The Confusion Matrix Has Four Boxes, Not Two
> **Working claim:** A router can make every individual model look fine while the system fails, because the unit of evaluation is not the model output, it is the *routing decision*.

Key Takeaways
- The Confusion Matrix Has Four Boxes, Not Two is a chapter about model routing and inference control planes, not a generic AI adoption note.
- The operating rule is to send each request to the cheapest path that still meets quality, latency, residency, and risk requirements.
- The failure mode to watch is polished output without evidence, owner, cost line, or rollback path.
- The useful next step is an artifact a future teammate can replay without folklore.
Model routing works when each request goes to the cheapest path that still meets quality, latency, residency, and risk requirements.
Working claim: A router can make every individual model look fine while the system fails, because the unit of evaluation is not the model output, it is the routing decision. The right instrument is a four-box confusion matrix: cheap-and-right, cheap-and-wrong, escalated-and-needed, escalated-and-wasted. Two of those boxes are the errors, and they are not symmetric, false-cheap is a quality and safety failure, false-expensive is a cost failure, so you cannot optimize a router with a single accuracy number.
Evaluating the decision, not the model
The most common evaluation mistake in a routed system is to evaluate the models and conclude the system is fine. The cheap model scores 80% on its eval set; the flagship scores 95%; both are "working." But the system's quality depends not on either model's standalone score, it depends on whether the router sent each request to the right one. A router that sends every hard request to the cheap model produces a system that fails even though both models are individually healthy. The models are fine; the decisions are wrong. So the unit of evaluation must be the routing decision: for each request, was choosing this model the right call?
This reframing changes what "ground truth" means. For a model eval, ground truth is the correct answer. For a router eval, ground truth is the correct decision, which model should have handled this request, given its difficulty, risk, and the slice's quality bar. That label is harder to produce (it requires knowing how each candidate model would have done), and producing it is what shadow routing (Chapter 14) is for. But the conceptual move comes first: stop grading the answer in isolation and start grading the choice.
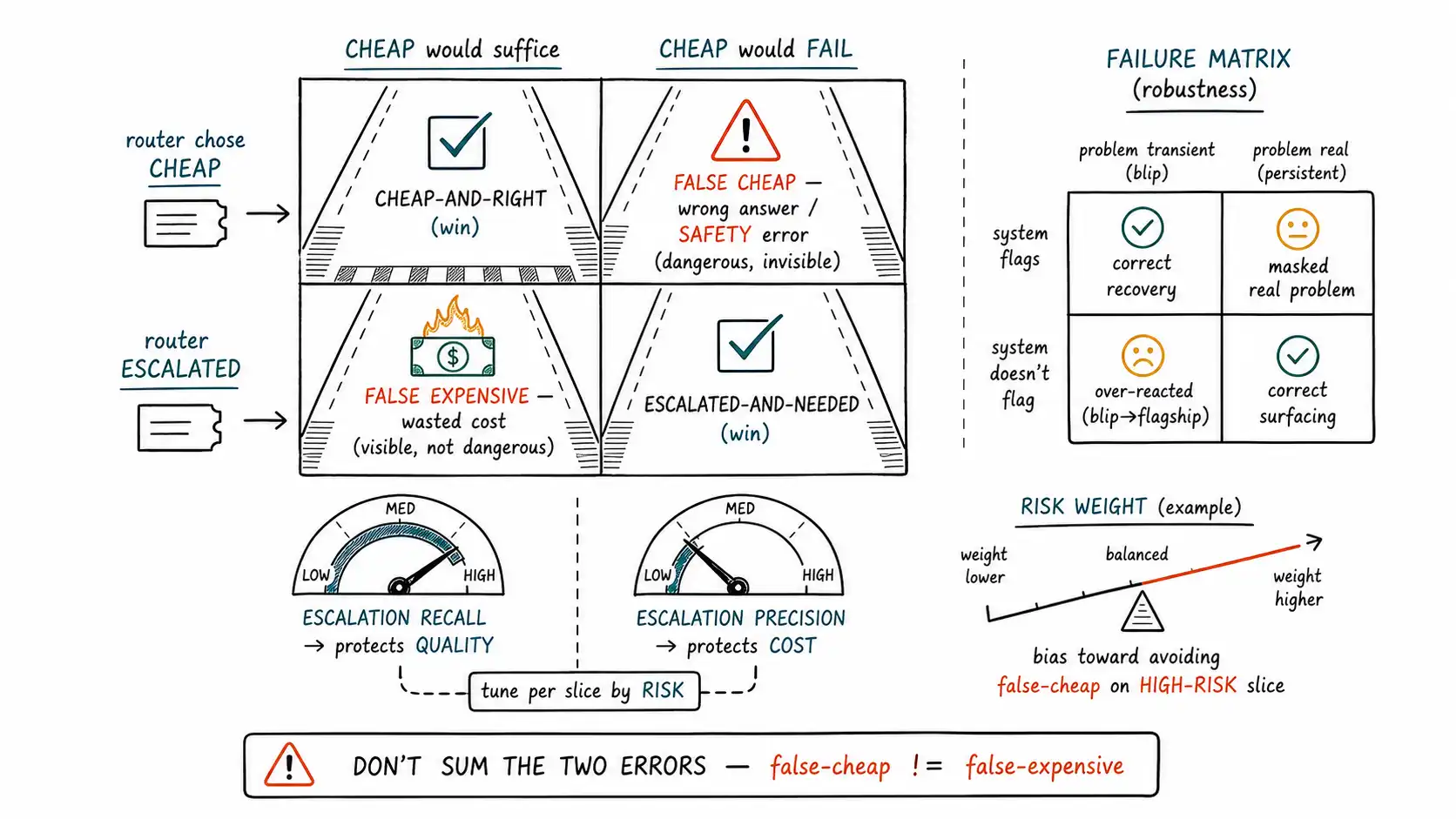
The four boxes
A binary routing decision (cheap vs. escalate) crossed with whether escalation was actually needed gives four outcomes, not two. This is the routing confusion matrix, and it is the chapter's central instrument.
