The Frontier, Not the Flagship
> **Working claim:** "Which model is best?" is the wrong question because it presumes a single ranking on a single axis.

Key Takeaways
- The Frontier, Not the Flagship is a chapter about model routing and inference control planes, not a generic AI adoption note.
- The operating rule is to send each request to the cheapest path that still meets quality, latency, residency, and risk requirements.
- The failure mode to watch is polished output without evidence, owner, cost line, or rollback path.
- The useful next step is an artifact a future teammate can replay without folklore.
Model routing works when each request goes to the cheapest path that still meets quality, latency, residency, and risk requirements.
Working claim: "Which model is best?" is the wrong question because it presumes a single ranking on a single axis. Models live on a frontier, a curve of cost against quality where no point dominates every other, and a router's job is to ride that frontier, choosing the point that fits each request's budget and risk rather than camping at one corner of it.
Plot the models before you rank them
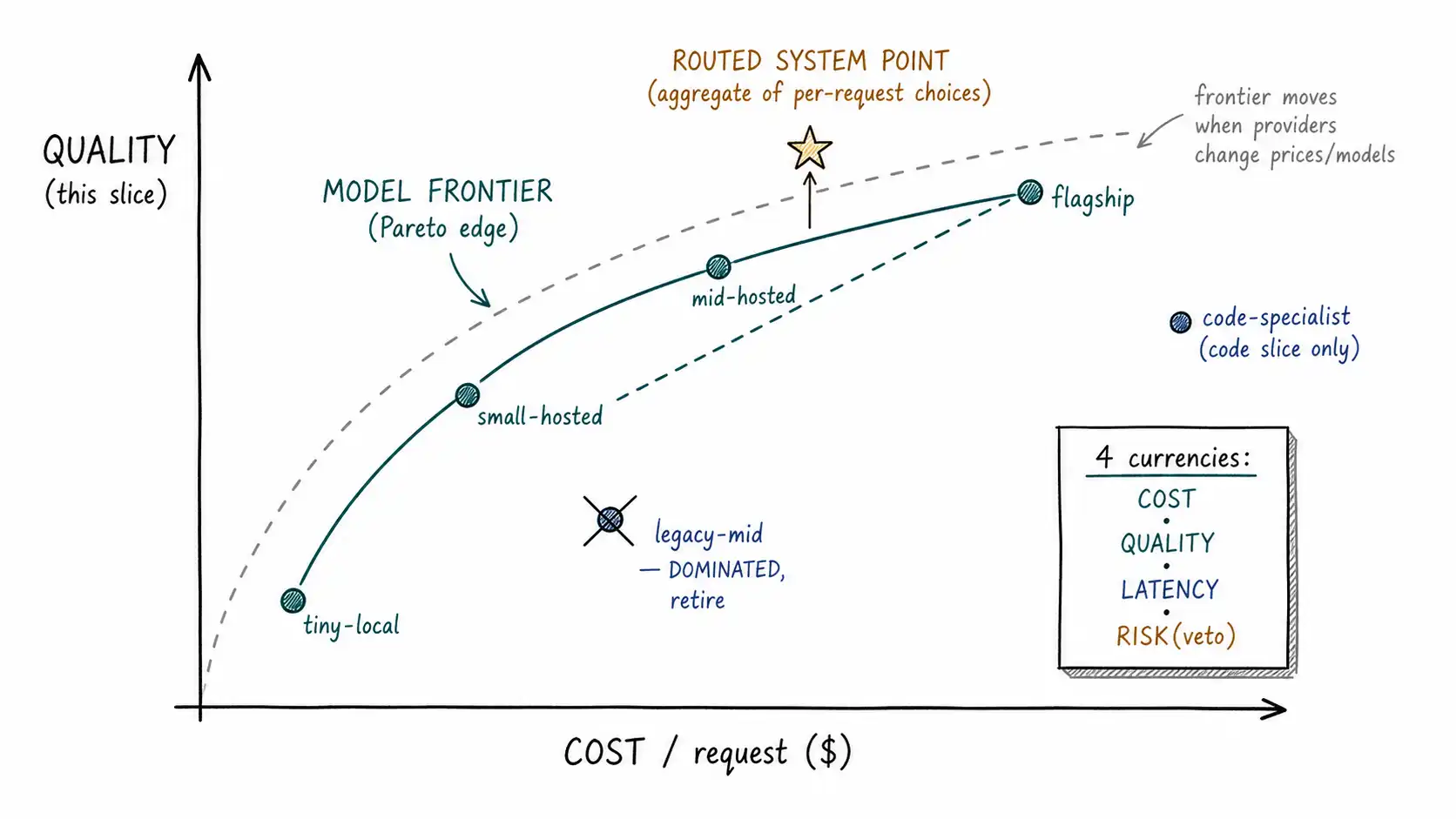
Stop ranking models for a moment and plot them. Put cost per request on one axis and quality on a slice of your traffic on the other. What you get is not a line with a clear winner at the top; it is a scatter of points, and the only points that matter are the ones on the upper-left edge, high quality for their cost. That edge is the Pareto frontier. A point is on the frontier if no other model gives you both higher quality and lower cost. A point off the frontier is strictly dominated, there is something cheaper that is at least as good, or something equally priced that is better, and it should never be chosen for any request, because choosing it is choosing to waste money or quality with nothing to show for it.
