Labels, Disagreement, and Coverage
This chapter turns labels, disagreement, and coverage into a concrete operating problem for the fine tuning or not book.

Working claim: A dataset's quality is decided by three things the row count never shows: whether the labels are consistent (do your labelers agree?), whether the hard and negative cases are covered (or only the easy middle?), and whether contradictions have been resolved (or quietly trained in?). A model trained on inconsistent labels does not average them into wisdom; it learns the inconsistency and reproduces it as unpredictability. Fix the data before you fix the model.
Key Takeaways
- Row count is not data quality; agreement and coverage decide what the model learns.
- Disagreement is a diagnostic signal that can expose a broken taxonomy or vague instructions.
- A validator catches duplicates, contradictions, imbalance, and missing hard negatives before training.
The number that does not matter
"How many examples do we need?" is the first question every team asks and the wrong first question. Row count is the most visible property of a dataset and among the least important once you are past a viable floor. A few hundred clean, consistent, well-targeted demonstrations routinely beat tens of thousands of noisy ones, and the OpenAI fine-tuning best practices reflect this, they emphasize a curated, representative dataset and note that you can often start small and add data where the eval shows weakness, rather than collecting a massive corpus up front. InstructGPT achieved a large behavioral shift with a labeling effort that was about quality and careful instructions, not raw volume.
The reason quality dominates quantity is mechanical, from Chapter 2: fine-tuning shapes a distribution toward the patterns in the data. Consistent data presents one clear pattern, reinforced every example, and the model learns it sharply. Inconsistent data presents conflicting patterns, and the model learns the conflict, it does not resolve the disagreement into a sensible compromise; it internalizes the variance and reproduces it as unpredictable behavior. More noisy rows means a sharper picture of the noise. This is why the chapter's three concerns, consistency, coverage, and contradiction, matter more than size, and why a validator that checks them (below) is worth more than a scraper that adds rows.
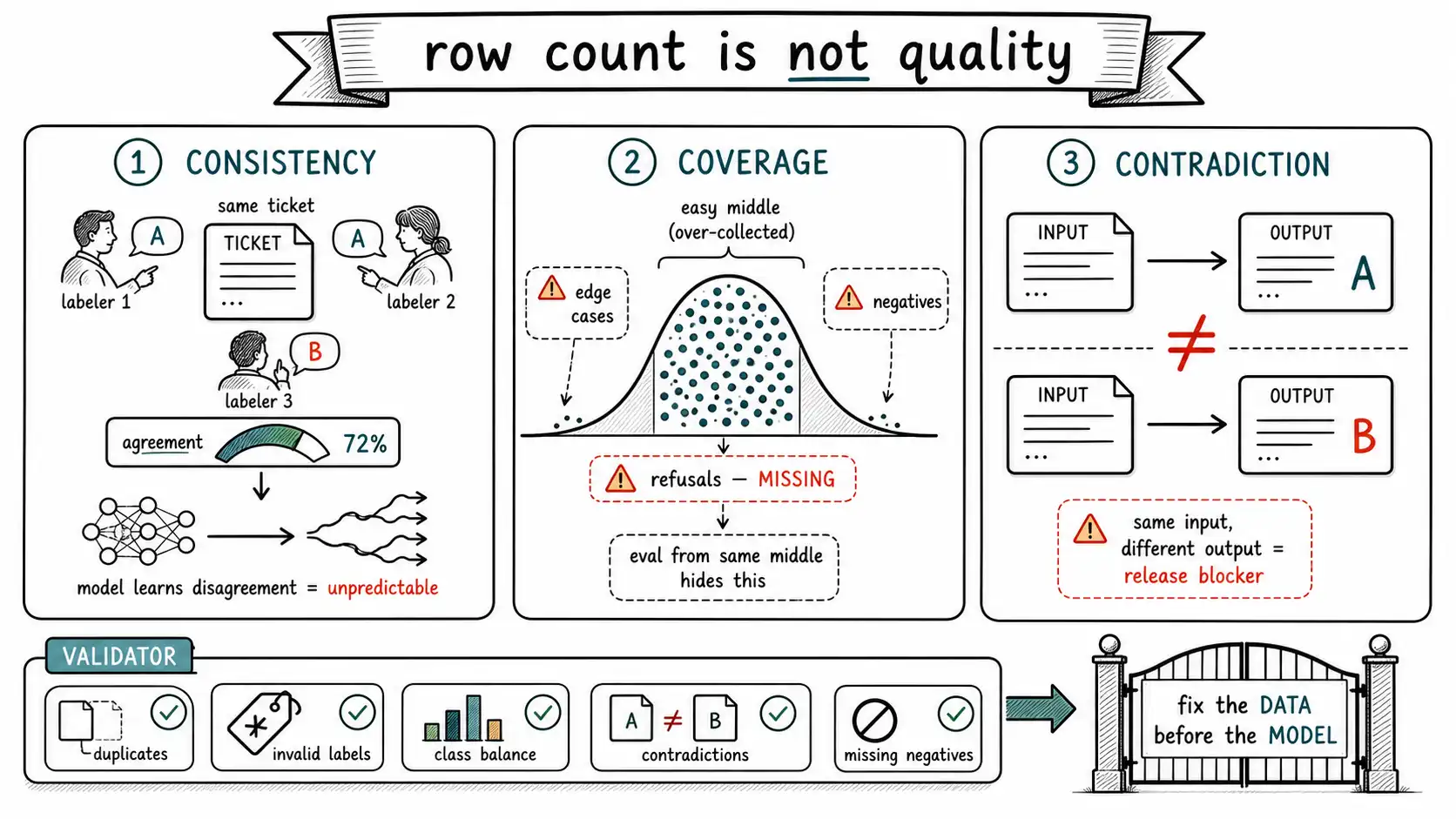
Inter-annotator disagreement: the hidden variance
Here is a scenario that plays out constantly. A team builds a support-triage dataset by having three agents label tickets into eight categories. Everyone assumes the labels are ground truth. Then someone measures inter-annotator agreement, how often two labelers independently assign the same category to the same ticket, and finds it is 72%. More than one ticket in four is labeled differently by different people. The dataset that everyone treated as ground truth is, on a quarter of its rows, a coin flip dressed as a fact.
