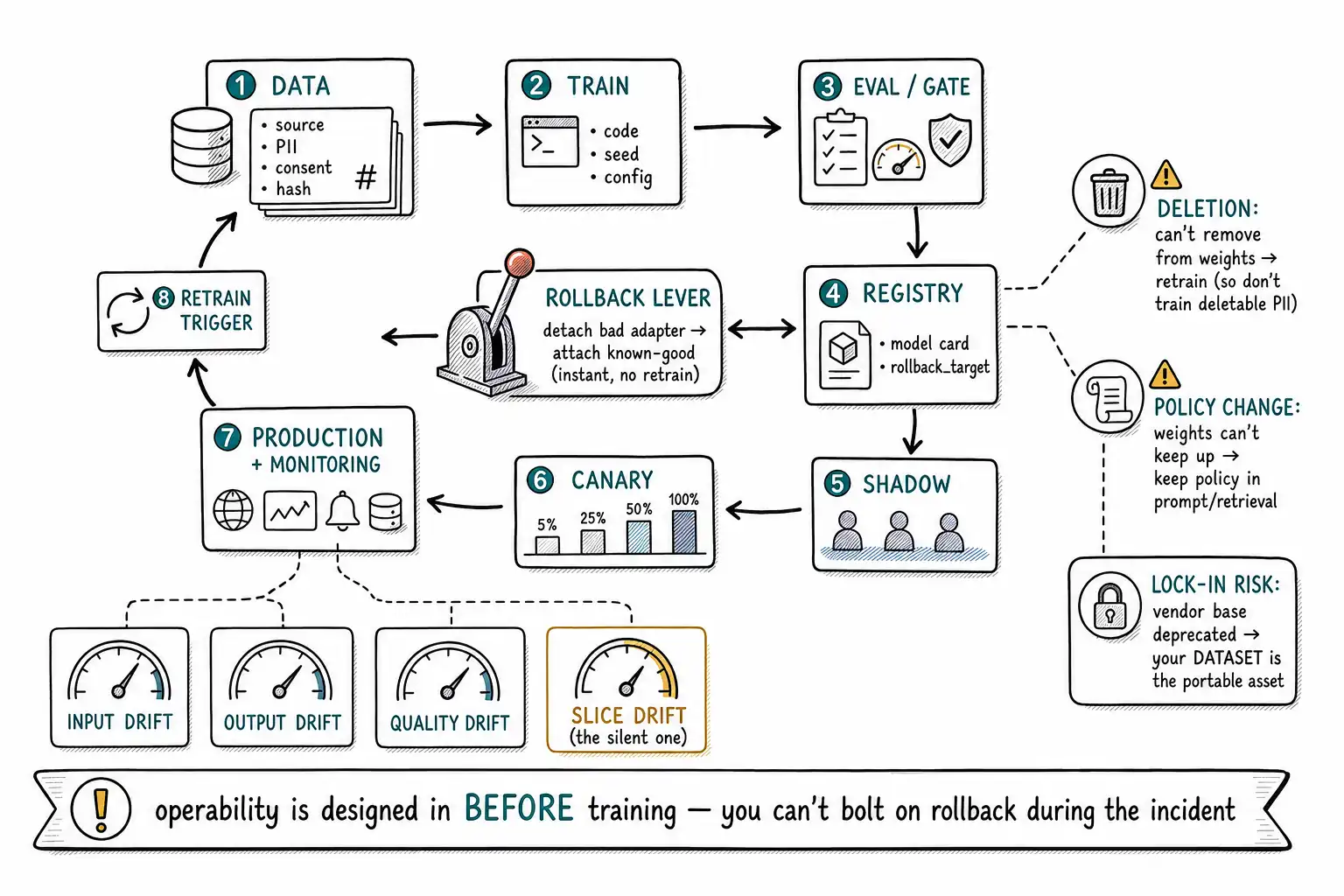
Lineage: the model is its data plus its run
The first operational requirement is lineage: the ability to trace a deployed model back to exactly the data and configuration that produced it. Without lineage you cannot reproduce the model, cannot debug a regression, cannot honor a deletion request, and cannot answer an auditor, you have a model whose origins are a mystery, which is an unacceptable thing to have in production. Lineage is built from three linked records.
