Prompt Length Is a Liar
This chapter turns prompt length is a liar into a concrete operating problem for the routing book.

Key Takeaways
- Prompt Length Is a Liar is a chapter about model routing and inference control planes, not a generic AI adoption note.
- The operating rule is to send each request to the cheapest path that still meets quality, latency, residency, and risk requirements.
- The failure mode to watch is polished output without evidence, owner, cost line, or rollback path.
- The useful next step is an artifact a future teammate can replay without folklore.
Model routing works when each request goes to the cheapest path that still meets quality, latency, residency, and risk requirements.
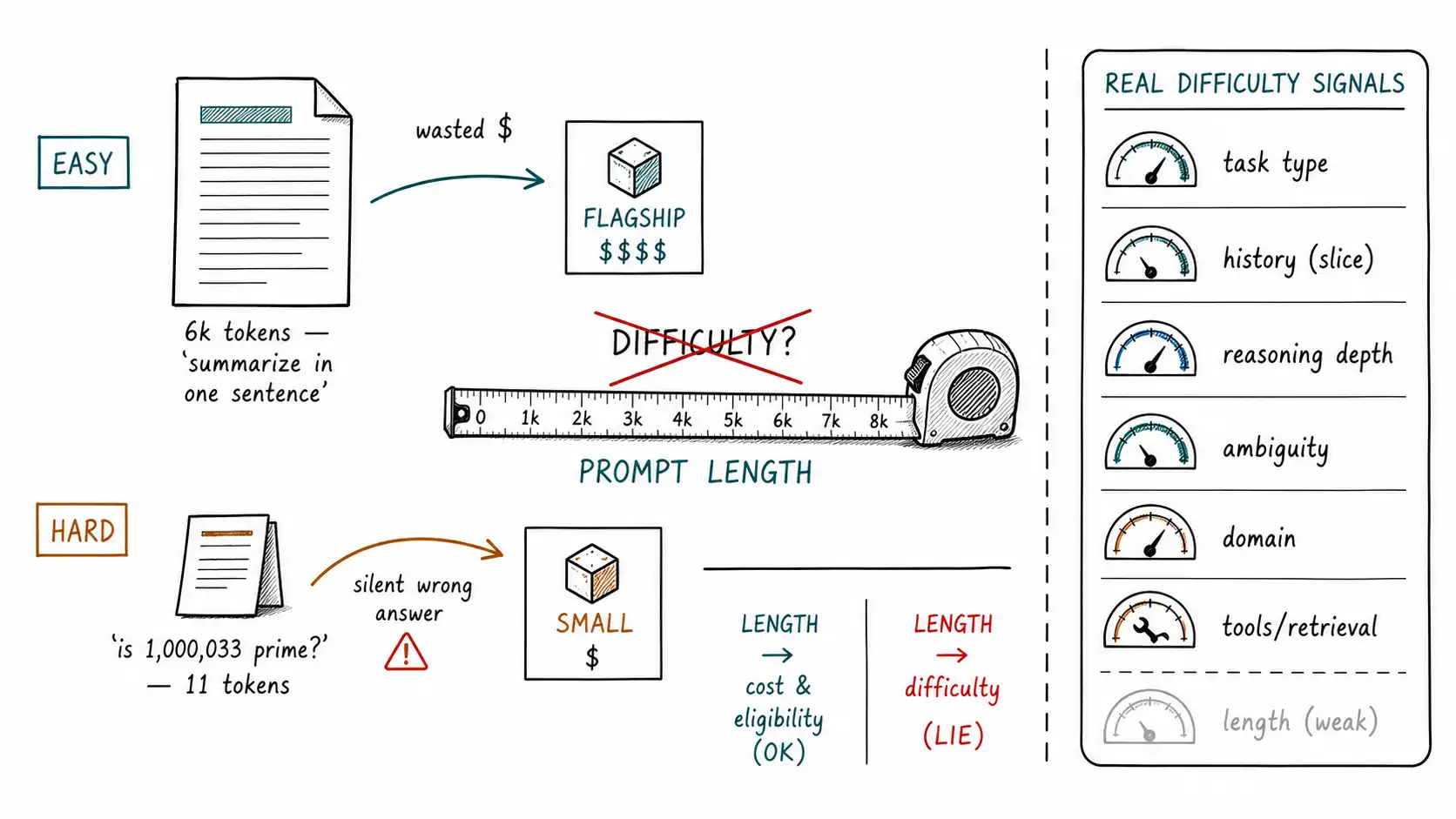
Working claim: The first routing signal every team reaches for is prompt length: "long prompts are hard, send them to the big model." It is the wrong signal for difficulty in both directions: it routes long-but-easy requests to expensive models for nothing, and it routes short-but-hard requests to cheap models that fail them. Length correlates with cost, which is real and useful, but it barely correlates with difficulty, which is what the router actually needs.