| Cheap would have sufficed | Cheap would have failed | |
|---|---|---|
| Router chose cheap | ✅ Cheap-and-right (correct cheap) | ❌ Cheap-and-wrong (false cheap) |
| Router escalated | ❌ Escalated-and-wasted (false expensive) | ✅ Escalated-and-needed (correct escalation) |
The two green boxes are the wins: the router used the cheap model when it sufficed and the strong model when it was needed. The two red boxes are the errors, and the entire art of router evaluation is in recognizing that they are not the same kind of error.
- Cheap-and-wrong (false cheap): the router sent a request to the cheap model that the cheap model got wrong. This is a quality failure and, on a high-risk slice, a safety failure. It is the dangerous error from Chapter 5, invisible at routing time, surfacing as a wrong answer, a complaint, or an incident.
- Escalated-and-wasted (false expensive): the router escalated a request the cheap model would have handled fine. This is a cost failure, you paid for the strong model unnecessarily. Annoying, visible on the bill, but not dangerous.
A single "router accuracy" number adds these two boxes together as if they were equivalent, and they are not. One is a wrong answer; the other is an unnecessary dollar. A router with 5% false-cheap and 0% false-expensive is worse than one with 0% false-cheap and 5% false-expensive, even though both have "10% error", because the first ships wrong answers and the second just overspends. Conflating them is how teams optimize a router into being cheap and dangerous.
Precision and recall of escalation
The asymmetry maps onto a vocabulary the OpenAI evals guide and classifier evaluation share: precision and recall, applied to the escalation decision (treating "escalate" as the positive class).
- Escalation recall = of the requests that needed the strong model, what fraction did the router escalate? Low recall means false-cheap errors (the router missed requests that needed escalating). Recall protects quality.
- Escalation precision = of the requests the router escalated, what fraction actually needed it? Low precision means false-expensive errors (the router escalated requests that did not need it). Precision protects cost.
The router's operating point trades recall against precision, and, crucially, the right tradeoff is per-slice and risk-dependent (Chapter 5 again). On a high-risk slice you want high escalation recall even at the cost of precision: escalate aggressively, accept some waste, never miss a request that needed the strong model. On a low-risk high-volume slice you want high precision even at the cost of recall: escalate stingily, accept the occasional cheap-and-wrong, because a wrong answer there is cheap and an unnecessary escalation at that volume is expensive. A single global threshold cannot serve both, which is why Chapter 9's cascade threshold and Chapter 8's policy were per-slice.
# Computing the four-box matrix and the asymmetric metrics from labeled outcomes.
# Each outcome needs: did the router escalate? would cheap have sufficed?
def routing_confusion_matrix(outcomes):
boxes = {"cheap_right": 0, "cheap_wrong": 0, "escalated_needed": 0, "escalated_wasted": 0}
for o in outcomes:
if not o.escalated:
boxes["cheap_right" if o.cheap_would_suffice else "cheap_wrong"] += 1
else:
boxes["escalated_needed" if not o.cheap_would_suffice else "escalated_wasted"] += 1
return boxes
def escalation_metrics(boxes):
needed = boxes["escalated_needed"] + boxes["cheap_wrong"] # all that needed strong
escalated = boxes["escalated_needed"] + boxes["escalated_wasted"] # all escalations
recall = boxes["escalated_needed"] / needed if needed else 1.0 # protects QUALITY
precision = boxes["escalated_needed"] / escalated if escalated else 1.0 # protects COST
return {"escalation_recall": recall, "escalation_precision": precision,
"false_cheap_rate": boxes["cheap_wrong"] / sum(boxes.values()),
"false_expensive_rate": boxes["escalated_wasted"] / sum(boxes.values())}The function reports both error rates separately, never summed. That separation is the deliverable, a dashboard that shows false-cheap and false-expensive as distinct lines, because they have different owners (quality/safety vs. finance) and different acceptable thresholds.