A dataset card (in the spirit of Datasheets for Datasets) records what the training data was: its sources, owners, licenses, PII status, consent basis, the labeler-instruction version (Chapter 9), the measured agreement and coverage, the split rules (Chapter 10), and a content hash so you know the exact bytes.
dataset_card:
id: support-triage-v4
hash: sha256:9f3c1a... # exact bytes that trained the model
sources:
- {name: prod_tickets_2023_2025, owner: support-eng, license: internal, pii: redacted}
- {name: synthetic_edge_cases_v2, owner: ml-team, license: internal, generator: model-x, verified: human-sampled}
consent_basis: "support interactions, retention policy R-12, PII redacted pre-training"
labeler_instructions_version: v3
measured: {inter_annotator_agreement: 0.88, classes: 8, edge_case_fraction: 0.22}
splits: {rule: "by_customer_entity + temporal", train: 0.8, val: 0.1, test: 0.1}
excluded: ["raw_pii", "tickets_flagged_legal_hold"] # the "do not train on this" setA model card (in the spirit of Model Cards for Model Reporting) records what the model is: its base, the method and config (Chapter 12), the dataset card it trained on, its eval results across all axes (Chapter 15), its intended use, and its known limitations and failure slices.
model_card:
id: support-triage-lora-2026-06-08
base_model: {name: meta-base-8b, version: 8b-r3, hash: sha256:...}
method: {type: lora, r: 16, alpha: 32, objective: sft}
trained_on: support-triage-v4 # links to the dataset card
run_manifest: run-2026-06-08-1337 # links to the run record
eval: {task_f1: 0.91, truthfulness: 0.79, format: 0.99, slice_es: 0.87}
intended_use: "classify inbound support tickets into 8 categories + priority"
out_of_scope: ["answering product questions", "billing actions"] # route those elsewhere
known_limitations: ["lower recall on multi-issue tickets", "es slice below en by 4pts"]
rollback_target: support-triage-lora-2026-05-02 # the adapter to detach back toA run manifest records what happened: the exact code version, the seed, the hardware, the timestamps, and the resulting checkpoint location, so the run can be reproduced bit-for-bit. Together, dataset card + model card + run manifest are the lineage: any deployed model points to the data, config, and run that made it, and any of those can be retrieved on demand. The LoRA discipline of Chapter 12 helps here, because the adapter is a small file detachable from a pinned base, the rollback_target is a real, exact previous state, not a hopeful "we think we still have the old checkpoint."
Drift: the model didn't change, the world did
A subtle production reality: a fine-tuned model's quality degrades over time even though its weights never change, because the world its training data described moves on. The input distribution shifts (new products, new slang, new attack patterns), the correct answers shift (policy changes, taxonomy changes), and the frozen model keeps answering as if it were still the day it trained. This is drift, and it is the operational manifestation of the Chapter 1 thesis: the model froze a snapshot, and the snapshot ages.
Drift is invisible unless you monitor for it, and the monitoring schema is part of the deployment, not an afterthought.
-- Production monitoring: detect drift before users do.
CREATE TABLE inference_log (
request_id TEXT PRIMARY KEY,
model_id TEXT NOT NULL, -- which model version served this
input_hash TEXT NOT NULL,
input_features JSONB, -- length, language, detected entities, etc.
output TEXT NOT NULL,
confidence REAL, -- model's own confidence, if calibrated
served_at TIMESTAMPTZ NOT NULL,
-- filled later from corrections/review:
was_correct BOOLEAN, -- ground-truth outcome when known (Ch. 8 flywheel)
failure_cluster TEXT
);
-- Drift signals to alert on:
-- 1) INPUT drift: distribution of input_features shifts vs the training distribution
-- 2) OUTPUT drift: distribution of predicted classes shifts unexpectedly
-- 3) QUALITY drift: rolling was_correct rate falls below the release-gate bar
-- 4) SLICE drift: a protected slice (e.g. language=es) degrades even if overall holdsThe most important drift signal is quality drift on a protected slice, because aggregate quality can hold steady while a slice you care about quietly rots, the same slice-blindness that the release gate guards against at launch (Chapter 15), now monitored continuously. When drift crosses a threshold, it is a retraining trigger: the signal that the model's snapshot has aged enough to need a fresh one, fed by the correction flywheel of Chapter 8 (the production failures that drift produces become the training data and eval cases for the next model). Drift monitoring plus the correction flywheel is what makes a fine-tuned model a living system rather than a decaying one.
Deletion, policy change, and the things weights make hard
Two operational obligations are uniquely painful for fine-tuned models, and both trace to the immutability of weights.
Deletion. Under regimes like GDPR's right to erasure, a person can demand you delete their data. If their data is in a retrieval store, you delete the rows: done. If their data was trained into a fine-tune, you cannot surgically remove it from the weights; the honest options are to retrain without their data or to roll back, both expensive. This is a decisive reason not to train on deletable personal data in the first place (Chapter 1), but if you must, lineage is what makes deletion possible at all: the dataset card's PII and consent records let you identify which models trained on the affected data and which need retraining, and the exclusion list lets the retrain omit it. A fine-tune without lineage cannot answer "is this person's data in this model?", and "we don't know" is not an answer you want to give a regulator.
