Confidence, Self-Assessment, and Why Models Lie About Both
> **Working claim:** The most tempting escalation signal is the model's own confidence: "let the cheap model tell us when it's unsure." It is tempting because it is cheap and it is exactly what you wish existed.

Key Takeaways
- Confidence, Self-Assessment, and Why Models Lie About Both is a chapter about model routing and inference control planes, not a generic AI adoption note.
- The operating rule is to send each request to the cheapest path that still meets quality, latency, residency, and risk requirements.
- The failure mode to watch is polished output without evidence, owner, cost line, or rollback path.
- The useful next step is an artifact a future teammate can replay without folklore.
Model routing works when each request goes to the cheapest path that still meets quality, latency, residency, and risk requirements.
Working claim: The most tempting escalation signal is the model's own confidence: "let the cheap model tell us when it's unsure." It is tempting because it is cheap and it is exactly what you wish existed. It is also unreliable: models are confidently wrong, their stated confidence is poorly calibrated, and asking a model "are you sure?" produces a number that correlates more with phrasing than with correctness. Confidence signals can work, but only when you stop trusting the model's word and start measuring its behavior.
The dream and the disappointment
Here is the escalation signal everyone wants. Run the cheap model. Ask it how confident it is. If confidence is high, keep the cheap answer; if low, escalate. It is the perfect cascade trigger: it uses the answer itself (the strongest signal, per Chapter 3), it is one extra cheap question, and it sounds like exactly what calibration should give you. Teams build it in an afternoon and ship if confidence < 0.7: escalate.
The disappointment arrives in production. The escalation rate does not track the error rate. The cheap model says "I'm 95% confident" on answers that are wrong and "I'm not sure" on answers that are right. Worse, the number itself moves when you rephrase the question, ask "how confident are you?" versus "rate your certainty 0-100" versus "are you sure?" and you get different distributions on the same answers. The signal you built your cascade on turns out to be noise wearing a percentage sign.
This is not a bug in your prompt. It is a property of how language models produce confidence statements. A model asked to state its confidence is generating text that looks like a confidence statement, conditioned on the surface form of the question, not reading out a calibrated internal probability of correctness. The number is a plausible-sounding token sequence, and plausible-sounding is precisely the failure mode that makes models dangerous in the first place. Self-reported confidence inherits the model's overconfidence and adds a layer of prompt-sensitivity on top.
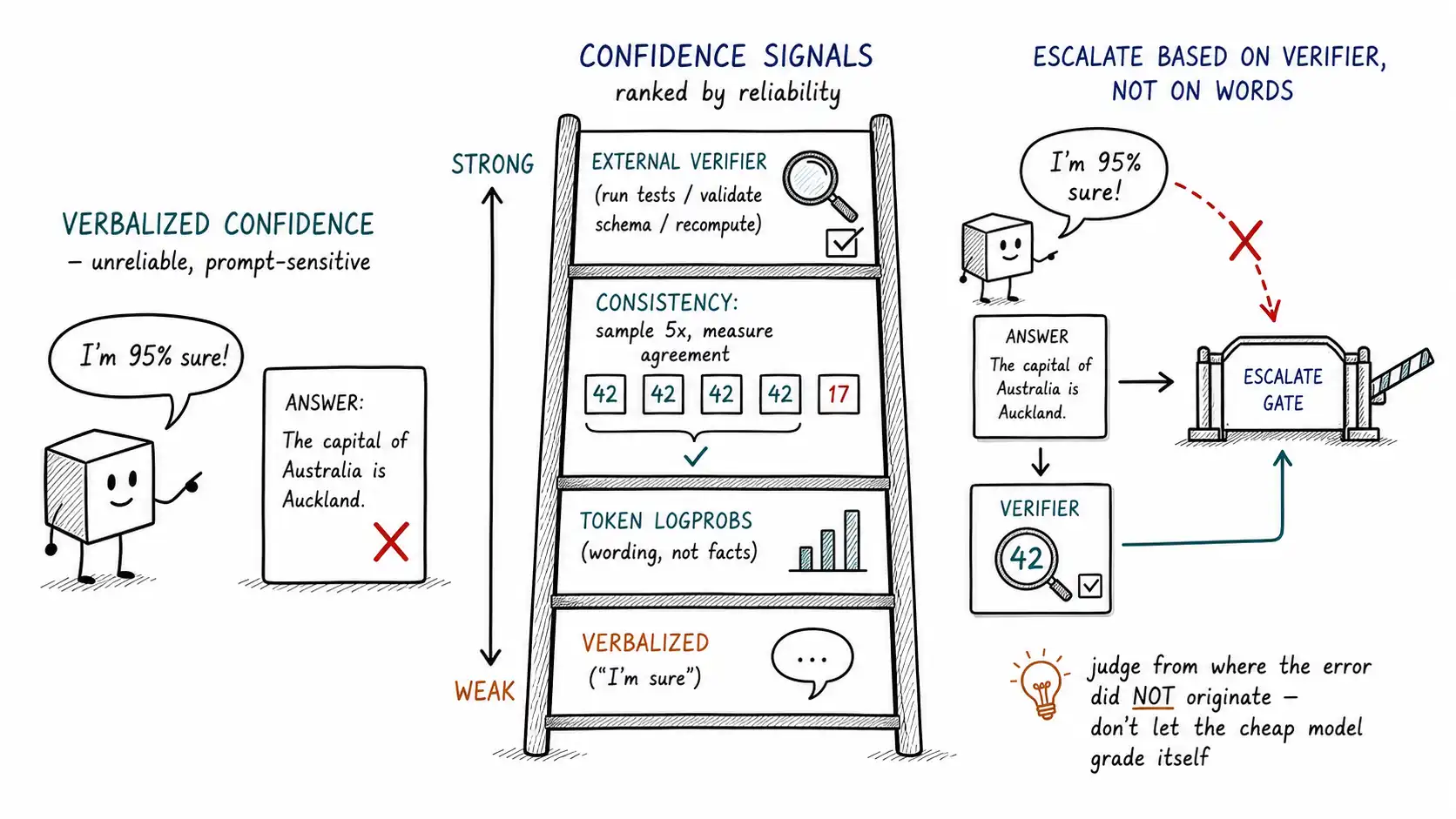
Three flavors of "confidence, " only some useful
"Confidence" is overloaded. Untangle three distinct things, because they have very different reliability.
