Shadow Routing and Online Evaluation
> **Working claim:** Offline evaluation tells you how the router *did* on yesterday's data.

Key Takeaways
- Shadow Routing and Online Evaluation is a chapter about model routing and inference control planes, not a generic AI adoption note.
- The operating rule is to send each request to the cheapest path that still meets quality, latency, residency, and risk requirements.
- The failure mode to watch is polished output without evidence, owner, cost line, or rollback path.
- The useful next step is an artifact a future teammate can replay without folklore.
Working claim: Offline evaluation tells you how the router did on yesterday's data. Production is not yesterday's data: traffic drifts, providers silently upgrade models, prices change, and the slice performance your policy was built on quietly goes stale. Shadow routing and online evaluation are how a router keeps measuring itself against a moving world, collecting the counterfactual labels regret needs, and catching the drift that turns a good policy into a wrong one.
The label problem, and shadow routing as its answer
Chapter 13 needed a dataset with every model's outcome on every request to compute regret. Chapter 12 needed to know "would the cheap model have sufficed?" for requests the router escalated. Both need a counterfactual, what the model you didn't serve would have done, and you cannot get a counterfactual from production logs alone, because production only records the path you took. Shadow routing manufactures the counterfactual: it runs the un-served model in the background on a sample of requests, grades its output, and records the result, without serving that output to the user.
Shadow routing is the labeling engine of the whole evaluation movement. For an escalated request, shadow-run the cheap model and grade it: now you know whether escalation was needed (the Chapter 12 label). For a cheap-served request, occasionally shadow-run the strong model: now you know whether the cheap answer was as good as the strong one (regret label). Over time the shadow stream populates the router_eval table from Chapter 13 with the counterfactual outcomes that make oracle comparison possible. Without shadow routing, a routed system is flying blind on its own decisions, it knows what it did and never what it should have done.
# Shadow routing: serve one model, label others in the background.
# The user gets the served answer immediately; shadows run async, never block.
def serve_with_shadow(request, sample_rate=0.05):
served_model = router.choose(request)
served_answer = call(request, model=served_model)
respond_to_user(served_answer) # user is served NOW
if random() < sample_rate: # sample, don't shadow everything
shadow_models = eligible_models(request) - {served_model}
for m in shadow_models:
enqueue_shadow(request, m, served_model) # async; off the critical path
return served_answer
def process_shadow(request, shadow_model, served_model):
shadow_answer = call(request, model=shadow_model) # background, no user impact