Policy change. When a policy changes, a refund rule, a compliance requirement, a safety boundary, a retrieval-and-prompt system updates instantly (edit the document or the system prompt). A fine-tuned model that internalized the old policy keeps applying it until retrained, and worse, it does so invisibly and confidently. This is the strongest operational argument for the book's central discipline: never train fast-changing policy into weights (Chapter 1), because the weights cannot keep up with policy and you will not even notice the model is out of compliance until an audit or an incident. Where a fine-tune and a policy must coexist, the policy lives in the prompt/retrieval layer and the fine-tune handles only the stable behavior, so a policy change is a prompt edit, not a training cycle.
Vendor lock-in and cost accounting
Two more day-two realities. Vendor lock-in: a fine-tune created through a managed API is usually tied to that vendor's base model and platform, you often cannot export the weights, the base can be deprecated out from under you, and your investment in the dataset is portable but your investment in the trained model is not. The OpenAI supervised fine-tuning platform's own lifecycle changes are a live reminder that vendor fine-tuning offerings come and go, and a model tied to a deprecated platform is a forced migration on the vendor's timeline, not yours. The mitigation is to keep the dataset (the portable, reproducible asset) pristine and versioned, so that re-creating the model on a different base is a retraining job rather than a from-scratch rebuild, your lineage is your portability.
Cost accounting: the true cost of a fine-tune is not the training run. It is training plus data curation plus the eval suite plus ongoing monitoring, periodic retraining, on-call surface, and migration risk, the full cost model of Chapter 7, carried forward for the model's whole life. A fine-tune that looked cheap at training time can be expensive in operation, and the honest accounting includes the recurring drag, because that drag is what determines whether the specialization actually saved money (Chapter 7) or just moved the cost from inference to operations.
The incident runbook
Finally, the artifact you hope not to need: the runbook for a bad fine-tune release. Because the gate (Chapter 15) is not perfect and drift is inevitable, you will eventually have a fine-tuned model behaving badly in production, and the time to write the response is before the 3 a.m. page, not during it.
INCIDENT: fine-tuned model behaving badly in production
1. DETECT Alert fired: protected-slice quality below bar / safety regression / spike in a failure_cluster.
2. CONTAIN Flip the router/feature-flag to the rollback_target (previous adapter on pinned base).
LoRA makes this instant: detach the bad adapter, attach the known-good one. No retrain.
3. ASSESS Pull inference_log for the bad model_id. Cluster the failures. Which slice? Which inputs?
4. DIAGNOSE Map to a root-cause class:
- data: contamination/contradiction missed in the gate -> fix dataset, re-run validator
- drift: world changed -> retraining trigger, refresh data
- forgetting: regression the gate's wall missed -> add the broken axis to the gate
- scope: model used outside intended_use (model card) -> fix routing, not the model
5. RECOVER Build corrected dataset (flywheel), retrain, run the FULL release gate, shadow + canary.
6. PREVENT Add the failure cluster as a permanent regression case (Ch. 15). Update the gate so this
class of failure blocks future releases. Update the model card's known_limitations.The runbook's most important line is step 2, and it is only possible because of decisions made long before the incident: the rollback target exists because you kept lineage and used LoRA's detachable adapter, the feature flag exists because you designed the serving layer to swap models without a deploy, and the rollback is instant rather than a frantic retrain because you preserved the previous good state. The incident response is the payoff for the operability you designed in at training time, which is the whole point of the chapter. You cannot bolt on rollback, lineage, deletion, and drift monitoring after an incident; you build them before, or you do without them exactly when you need them most.
Chapter summary
Training is the beginning of the operational burden: a shipped fine-tune is a system you version, reproduce, monitor, retrain, retire, and answer for, and the day-two questions (which data made this? can we reproduce it? why is it worse? is a user's data in the weights? is it still compliant? the base was deprecated, now what?) are cheap to answer if designed for and expensive or impossible if not. Lineage, a dataset card (sources, PII, consent, labeler-instruction version, measured quality, splits, hash), a model card (base, method, eval across all axes, intended use, limitations, rollback target), and a run manifest (code, seed, hardware), lets any deployed model trace back to the data, config, and run that made it, and LoRA's detachable adapter makes the rollback target a real exact state. Drift is degradation without weight change, because the frozen snapshot ages as the world moves; you detect it with a monitoring schema watching input, output, quality, and especially protected-slice drift, and crossing a threshold is a retraining trigger fed by the correction flywheel. Deletion and policy change are uniquely painful for weights: you cannot surgically erase a person's data from a fine-tune (so don't train deletable PII, and let lineage scope a retrain if you must), and weights cannot keep up with changing policy (so keep policy in the prompt/retrieval layer). Vendor lock-in makes the dataset, not the trained model, your portable asset; honest cost accounting carries monitoring, retraining, and on-call for the model's whole life. And the incident runbook's instant rollback (detach the bad adapter, attach the known-good one) is the payoff for operability designed in at training time, because you cannot bolt on rollback, lineage, deletion, and drift monitoring during the incident, exactly when you need them most.