Here is the kind of table that scatter comes from. The numbers are illustrative, you must build your own from your own traffic and your own prices, but the shape is what matters.
| Model | Quality (this slice) | Cost / req | On frontier? | Role |
|---|---|---|---|---|
| tiny-local | 0.61 | $0.0004 | Yes | Cheapest floor |
| small-hosted | 0.79 | $0.002 | Yes | Workhorse |
| mid-hosted | 0.88 | $0.006 | Yes | Escalation target |
| flagship | 0.95 | $0.020 | Yes | Hard / high-risk |
| legacy-mid | 0.82 | $0.009 | No (dominated) | Retire it |
| code-specialist | 0.93 (code only) | $0.007 | Yes (code slice) | Specialist lane |
legacy-mid is the instructive row. It costs more than mid-hosted and scores lower; it is dominated; it has no business in any routing decision. Half the value of plotting the frontier is that it tells you which models to delete from the fleet, a procurement decision that the routing analysis hands you for free. The other instructive row is code-specialist: it is not on the frontier for the general slice, but on the code slice it dominates the flagship at a third of the cost. Frontiers are per-slice. A model dominated on average can be the right call on its specialty, which is why specialist lanes exist (Chapter 8) and why "quality" is always quality-on-something.
Why no single number ranks models
The "which model is best?" question survives because leaderboards answer it, a single column, sorted, with a winner on top. Leaderboards are useful for orientation and dangerous for architecture, because they collapse the two things a router must keep apart. They collapse which task: a model that tops a chat-preference board may trail on arithmetic, code, or long-context retrieval, and your workload is not the leaderboard's task mix. And they collapse cost: a board sorted by quality alone treats a model that wins by half a point at five times the price as "better, " which for routing is exactly backwards.
The OpenAI evals guide makes the practical version of this point: you should build evals on your task, with your graders, because a model's general ranking tells you little about its performance on the specific thing you are doing. A router consumes the output of that advice, per-task, per-model quality numbers, and turns it into a decision. The leaderboard gives you a starting hypothesis about who belongs in the fleet. Your own per-slice frontier gives you the routing policy.
The frontier is what a router rides
Now the geometric intuition that names this book. Imagine the frontier curve drawn through tiny-local, small-hosted, mid-hosted, and flagship. A single-model system is a single point on (or off) that curve, flagship-everywhere sits at the top-right (max quality, max cost), cheap-everywhere sits at the bottom-left. A router is not a point. It is a path: for each request it picks a point on the frontier, and the system's aggregate behavior is the cost-weighted average of those choices. By sending the easy seventy percent to tiny-local/small-hosted and the hard ten percent to flagship, the router lands the system at an aggregate point that no single model occupies, below the flagship on cost, above the cheap model on quality, on a frontier of its own that sits inside the model frontier.
This is the precise sense in which a router beats every single model: not on any individual request (on a given request the best you can do is the best eligible model), but in aggregate, because it spends expensive capability only where it changes the answer. FrugalGPT demonstrates exactly this aggregate frontier, its cascades trace a cost-accuracy curve that dominates any fixed model choice across a range of budgets, which is why it can claim to match the best model "with up to 98% cost reduction" at one budget point and to beat it at an equal-cost point. The router does not have a magic model. It has a better allocation of the models it has.
# The aggregate frontier point of a routed system, given a policy and a workload.
# Demonstrates that routing produces a SYSTEM point distinct from any single model.
def system_point(policy, workload, per_slice_quality, per_model_cost):
total_q = total_cost = 0.0
for req in workload:
slice_ = classify(req) # which slice this request falls in
model = policy.choose(req, slice_) # the routing decision
total_q += per_slice_quality[slice_][model] # expected quality there
total_cost += per_model_cost[model](req) # cost for this request
n = len(workload)
return (total_cost / n, total_q / n) # (aggregate cost, aggregate quality)
# Comparing single-model points to the routed point on the same workload:
points = {
"all_small": system_point(const_policy("small-hosted"), wl, Q, C),
"all_flagship": system_point(const_policy("flagship"), wl, Q, C),
"routed": system_point(my_routing_policy, wl, Q, C),}
# Plot these; `routed` should sit up-and-left of the line between the two single points.The check that you have actually built something worthwhile is geometric: plot the three points. If routed sits above the straight line connecting all_small and all_flagship, you have bought quality-per-dollar that no blend of the two extreme models could buy. If it sits on that line, your router is doing nothing a coin flip between two models could not, and you should look at why (probably your difficulty signal is noise, the subject of Movement II).