The seductive heuristic
Almost every routing system starts the same way. Someone writes if token_count(prompt) > 8000: model = "flagship" and ships it, because it is one line, it is intuitive, and it captures a real correlation: long prompts cost more, and "more expensive request" feels like it should mean "harder request." The heuristic survives because it is sometimes right and always cheap to compute, you can count tokens without calling any model. But "sometimes right and cheap" is exactly the profile of a signal that lulls a team into not measuring whether it is right on their traffic, and on most traffic it is wrong often enough to matter.
The error has a clean structure. Length is a good proxy for cost: more tokens, more money, by definition. It is a poor proxy for difficulty: whether a cheap model will get the answer right. Difficulty and length are different things that happen to be loosely correlated, and a router that uses length as a difficulty signal is using a cost variable to make a quality decision. The two failures fall out immediately.
Failure one: long but easy
Plenty of long prompts are trivial. Consider these, all of which a small model handles perfectly despite being thousands of tokens long:
- "Here is a 6,000-token customer email thread. Summarize the customer's main request in one sentence." A small model reads the thread and extracts the ask; length does not make extraction hard.
- "Below is a 10, 000-token log file. List every line containing the word ERROR." This is mechanical pattern-matching; the cheapest model on earth does it.
- "Here are 4,000 tokens of product reviews. What is the overall sentiment?" Aggregating sentiment over many short, redundant signals is easier with more data, not harder.
A length-threshold router sends all three to the flagship and pays the flagship tax for nothing. The requests are long because the input is long, and the task is easy. Routing on length conflates input size with task complexity, and over a workload with many long-but-easy requests, which is most document-processing workloads, it systematically over-spends. This is the false-expensive error from the confusion matrix in Chapter 12: routing to a big model when a cheap one would have done.
Failure two: short but hard
The mirror failure is worse because it is silent. Plenty of short prompts are brutal:
- "Is 1,000, 033 prime?" Eleven tokens. A small model will answer confidently and often wrongly; the arithmetic is hard regardless of length.
- "A train leaves Chicago at 2: 15pm traveling west at 60mph; another leaves Denver at 3: 40pm…" A few dozen tokens of multi-step reasoning that small models routinely botch.
- "Given the clause 'notwithstanding the foregoing, ' does Section 4 override Section 2?" Short, but it requires careful legal reasoning a cheap model fakes fluently.
- "Refactor this 15-line function to be thread-safe." Short input, genuinely hard correctness requirement.
A length-threshold router sends all of these to the cheap model because they are short, and the cheap model produces a confident wrong answer. This is the false-cheap error, and it is the dangerous one, because the failure is invisible at routing time, there is no exception, no timeout, just a wrong answer delivered smoothly. The router congratulates itself on the cheap path while quietly poisoning the hard slice.
RULER is the cleanest research demonstration that length and difficulty are orthogonal in exactly this way. It shows that a model's effective capability on a task collapses as the task gets harder at the same length, that a model handling simple retrieval over a long context can fail aggregation or multi-hop reasoning over the same context. Length held constant, difficulty varied, performance swung wildly. The corollary for routing is direct: you cannot read difficulty off length, because the same length spans the full range of difficulty.
Length is still a real signal: for cost and capacity
The fix is not to throw length away. Length is genuinely informative about two things the router must know, just not the thing it is usually used for.
First, cost. Length is cost (Chapter 15), and the router's cost estimate must use it. A long request is expensive on every model, which changes the cost-benefit of escalation: escalating a 50-token request to the flagship is cheap; escalating a 50, 000-token request is not, and the router should weigh that.
Second, capacity and capability-at-length. Some models cannot accept the request at all (it exceeds their window), and some models degrade at length even on easy tasks, the RULER effective-context result. So length gates eligibility: a request near a model's effective limit for its task type should not route to that model regardless of how easy the task is in the abstract, because the model's usable capability there is lower than its sticker window suggests.
So length informs the cost term and the eligibility gate, and it is nearly useless as the difficulty term. The mistake is using one number for all three.
# Length used correctly: for cost and eligibility, NOT for difficulty.
def eligible_models(request, fleet):
n_tokens = count_tokens(request.prompt) # measured, not estimated
task = request.task_type
out = []
for m in fleet:
# Eligibility: can this model actually handle this length on this task?
if n_tokens > m.effective_context_for(task): # from your RULER-style measurement
continue # length gates eligibility
out.append(m)
return out
def estimate_cost(request, model):
n_in = count_tokens(request.prompt)
n_out = expected_output_tokens(request.task_type)
return model.price_in * n_in + model.price_out * n_out # length drives cost
def estimate_difficulty(request):
# Length is NOT here. Difficulty comes from task type, ambiguity,
# reasoning depth, history - Chapters 5-7. Length is at most a weak feature.
return difficulty_model.predict(features_without_length(request))The separation is the whole lesson: eligible_models and estimate_cost use length; estimate_difficulty does not. A router that respects this separation stops over-spending on long-but-easy requests and stops under-serving short-but-hard ones, because the difficulty decision is no longer hostage to the input size.