Getting the labels: would cheap have sufficed?
The matrix needs a label that is genuinely hard to obtain: for a request the router escalated, would the cheap model have sufficed? (and vice versa). You did not run the cheap model on the escalated requests, so you do not directly know. Three ways to get the label, in increasing cost:
- Shadow execution (Chapter 14): run the other model in the background on a sample of requests, without serving its output, purely to label. For an escalated request, shadow-run the cheap model and grade it; now you know whether escalation was needed. This is the cleanest source and the reason shadow routing exists.
- Verifier as proxy: if you have a reliable verifier (Chapter 6/9), apply it to both models' outputs on a sample. The verifier's verdict on the cheap output is a proxy for "would cheap have sufficed."
- Human labeling on a sample: for slices where no verifier exists (subjective quality), humans label a sample of decisions, the RouteLLM preference-data approach turned into evaluation rather than training.
The honest constraint: you can rarely afford to label every request, so you label a sample and estimate the matrix from it. That is fine, a well-sampled estimate of the four boxes is far more useful than an exact count of a single accuracy number. The OpenAI evals guide emphasis on building task-appropriate graders applies directly: the grader that decides "would cheap have sufficed" is the most important eval component in a routed system, and it must match the slice's actual quality bar (Chapter 1's per-slice "correct enough").
The failure matrix as the operational complement
The four-box confusion matrix grades routing quality; a parallel four-box failure matrix grades routing robustness, crossing whether a failure occurred with whether the router handled it correctly. This is the Chapter 3/10 fallback territory turned into an evaluation instrument.
| Failure was transient (retry would work) | Failure was real (capability/policy) | |
|---|---|---|
| Router retried/failed-over | ✅ Correct recovery | ❌ Masked a real problem (retried a content refusal) |
| Router escalated/surfaced | ❌ Over-reacted (escalated a blip to flagship) | ✅ Correct escalation/surfacing |
The off-diagonal errors here are the Chapter 3 confusions made measurable: masking a real problem (retrying a safety refusal until it "passes, " or failing over a genuine capability failure into a wrong answer) and over-reacting (escalating every transient timeout to the flagship, the cost blowup). A mature router tracks both matrices, because a router can have a beautiful quality matrix and a terrible failure matrix, perfect routing decisions and a retry storm that bankrupts it during an outage.
Why this connects to risk governance
The asymmetry of the four boxes is, at bottom, a risk-governance statement, and it is why the NIST AI Risk Management Framework's impact-weighted view of risk belongs in router evaluation. A false-cheap error on a low-risk slice is a minor quality blip; a false-cheap error on a high-risk slice is a potential harm event. So the matrix should be weighted by risk: a false-cheap on a high-risk slice counts for far more than ten false-cheaps on low-risk slices. The single most important number a routed system can report to a risk reviewer is not its average accuracy or its cost savings, it is its false-cheap rate on high-risk slices, because that is the number that turns into incidents. Chapter 13's regret metric generalizes this into a single cost-weighted score, but the four-box matrix is where the asymmetry is first made visible, and making it visible is the prerequisite for governing it.
Chapter summary
A router can leave every model individually healthy while the system fails, because the unit of evaluation is the routing decision, not the model output, ground truth becomes "which model should have handled this, " not "what is the correct answer." A binary cheap-vs-escalate decision, crossed with whether escalation was actually needed, yields a four-box confusion matrix: two wins (cheap-and-right, escalated-and-needed) and two errors that are not symmetric, false-cheap (cheap-and-wrong) is a quality and, on risky slices, safety failure that is invisible at routing time, while false-expensive (escalated-and-wasted) is a merely visible cost failure. A single "router accuracy" number sums these as if equal and is therefore useless; report them separately, as escalation recall (protects quality, catch everything that needed the strong model) and escalation precision (protects cost, don't escalate what didn't), tuned per slice by risk: high recall on high-risk slices, high precision on low-risk high-volume ones. The matrix needs a hard label: "would cheap have sufficed?", obtained from shadow execution (Chapter 14), a verifier proxy, or human sampling, estimated from a sample rather than computed exhaustively. A parallel failure matrix grades robustness (correct recovery vs. masking a real problem vs. over-reacting to a blip), and a mature router tracks both because perfect decisions plus a retry storm still bankrupts you. Finally, the asymmetry is a risk-governance statement: weight the matrix by risk and report false-cheap rate on high-risk slices as the number that turns into incidents, the NIST AI RMF impact-weighting that Chapter 13's regret metric will fold into a single score.
Internal map
For the larger argument, keep this chapter connected to Model Routing, The Economics of Inference, the smaller-model margin argument, and A Field Guide to Evals.