grade = slice_grader(request)(shadow_answer) # slice-appropriate grader (Ch.5)
write_router_eval_row(request, shadow_model, shadow_answer, grade) # -> Ch.13 tableTwo design rules keep shadow routing safe and affordable. First, it must be off the critical path: shadow calls run asynchronously after the user is served, so a slow or failed shadow never affects the live response, the user never waits for a label. Second, it is sampled, not exhaustive: shadowing every model on every request multiplies your bill by the fleet size, which defeats the purpose. A few percent of traffic, stratified across slices so even rare slices get labeled, is plenty to estimate the matrix and regret. Shadow routing is a measurement cost you pay deliberately and bound tightly, and the OpenAI production best practices guidance on not letting auxiliary work block the request path applies directly.
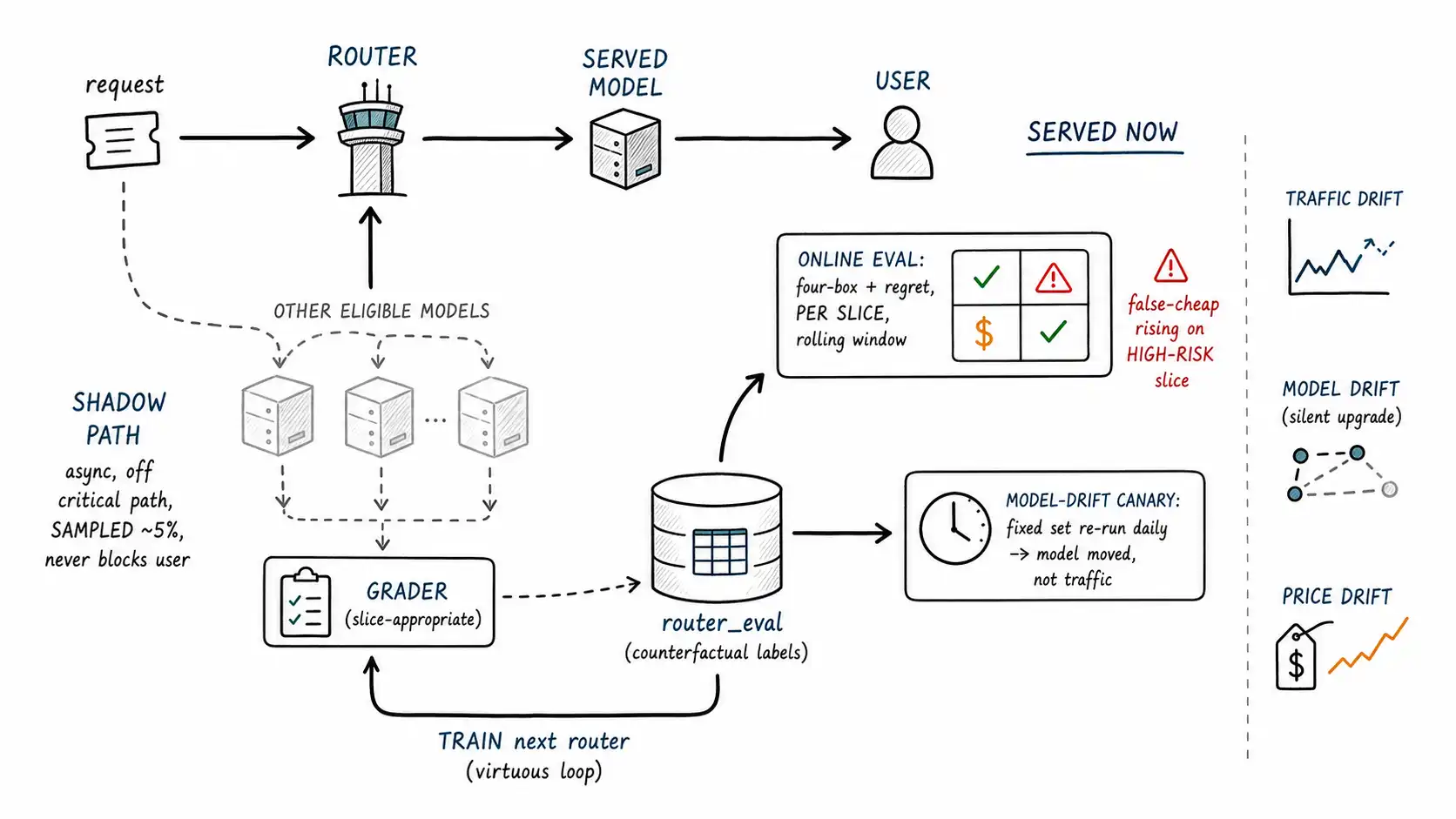
Online evaluation: the world moves
Offline regret is computed on a frozen dataset. But the world the router operates in is not frozen, and three kinds of drift quietly invalidate a policy built on yesterday's measurements.
Traffic drift. The mix of requests changes, a new feature ships, a marketing campaign brings a different user population, a seasonal pattern shifts the slice distribution. A policy tuned when 70% of traffic was easy behaves differently when 50% is easy, and the route distribution shifts even though the policy did not. Traffic drift is detected by watching the slice distribution over time, not the policy.
Model drift. Providers update models behind a stable name. The "flagship" you escalate to in June is not byte-identical to the one you measured in March; a minor update can change its quality on your slices in either direction. This is the most insidious drift because nothing in your system changed, the model under the name moved. RouteLLM's finding that its routers transfer across swapped models is encouraging here (a good router is somewhat robust to model changes), but robustness is not immunity: a model regression can quietly raise your false-cheap rate if the cheap model got worse, or your false-expensive rate if the strong model got better and the cheap one could now have sufficed more often.
Price drift. Providers change prices, deprecate cheap tiers, and launch new ones. A price cut can move a previously-dominated model onto the frontier (Chapter 2); a price increase can make your default escalation target uneconomical. The cost side of every regret and cost-weighted-quality calculation depends on prices that change without warning.
Online evaluation is the continuous re-measurement that catches all three. It is the same metrics as offline, the four-box matrix, regret, cost-weighted quality, but computed on a rolling window of recent shadow-labeled traffic, with alerts when a metric crosses a threshold or shifts sharply.
-- Online evaluation: the four-box matrix and regret on a ROLLING window,
-- broken out by slice so drift is localized, not averaged away.
