The Support Bot That Knew the Old Product
> **Working claim:** Most "we should fine-tune" decisions are made before anyone has named what they are trying to change.

Working claim: Most "we should fine-tune" decisions are made before anyone has named what they are trying to change. Fine-tuning is the right tool for changing behavior and the wrong tool for adding current knowledge, and many real problems are a tangle of both. The first engineering act is separating the strands, because each strand routes to a different, cheaper, more reversible intervention.
Key Takeaways
- Behavior belongs in weights when it is stable, pervasive, and measurable.
- Current facts, state, permissions, and deletable private data belong outside the model.
- The first engineering act is naming the symptom before anyone writes fine-tune on a ticket.
The four words, again
We open where the introduction ended, with the four words spoken in a planning meeting: we should fine-tune it. They are worth dwelling on because of what they leave unsaid. The sentence has a verb (fine-tune) and an object (it), but no description of the disease, only the prescription. Compare it to how a careful engineer talks about a slow endpoint. Nobody competent says "we should add an index" before they have looked at the query plan, because everyone has been burned by adding an index that the planner ignores. Fine-tuning has not yet accumulated that institutional scar tissue. It is still spoken about the way indexes were spoken about in 2005: as a generic remedy applied to a generic ailment.
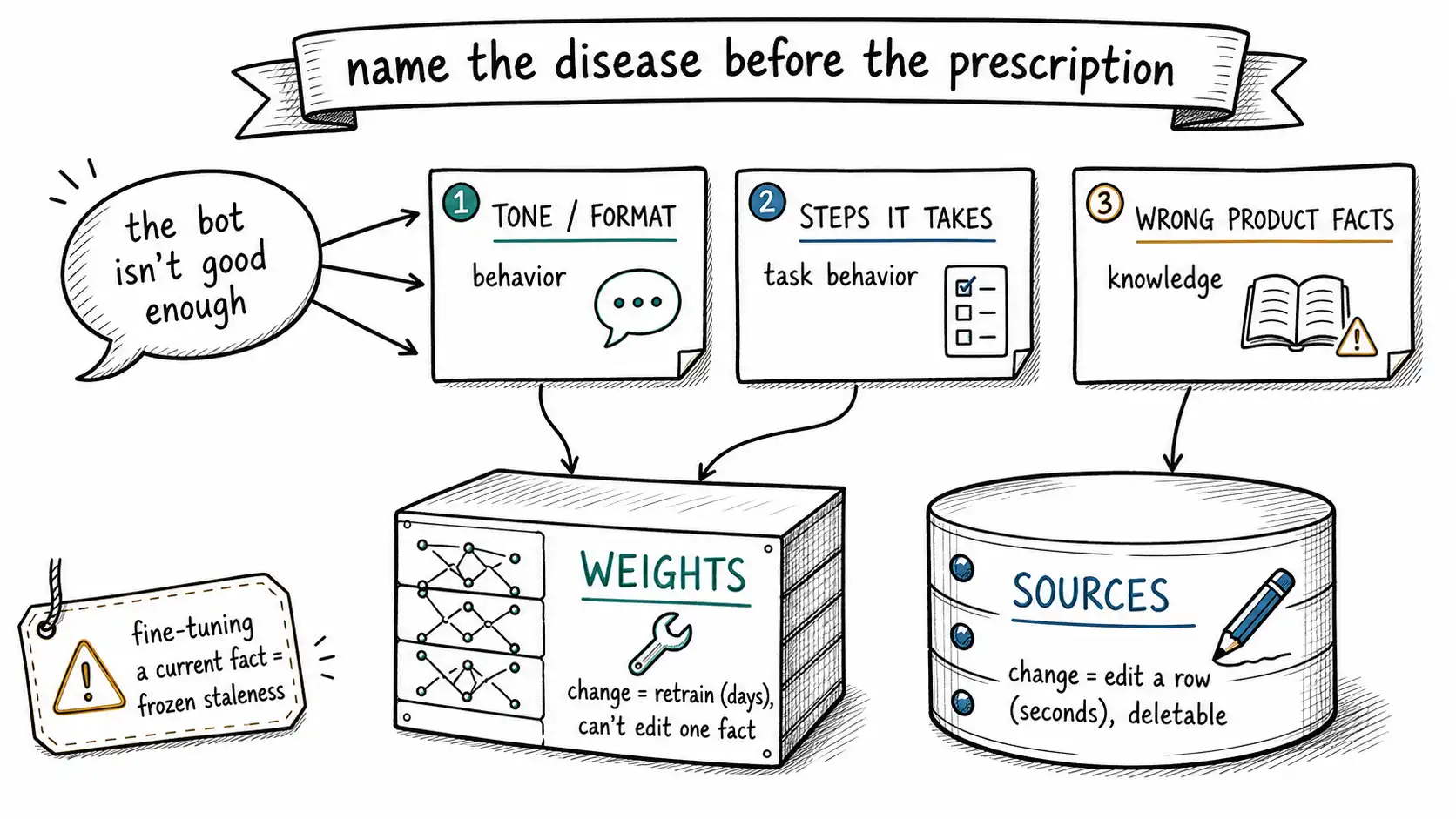
The support team's ailment, recall, was three complaints fused into one sentence. The assistant's tone was inconsistent. Its format drifted between prose and lists. And it gave answers that were out of date. Leadership experienced these as a single feeling, the bot isn't good enough, and the engineering team translated that feeling into a single action. The translation is where the error entered. Three complaints, one action, and the action could only ever address two of the three.