Verbalized confidence is the model saying a number: "I am 90% confident." This is the least reliable. It is text generation about confidence, sensitive to phrasing, and typically overconfident. Use it, if at all, as a weak feature among many, never as a sole escalation trigger.
Token-probability confidence is the model's actual output-token probabilities (logprobs, where the provider exposes them). The probability the model assigned to the tokens it produced is a real internal signal, but it measures the model's confidence in the wording, not in the factual correctness, and the two diverge: a model can be highly confident in fluent prose that is factually wrong. Low token probability is a useful "the model is hedging/uncertain at the surface level" signal; high token probability is not a reliable "the answer is correct" signal. It is more trustworthy than verbalized confidence and still not a correctness oracle.
Consistency-based confidence is the most useful, and it does not ask the model how it feels at all. It samples the model multiple times (or compares the cheap model's answer against another model's) and measures agreement. If the model gives the same answer five times out of five, that answer is more likely to be stable and correct; if it gives five different answers, it is guessing. SelfCheckGPT is the canonical formalization: it detects hallucination zero-resource and black-box by sampling multiple responses and checking whether they are consistent with each other, on the principle that a model that knows an answer will be consistent and a model that is hallucinating will produce divergent samples. The key insight for routing is that consistency is a behavioral measure, what the model does across samples, not a verbal one, what it says about itself. Behavior is harder to fake than self-report.
| Confidence type | What it measures | Reliability for escalation | Cost |
|---|---|---|---|
| Verbalized ("I'm 90% sure") | Plausible text about confidence | Low; prompt-sensitive, overconfident | ~free (in the answer) |
| Token-probability (logprobs) | Confidence in wording, not facts | Medium; good for "hedging" detection | free if exposed |
| Consistency (multi-sample agreement) | Behavioral stability of the answer | Higher; behavioral, harder to fake | N× sampling cost |
| External verifier / validator | Whether answer passes an independent check | Highest for checkable tasks | cost of the check |
The verifier is better than the confessor
The deeper lesson, and the one that reframes the whole cascade design, is this: do not ask the model to confess uncertainty; build a verifier that checks the answer. For many tasks the verifier is cheap and far more reliable than any self-report, because it is grounded in something external to the model.
- Code: run the code. Does it compile? Do the tests pass? A failing test is a far better escalation signal than "the model wasn't confident."
- Structured output: does the JSON parse and validate against the schema? Does the extracted date fall in a plausible range? Schema violation is a hard, reliable escalation trigger.
- Arithmetic / calculations: recompute with a deterministic tool. Disagreement is unambiguous.
- Retrieval-grounded answers: is every claim supported by a retrieved passage? An unsupported claim is a hallucination signal, and SelfCheckGPT's consistency check is the unsupervised version when you have no ground truth to check against.
- Constraint satisfaction: does the answer obey the stated constraints (length, format, forbidden content)? A violated constraint escalates.
The cascade's stopping rule should be a verifier, not a confidence number, whenever the task admits a verifier. FrugalGPT makes this concrete: its cascade uses a learned scorer on the cheap model's output to decide whether to stop or escalate, an external judge of the answer, not the model's self-assessment. The scorer can be a small trained model, a rule, or another LLM acting as a grader, but the point is it is separate from the generator and judges the output, which is the strongest signal available.