WITH recent AS (
SELECT * FROM router_eval
WHERE ts > now() - interval '7 days'
)
SELECT
slice_key, risk_tier,
count(DISTINCT request_id) AS requests,
-- false-cheap rate: served cheap but a passing model existed that we missed
avg(CASE WHEN served_cheap AND NOT cheap_passed AND any_model_passed
THEN 1.0 ELSE 0.0 END) AS false_cheap_rate,
-- false-expensive rate: escalated but cheap would have passed
avg(CASE WHEN escalated AND cheap_passed THEN 1.0 ELSE 0.0 END) AS false_expensive_rate,
avg(served_cost_usd - oracle_cost_usd) AS cost_regret,
avg(oracle_passed::int - served_passed::int) AS quality_regret
FROM recent
GROUP BY slice_key, risk_tier
ORDER BY false_cheap_rate DESC; -- worst quality risk at the topThe GROUP BY slice_key, risk_tier is the operational point: drift is localized. A model regression that hurts one slice will spike that slice's false-cheap rate while the average across all slices barely moves, so an average-only dashboard misses exactly the regression you most need to catch. Online evaluation must be per-slice, and the alert that matters most is rising false-cheap rate on a high-risk slice, the Chapter 12 number that turns into incidents.
Detecting model drift specifically
Model drift deserves its own detector because it is invisible to traffic and price monitoring. The technique: maintain a small, fixed canary set of requests with known good answers, and re-run it against every model in the fleet on a schedule (daily, say). If a model's score on the canary set moves, the model changed, your traffic and prices did not. This separates "the world changed" from "the model changed, " which point at different responses: traffic drift means re-tune the policy; model drift means re-measure the frontier and possibly re-route around a regressed model.
# Model-drift canary: a fixed eval set re-run against each model on a schedule.
# A score shift here means the MODEL moved, isolating it from traffic/price drift.
def model_drift_check(canary_set, fleet, baseline_scores, tolerance=0.03):
alerts = []
for model in fleet:
score = sum(grade(canary_set[i], call(c.request, model=model))
for i, c in enumerate(canary_set)) / len(canary_set)
delta = score - baseline_scores[model]
if abs(delta) > tolerance:
alerts.append((model, baseline_scores[model], score, delta))
# delta < 0: regression -> re-route away / re-tune thresholds
# delta > 0: improvement -> cheap model may now suffice more -> re-measure
return alertsA model improvement is as important to catch as a regression: if your cheap model silently got better, more requests now succeed on it than your policy assumes, and you are leaving savings on the table by escalating requests that no longer need it. Drift detection is bidirectional, both directions are opportunities or risks that a static policy will miss.
The feedback loop: shadow labels train the next router
The chapters close into a loop. Shadow routing produces counterfactual labels; online evaluation computes regret and detects drift from them; and those same labels are the training data for the next, better router (Chapter 7's virtuous loop). RouteLLM trains on preference labels; your shadow stream is a preference-label generator, every shadow comparison is a labeled example of "cheap vs. strong on this request." So the production system that serves answers also, as a byproduct, generates the data to improve its own routing, if you log the decisions (Chapter 1), shadow a sample (this chapter), and grade with slice-appropriate graders (OpenAI evals guide). A routed system without this loop is static and decays; a routed system with it compounds, the longer it runs, the more it knows about its own traffic, and the closer it can ride the oracle frontier. FrugalGPT's learned scorer and RouteLLM's learned router both presuppose this data; shadow routing is how you generate it in production rather than buying or hand-labeling it.
Chapter summary
Offline evaluation grades the router on frozen data, but production is not frozen, and a policy needs to keep measuring itself against a moving world. Shadow routing is the labeling engine: it runs the un-served models in the background on a sample of traffic, grades them with slice-appropriate graders, and records the counterfactual, what the model you didn't serve would have done, which is exactly the (request, model) outcome the four-box matrix and regret require, and which production logs alone can never provide. It must stay off the critical path (async, so a slow shadow never delays the user) and be sampled and stratified (shadowing everything multiplies the bill by fleet size). Online evaluation recomputes the four-box matrix, regret, and cost-weighted quality on a rolling window, broken out per slice because the three drifts that invalidate a policy, traffic drift (the request mix changes), model drift (providers silently upgrade a model behind a stable name), and price drift (costs change without warning), typically hit one slice while the average hides them; the alert that matters most is rising false-cheap on a high-risk slice. Model drift gets its own canary set re-run against every model on a schedule, isolating "the model moved" from "the world moved, " and improvements matter as much as regressions because a silently-better cheap model means escalations you no longer need. Finally, the chapters close into a compounding loop: shadow labels feed online evaluation and train the next router (RouteLLM-style preference data generated in production, FrugalGPT-style scorers presupposing exactly this data), so a routed system with the loop knows more about its traffic the longer it runs, while one without it decays into a fossil of the day its policy was written.
Internal map
For the larger argument, keep this chapter connected to Model Routing, The Economics of Inference, the smaller-model margin argument, and A Field Guide to Evals.