This matters because the model trains on whatever label happened to be assigned, and where labelers disagree, the assigned label is partly random. The model is being taught that the same kind of ticket maps sometimes to category A and sometimes to category B, and it learns exactly that: it becomes unpredictable on the ambiguous cases, which are often the cases that matter. Low agreement is not a labeler problem to scold away; it is a signal that either the task is genuinely ambiguous (the categories overlap) or the instructions are underspecified (labelers are guessing differently). Both are fixable, and both must be fixed in the data and the guidelines, not hoped away by the model.
def annotator_agreement(labels_by_annotator: dict[str, dict[str, str]]) -> dict:
"""labels_by_annotator: {annotator_id: {item_id: label}}.
Reports pairwise agreement and per-item disagreement to triage the data."""
from itertools import combinations
annotators = list(labels_by_annotator)
items = set().union(*[set(d) for d in labels_by_annotator.values()])
pair_agree = {}
for a, b in combinations(annotators, 2):
shared = [i for i in items if i in labels_by_annotator[a] and i in labels_by_annotator[b]]
agree = sum(labels_by_annotator[a][i] == labels_by_annotator[b][i] for i in shared)
pair_agree[(a, b)] = agree / len(shared) if shared else None
# Items where annotators disagree are the ones to review FIRST
contested = []
for i in items:
votes = {labels_by_annotator[a][i] for a in annotators if i in labels_by_annotator[a]}
if len(votes) > 1:
contested.append((i, votes))
return {"pairwise_agreement": pair_agree, "contested_items": contested}The contested items are gold: they are exactly the cases where your taxonomy or instructions are failing, and reviewing them tells you whether to merge two overlapping categories, add a decision rule to the labeler guidelines, or accept that the case is genuinely ambiguous and handle it with a confidence threshold rather than a hard label. Measuring agreement before training is one of the cheapest, highest-value steps in the whole pipeline, and almost nobody does it. The broader point, that even famous benchmark test sets carry pervasive label errors, as Northcutt et al. documented, should make you humble about your own labels: if curated academic datasets are wrong on a measurable fraction of rows, your hastily-labeled production set is worse, and you should measure rather than assume.
Labeler instructions are part of the dataset
The fix for low agreement is usually not better labelers; it is better instructions. Labeler instructions are an artifact of the dataset, as load-bearing as the labels themselves, because they define what the labels mean. Two labelers who disagree about whether "I can't log in and I'm furious" is account_access or complaint are not careless; they are responding to an instruction that did not say which dimension dominates. The fix is a decision rule in the guidelines: "if the ticket contains a concrete technical blocker, label by the blocker regardless of tone." That rule, written once, raises agreement across every future label.
Good labeler instructions share features with good code: they handle the edge cases explicitly, they give examples (especially of the confusing pairs), they state a default for genuine ambiguity, and they are versioned, because when you change the instructions you have changed the meaning of every label collected after the change, and mixing label-meanings across an instruction change silently contaminates the dataset. A dataset assembled from labels collected under three different versions of the guidelines is three datasets stacked on top of each other, and the model learns their average, which is no one's intended behavior. Version the instructions, record which version produced each label, and you can detect and segregate this contamination.
Coverage: the easy middle and the missing edges
The third quality dimension is coverage, and the characteristic failure is a dataset that is all easy middle and no edges. People labeling examples gravitate to clear cases, the unambiguous billing dispute, the obvious bug report, because clear cases are fast to label and feel like progress. The result is a dataset that teaches the model the easy cases it could already half-do and starves it of the hard cases where it actually fails. The model trained on this passes its eval (the eval, drawn from the same easy distribution, is also all middle) and then meets the production edge cases and falls apart. Coverage failures are invisible to the row count and to an eval drawn from the same biased pool, which is what makes them dangerous.