# A cascade whose escalation trigger is a VERIFIER, not self-reported confidence.
# Confidence-as-self-report is at most a tiebreaker, never the sole trigger.
def cascaded_answer(request):
answer = call(request, model="small-hosted")
# Strongest first: task-specific verifier grounded in something external.
verdict = verify(request, answer) # returns PASS / FAIL / UNSURE
if verdict == "PASS":
return answer
if verdict == "FAIL":
return call(request, model="flagship") # escalate on hard evidence
# UNSURE: the verifier couldn't decide. Now use a BEHAVIORAL signal.
samples = [call(request, model="small-hosted", temperature=0.7) for _ in range(3)]
if consistent(samples + [answer]): # SelfCheckGPT-style agreement
return answer # stable -> trust the cheap answer
return call(request, model="flagship") # divergent -> the model is guessing
def verify(request, answer):
if request.task_type == "code":
return "PASS" if run_tests(answer) else "FAIL"
if request.expects_json:
return "PASS" if validates(answer, request.schema) else "FAIL"
if request.is_retrieval_grounded:
return "PASS" if all_claims_supported(answer, request.context) else "FAIL"
return "UNSURE" # no external check availableNotice the ordering: a grounded verifier first, then a behavioral consistency check, and nowhere a bare if model_says_confident. Verbalized confidence has been demoted out of the decision entirely, replaced by what the answer is (verifier) and what the model does across samples (consistency).
When you must use a confidence number, calibrate it
Sometimes there is no verifier and consistency sampling is too expensive (latency-tight interactive requests cannot afford three extra calls). If you must use a confidence number, do not use the raw number, calibrate it against measured correctness on your own data. Calibration means: collect a set of (stated-confidence, was-it-actually-right) pairs, bucket them, and check whether the model's "0.9" answers are right about 90% of the time. They almost never are out of the box; a model's stated 0.9 might correspond to 0.6 actual accuracy. Once you have the mapping, you can transform raw confidence into a calibrated estimate, and crucially, you can set the escalation threshold against the calibrated number, not the raw one.
This is the same discipline the OpenAI evals guide prescribes for any model output you depend on: measure it against ground truth on your task rather than trusting the model's self-description. A confidence signal is just another model output, and like every model output it must be evaluated before it is trusted. The deliverable is a reliability curve for each cheap model's confidence on each task type, and the escalation threshold is read off that curve to hit a target false-cheap rate.
-- Calibration check: do the cheap model's stated-confidence buckets
-- actually predict correctness? Run this before trusting any confidence threshold.
SELECT
width_bucket(stated_confidence, 0, 1, 10) AS conf_bucket, -- 10 buckets of 0.1
count(*) AS n,
avg(stated_confidence) AS mean_stated,
avg(case when was_correct then 1.0 else 0.0 end) AS actual_accuracy
FROM routing_outcomes
WHERE model = 'small-hosted' AND task_type = 'support.billing'
GROUP BY conf_bucket
ORDER BY conf_bucket;
-- If mean_stated >> actual_accuracy in the high buckets, the model is
-- overconfident and a raw-confidence escalation threshold is unsafe.The trap of the cheap model judging itself
One last failure mode, because it is subtle and common. A natural design is to have the cheap model both answer and assess its own answer. This is doubly weak: the cheap model is the one whose judgment you already distrust (that is why you might escalate), and asking it to grade its own work invites the same overconfidence that produced the wrong answer. If you use a model as a verifier, it is often better to use a different model, frequently a stronger one as a cheap grader (grading is easier than generating, so a strong model can grade quickly), or a small specialist verifier trained for the task. RouteLLM's design avoids the self-judgment trap entirely by training the router on external human-preference data, learning when the weak model loses to the strong one from labeled comparisons, not from asking the weak model to introspect. The general principle: judgment should come from somewhere the failure being judged did not originate. A model grading itself is a witness vouching for its own testimony.
Chapter summary
Self-reported confidence is the escalation signal everyone wants and the one that disappoints in production, because a model stating "I'm 90% sure" is generating text about confidence, overconfident and sensitive to phrasing, not reading out a calibrated probability of correctness. Untangle three flavors: verbalized confidence (weakest, prompt-sensitive), token-probability confidence (real but measures confidence in wording, not facts, good for hedging detection, not a correctness oracle), and consistency-based confidence (strongest of the three because it is behavioral: sample the model several times and measure agreement, the SelfCheckGPT principle that a model which knows is consistent and a model that hallucinates diverges). The deeper reframe is to stop asking the model to confess and instead build a verifier grounded in something external, run the code, validate the schema, recompute the arithmetic, check claims against retrieved passages, which is exactly the learned scorer FrugalGPT's cascade stops on. So the cascade's escalation trigger should be a verifier first, a behavioral consistency check second, and bare verbalized confidence never; when you genuinely must use a confidence number (no verifier, latency too tight to sample), calibrate it against measured correctness on your own data and set the threshold on the calibrated value, because raw stated confidence systematically overstates accuracy. Finally, never let the cheap model grade itself, judgment should come from where the error did not originate, whether a stronger model as a cheap grader, a specialist verifier, or RouteLLM-style external preference labels.
Internal map
For the larger argument, keep this chapter connected to Model Routing, The Economics of Inference, the smaller-model margin argument, and A Field Guide to Evals.