The four currencies, and why cost is never alone
The frontier so far has two axes, cost and quality, because they are the easiest to plot. Production has four currencies, and the router trades among all of them: cost, quality, latency, and risk. The ROUTE framework names them as questions; here they are as a budget the router spends.
- Cost is the easiest to measure and the one finance watches. It is also the most seductive to over-optimize, because cutting it has no immediate visible downside, the downside (wrong answers) is deferred and shows up in a different team's metrics.
- Quality is hard to measure (it needs evals and graders, Movement IV) and varies by task, which is why "quality" without "of what task" is meaningless.
- Latency is a hard constraint, not a soft preference, for interactive requests: a perfect answer that arrives after the user has left is worth zero. A cascade that escalates buys quality with latency, the second model call adds whole seconds, so latency-tight requests cannot use deep cascades no matter how cheap they are. Chapter 16 is the latency budget in full.
- Risk is the axis that converts a two-dimensional frontier into a gated one. High-risk requests have a floor on eligible models regardless of cost or latency: you do not route a request that could cause real harm to the cheap lane just because it looks easy. Risk does not trade smoothly against cost; it vetoes parts of the frontier.
A useful way to hold all four is that cost and latency are resources you spend, quality is the thing you are buying, and risk is the constraint that says which purchases are even allowed. A router that only watches cost is shopping with its eyes closed to three of the four prices.
Prompt caching bends the frontier
One economic mechanism deserves naming here because it changes which point on the frontier is cheapest, and naive cost models miss it. Prompt caching lets a provider reuse the computation of a byte-identical prompt prefix across requests at a steep discount on those cached input tokens. If your requests share a large stable prefix, a long system prompt, a fixed set of instructions, a tool schema, a cached document, then the marginal cost of a request on a given model can be dramatically lower than its sticker cost, because most of the input is cached.
This matters for routing in a way that is easy to get wrong: caching is per-model and per-prefix. Routing a request to a different model than the last one means a cache miss on that model's prefix, which can make the "cheaper" model more expensive on that single request than staying on the model whose cache is warm. A cost model that ignores cache state will route to the nominally cheaper model and pay full freight for the prefix it just discarded. The router's cost estimate (Chapter 15) should therefore be cache-aware: the cost of a candidate model is its token cost adjusted for whether that model's relevant prefix is currently cached for this request shape. The frontier is not static; it bends toward whichever model is already warm.
The frontier moves under you
A final, sobering property: the frontier is not a fixed map you draw once. Providers ship new models, change prices, deprecate old ones, and silently update the model behind a name. Every one of those events moves the frontier, and a routing policy pinned to last quarter's frontier is slowly becoming wrong. A model you routed around because it was dominated may get a price cut that puts it on the frontier; your escalation target may get a quality regression in a minor update that pushes it off the frontier you were counting on.
This is why routing is an operational discipline and not a one-time design (Movement VII). The frontier must be re-measured on a schedule, every model in the fleet re-evaluated on your slices, prices refreshed, dominated models flagged for retirement, and the routing policy treated as a living artifact that tracks the moving frontier. The single biggest difference between a routing system that ages well and one that rots is whether anyone re-runs the frontier measurement after the provider changes something, or whether the policy is a fossil of the day it was written.
Chapter summary
"Which model is best?" presumes a single ranking on a single axis; models actually live on a Pareto frontier of cost against quality, where a point is worth considering only if nothing else is both cheaper and at least as good. Plotting the frontier from your own per-slice numbers immediately reveals dominated models to retire (the legacy-mid row) and specialists that win only on their slice (the code-specialist row), because frontiers are per-task: "quality" is always quality-of-something, which is why leaderboards orient but do not architect. A single-model system is one point on the frontier; a router is a path, and by spending expensive capability only where it changes the answer it lands the system at an aggregate point above the straight line between the cheap and flagship models, quality-per-dollar no blend of two models could buy, which is exactly the cost-accuracy curve FrugalGPT and RouteLLM demonstrate. Production trades four currencies, not two: cost and latency are resources you spend, quality is what you are buying, and risk is a veto that gates parts of the frontier off for dangerous requests. Prompt caching bends the frontier per-model and per-prefix, routing to a "cheaper" model can mean a cache miss that makes it dearer, so cost estimates must be cache-aware. And the frontier moves whenever providers ship, reprice, or deprecate models, which makes re-measuring it on a schedule the difference between a routing policy that ages well and one that quietly rots into being wrong.
Internal map
For the larger argument, keep this chapter connected to Model Routing, The Economics of Inference, the smaller-model margin argument, and A Field Guide to Evals.