Three categories of coverage are routinely missed and individually worth chasing:
- Edge cases: the rare, hard, ambiguous inputs where the model is most likely to fail and most needs guidance. These are exactly the contested items from your agreement analysis and the corrections from your error clustering (Chapter 8). Deliberately over-sample them relative to their natural frequency, then weight or note that in the eval.
- Negative examples: inputs where the right behavior is to not do the thing: not classify (it's out of scope), not call the tool, not answer (refuse or escalate). A dataset of only positive examples teaches a model that is eager and over-triggering, because it has never seen a case where restraint was correct.
- Refusal examples: the safety-critical subset of negatives: inputs where the model must decline, hedge, or escalate. InstructGPT and the alignment literature treat these as first-class, because a model that has never been shown a good refusal will improvise a bad one. If your task has any case where "I can't help with that" or "let me escalate this" is the correct output, those cases must be in the training set, or the model will not produce them.
A dataset that covers the easy middle, the hard edges, the negatives, and the refusals teaches a model that is competent, restrained, and safe. One that covers only the middle teaches a model that demos well and fails in production exactly where failure is most costly.
A dataset validator
The disciplines above become operational as a validator you run before every training job. It will not catch everything (it cannot judge whether a label is correct), but it catches the mechanical failures, duplicates, invalid labels, class imbalance, contradictions, missing negatives, that account for a large share of failed fine-tunes. The Data Quality for ML literature is essentially a long argument that this gate belongs in the pipeline.
from collections import Counter
import hashlib, json
def validate_dataset(rows: list[dict], valid_labels: set[str]) -> dict:
issues = {"duplicates": [], "invalid_labels": [], "contradictions": [],
"class_balance": {}, "missing_negatives": False, "near_empty_outputs": []}
seen_inputs = {} # input_hash -> output (to find contradictions)
label_counts = Counter()
for i, r in enumerate(rows):
inp = r["messages"][-2]["content"]
out = r["messages"][-1]["content"]
h = hashlib.sha256(inp.strip().lower().encode()).hexdigest()
if h in seen_inputs:
if seen_inputs[h] == out:
issues["duplicates"].append(i) # same in, same out: redundant
else:
issues["contradictions"].append((i, seen_inputs[h], out)) # same in, diff out: DANGER
else:
seen_inputs[h] = out
try:
label = json.loads(out).get("category")
if label not in valid_labels:
issues["invalid_labels"].append((i, label))
label_counts[label] += 1
except Exception:
pass
if len(out.strip()) < 3:
issues["near_empty_outputs"].append(i)
issues["class_balance"] = dict(label_counts)
# crude imbalance flag: any class < 5% of the largest class
if label_counts:
mx = max(label_counts.values())
issues["imbalanced_classes"] = [k for k, v in label_counts.items() if v < 0.05 * mx]
# negatives present? (a refusal/escalate/none-of-the-above label)
issues["missing_negatives"] = not (label_counts.keys() & {"out_of_scope", "refuse", "escalate", "none"})
return issuesThe most important check is contradictions: two rows with the same input and different outputs. These are not redundancy (that is duplicates, harmless if wasteful); they are the inter-annotator disagreement made concrete, and they directly teach the model to be inconsistent on that input. Every contradiction must be resolved, pick the right output, fix the labeler guideline that allowed the disagreement, and remove or correct the bad row, before training. A contradiction trained in is a behavior you cannot prompt away. Treat the validator's contradiction list as a release blocker, not a warning.
The output of this whole chapter is captured in a data card, a short document, in the spirit of Datasheets for Datasets, recording the dataset's measured agreement, coverage, class balance, labeler-instruction version, and known limitations. We build the full manifest in Chapter 16; the point here is that these quality measurements are not throwaway diagnostics, they are dataset metadata you keep, because the next person to retrain (possibly future-you) needs to know that agreement was 72% on three categories before they trust the result.
Chapter summary
Row count is the most visible and least important property of a dataset past a viable floor: a few hundred clean consistent demonstrations beat tens of thousands of noisy ones, because fine-tuning shapes a distribution and inconsistent data teaches the inconsistency rather than averaging it into wisdom. Three quality dimensions the row count hides decide everything. Consistency: measure inter-annotator agreement before training, low agreement (a common 72% on overlapping categories) means the model will be unpredictable on the ambiguous cases, and the contested items are gold because they reveal where the taxonomy or instructions fail; even curated academic test sets carry pervasive label errors, so measure yours rather than assume. The fix is usually better labeler instructions, a versioned artifact of the dataset that defines what labels mean, with explicit edge-case rules and a default for ambiguity, segregated by version so an instruction change doesn't silently contaminate the set. Coverage: datasets gravitate to the easy middle and starve the edges, negatives (where the right behavior is restraint), and refusals (safety-critical declines), producing a model that demos well and fails exactly where failure costs most, so deliberately over-sample edges, negatives, and refusals. Contradiction: two rows with the same input and different outputs directly teach inconsistency and must be a release blocker, resolved in the data and the guidelines before training. A validator catches the mechanical failures (duplicates, invalid labels, imbalance, contradictions, missing negatives), and the measurements become a kept data card, because the next person to retrain needs to know what the data's quality actually was.