What actually predicts difficulty
If not length, then what? The honest answer is that difficulty is multi-signal and the next three chapters are about it, but here is the preview, ranked roughly by how much signal each carries in practice.
| Signal | What it captures | Strength | Cost to compute |
|---|---|---|---|
| Task type | Arithmetic, code, legal, summarization have different base difficulty | Strong | Free (classify intent) |
| Historical slice performance | What cheap models actually did on requests like this | Strongest | Needs logged outcomes (Ch. 7) |
| Reasoning depth required | Multi-step / multi-hop vs. single lookup | Strong | Hard to detect pre-generation |
| Ambiguity | Underspecified requests that need clarification | Medium | Detectable, noisy |
| Domain sensitivity | Specialized vocabulary, niche knowledge | Medium | Classifiable |
| Need for tools / retrieval | External computation or lookup required | Medium | Often detectable from task |
| Cheap-model self-assessment | The model's own confidence | Weak / unreliable | Costs a cheap call (Ch. 6) |
| Prompt length | Input size | Weak for difficulty | Free |
Notice prompt length is at the bottom of the difficulty column despite being at the top of most teams' first router. Notice also that the strongest signal, historical slice performance, is not free; it requires that you logged what happened (Chapter 1's decision log, Chapter 7's slices). This is the recurring tension of routing signals: the cheap signals are weak, and the strong signals require infrastructure. The length heuristic is popular precisely because it is the only free and immediate signal, and teams reach for it before they have built the infrastructure for better ones.
A test that catches the length trap
Because the length trap is silent, you need a test that surfaces it. Build a small adversarial difficulty set: requests deliberately chosen to break the length-difficulty correlation, long-but-trivial and short-but-hard, and check that your difficulty estimator (and the routes it produces) handles them correctly. This is a direct application of the OpenAI evals guide discipline of building task-specific evals that probe the failure mode you care about, not just average performance.
# A fixture that specifically attacks the length-as-difficulty assumption.
length_trap_cases = [
# (prompt, true_difficulty, note)
(long_log_grep, "easy", "10k tokens, mechanical pattern match"),
(long_thread_summary, "easy", "6k tokens, single-sentence extraction"),
(prime_check_short, "hard", "11 tokens, real arithmetic"),
(legal_clause_short, "hard", "short, needs careful reasoning"),
(threadsafe_refactor, "hard", "short input, hard correctness"),]
def test_difficulty_estimator_ignores_length(estimator):
errors = []
for prompt, truth, note in length_trap_cases:
pred = "hard" if estimator.predict(prompt) > 0.5 else "easy"
if pred!= truth:
errors.append((note, pred, truth))
# A length-based estimator will get ALL of these backwards.
assert not errors, f"length trap not handled: {errors}"If your difficulty estimator is secretly just a length threshold, this test fails on every row, in both directions, which is exactly the diagnostic you want: it tells you your "difficulty" signal is a cost signal wearing a costume.
Chapter summary
Prompt length is the first routing signal every team reaches for and the wrong one for difficulty, because it conflates input size with task complexity: two loosely correlated but distinct things. The error is two-sided: long-but-easy requests (log greps, thread summaries, sentiment over many reviews) get routed to expensive models for nothing, the false-expensive error, and short-but-hard requests (prime checks, multi-step word problems, legal-clause reasoning, thread-safety refactors) get routed to cheap models that fail them silently, the dangerous false-cheap error. RULER is the clean demonstration that length and difficulty are orthogonal: at a fixed length, performance swings wildly as task difficulty changes, so you cannot read difficulty off length. The fix is not to discard length but to use it for what it actually predicts, cost (length is cost) and eligibility/capability-at-length (models degrade or refuse near their effective limit), while sourcing difficulty from the signals that carry it: task type, historical per-slice performance (strongest, but needs logging), reasoning depth, ambiguity, domain, and tool/retrieval needs, with length at the bottom of that list. Because the false-cheap error is invisible at routing time, build an adversarial length-trap fixture of long-but-easy and short-but-hard cases; a difficulty estimator that is secretly a length threshold fails every row, which is the diagnostic that tells you your difficulty signal is a cost signal in costume.
Internal map
For the larger argument, keep this chapter connected to Model Routing, The Economics of Inference, the smaller-model margin argument, and A Field Guide to Evals.