Behavior, knowledge, and why the seam matters
The most useful distinction in this entire book is the one between behavior and knowledge, so we will define both with precision and then keep returning to the seam between them.
Behavior is how the model responds: its tone, its format, the structure of its reasoning, its tool-use habits, its refusals, its house style, the way it phrases things in a domain. Behavior is a function of the weights, learned from the model's training and adjustable by further training. When you fine-tune, behavior is what you are editing. The support team's tone and format complaints were behavior complaints, and the fine-tune fixed them, exactly as the OpenAI supervised fine-tuning guide describes: supervised fine-tuning adjusts the weights to more reliably produce a desired style and content shape from input-output examples.
Knowledge is what the model treats as true about the world: facts, current state, who is allowed to do what, what the policy says today. Some knowledge is baked into a base model from pre-training, but it is frozen at the training cutoff and undifferentiated, the model does not know your current pricing, your customer's account balance, or this morning's policy change. That knowledge has to come from somewhere outside the weights, injected at inference time, which is the entire premise of retrieval-augmented generation as introduced by Lewis et al.: externalize the knowledge into a source you can update, and pull the relevant piece into the prompt when you need it.
The seam matters because the two have opposite operational properties:
| Property | Behavior (weights) | Knowledge (sources) |
|---|---|---|
| Where it lives | In the model's parameters | In a database, index, or document store |
| How you change it | Retrain (hours to days, plus eval) | Edit a row or document (seconds) |
| How you verify a change | Re-run the eval suite | Re-read the source |
| How you undo a bad change | Roll back to a previous checkpoint | Edit the row back |
| How you delete one fact | You can't, surgically, retrain | Delete the row |
| Cost of a stale value | Frozen until next retrain | Stale only until next edit |
Read that table as a list of reasons the support team's fine-tune backfired. They put a knowledge value, the product's current state, into the behavior column, and inherited every property of that column: it could only be changed by retraining, could not be edited or deleted surgically, and stayed stale until the next training run. A value that should have lived in the right-hand column, where it could be edited in seconds, was frozen into the left-hand column, where it could only be edited in days.
A taxonomy of what people actually mean
"Make it better" decomposes into more than two categories. Here is the full set this book will use, because naming the category is most of the diagnosis:
- Style: tone, voice, register, formality. Trainable. A real fine-tune target when the style is a genuine product requirement, not a nice-to-have (Chapter 6).
- Format: JSON shape, list vs. prose, field order, length discipline. Trainable, and often better solved first with structured-output constraints before you reach for training (Chapter 5).
- Task behavior: the steps the model takes for a recurring task: classify, extract, triage, summarize with a fixed structure. Trainable, often the strongest fine-tune case (Chapter 5).
- Domain skill: recognizing domain patterns, using jargon correctly, applying domain-specific reasoning. Partly trainable; partly a retrieval and prompting problem depending on whether the "skill" is pattern recognition (train) or fact lookup (retrieve).
- Tool discipline: calling the right tool, with the right arguments, at the right time, and not calling tools it should not. Trainable and frequently undervalued (Chapter 6).
- Current facts: pricing, inventory, this week's policy, the model number that replaced the old one. Not trainable in any maintainable way. Retrieve it.
- Business state: this user's plan, this ticket's status, this account's balance. Never trainable. It is per-request data; fetch it.
- Permissions, what this user is allowed to see or do. Never trainable. It is policy, enforced in code, checked per request.
- Fast-changing policy: refund windows, compliance rules, anything legal or product can change without an engineering cycle. Do not train it. Route it through a system that can change as fast as the policy does.
- Deletable private knowledge: anything a user can demand you forget. Do not train it, because you cannot surgically un-train one person's data; you would have to retrain to honor a deletion request (Chapter 16).
A symptom usually maps to several of these. The support bot mapped to style (train), format (train), and current facts (retrieve). The fix was never a single action. It was: fine-tune for style and format, and put the product knowledge behind retrieval so it could be updated without touching the model. The team did half the prescription and called it whole.
The same problem, three ways
To make the seam concrete, here is one task, "answer a question about our refund policy in the house voice as a short numbered list", solved three ways, with the failure mode each approach is prone to.
Prompt only. Put the current refund policy text and a style instruction in the system prompt.
SYSTEM = """You are Acme's support assistant. Answer in Acme's voice:
warm, concise, plain language. Always answer as a short numbered list.
Use ONLY the policy below. If the policy doesn't cover it, say so.
CURRENT REFUND POLICY (updated 2026-05-01):
{refund_policy_text}
"""
# Failure modes: style drifts over long sessions; if the policy text is
# long it competes for attention; updating policy means editing this string
# (fine, it's cheap) but the *style* is only as consistent as the prompt.Retrieval (RAG). Keep the style instruction in the prompt, but fetch the relevant policy passage at query time from a store you update whenever policy changes.
def answer(question: str) -> str:
passages = retrieve(question, index="policy", k=3) # current by construction
return model.generate(system=STYLE_PROMPT, context=passages, question=question)
# Failure mode: style is still prompt-dependent and can drift; retrieval can
# miss the right passage. But the knowledge is ALWAYS current - update the
# index, not the model. This is the right home for the "knows the product" need.Fine-tune. Train the model on examples of the house voice and the numbered-list format, then serve it.
# Training examples teach STYLE and FORMAT, never the policy CONTENT:
{"messages": [
{"role": "user", "content": "How long do I have to get a refund?"},
{"role": "assistant", "content": "1. You have a window to request a refund.\n2. Submit the request from Billing > Refunds.\n3. We confirm by email within one business day."}
]}
# Note: the example answer is deliberately CONTENT-FREE about the number of
# days. The duration is a CURRENT FACT and must come from retrieval at
# inference time. If you bake "30 days" into the training answer, you have
# just frozen a policy value into the weights - the original sin.
# Failure mode: if your examples leak current facts, you train staleness in.The three are not competitors here; they are layers. The mature answer is: fine-tune for style and format (behavior), retrieve for the policy text (knowledge), and never let a current fact appear as ground truth in a training example (see the OpenAI model optimization guide for how these layers compose in practice). That last clause is the lesson the support team paid for. Their tickets were full of current-at-the-time facts, pricing, page names, refund windows, and every one of those became a frozen training target.
The cost of the wrong intervention
It is tempting to think the cost of a misdiagnosis is just wasted effort: you fine-tuned, it didn't fully work, you move on. The real costs are larger and worth itemizing, because they are what justify spending a chapter on diagnosis.
| Wrong intervention | Direct cost | Hidden cost |
|---|---|---|
| Fine-tuned for knowledge | Training spend, eng time | Frozen staleness; can't edit facts; must retrain to update; can't honor deletion |
| Fine-tuned when prompting would do | Training spend, eval suite, ongoing retrains | Lost flexibility, a prompt edit becomes a training cycle |
| Skipped fine-tuning when it was right | Bloated prompts, higher per-call cost | Style/format never stabilizes; recurring prompt-engineering tax forever |
| Fine-tuned on contaminated data | Training spend | Confidently wrong behavior, hard to detect, shipped to everyone (Chapter 10) |
The asymmetry that runs through this whole book is visible in the first row. A wrong prompt is cheap to fix; you edit it and redeploy. A wrong fine-tune is expensive to fix; the error is distributed across the weights, invisible to inspection, recited confidently, and removable only by another training cycle. This is the precise sense in which fine-tuning is surgery, not seasoning: the intervention is powerful, but the recovery is slow and the mistakes are durable. The OpenAI fine-tuning best practices guidance to establish a baseline and an eval before you train exists for exactly this reason, to make sure the operation is indicated before you perform it.
Naming the disease before the prescription
The discipline this chapter asks for is small and unglamorous: before anyone writes "fine-tune" on a ticket, write down the symptom, then sort it into the taxonomy above. Most of the time the act of sorting reveals that the symptom is two or three things, at least one of which is not a training problem at all. The instruction tuning that gave us helpful assistants in the first place, InstructGPT, was a behavior intervention: it taught models to follow instructions and match human preferences about how to respond, not to know more facts. That is the canonical, successful fine-tune, and it is worth holding as the template for what training is for: changing how the model behaves, not what it knows.
Chapter summary
The reflex "we should fine-tune it" usually arrives before anyone has named what they are trying to change, and a single felt complaint ("the bot isn't good enough") almost always decomposes into several distinct categories. The most important distinction is behavior versus knowledge: behavior (tone, format, task steps, tool discipline, domain phrasing) lives in the weights and is the right thing to fine-tune; knowledge (current facts, business state, permissions, fast-changing policy, deletable private data) lives in sources and must be retrieved, fetched, or enforced in code, never frozen into a training run. The two columns have opposite operational properties, weights change in days and resist surgical edits or deletion, sources change in seconds, so misfiling a value into the wrong column inherits the wrong properties, which is exactly how the support bot ended up reciting last year's product flawlessly in the house voice. Solve the same task three ways (prompt, RAG, fine-tune) and the layers become clear: fine-tune for style and format, retrieve for the policy text, and never let a current fact appear as ground truth in a training example. The cost of misdiagnosis is not just wasted effort; it is frozen staleness, lost flexibility, and confident errors shipped to everyone, the recovery cost that makes fine-tuning surgery, not seasoning. The cheap, unglamorous discipline that prevents all of it is to write down the symptom and sort it into the taxonomy before writing "fine-tune" on the ticket.