Reading Risk Before Reading Difficulty
> **Working claim:** Difficulty and risk are different axes, and the router must read *risk first*.

Key Takeaways
- Reading Risk Before Reading Difficulty is a chapter about model routing and inference control planes, not a generic AI adoption note.
- The operating rule is to send each request to the cheapest path that still meets quality, latency, residency, and risk requirements.
- The failure mode to watch is polished output without evidence, owner, cost line, or rollback path.
- The useful next step is an artifact a future teammate can replay without folklore.
Model routing works when each request goes to the cheapest path that still meets quality, latency, residency, and risk requirements.
Working claim: Difficulty and risk are different axes, and the router must read risk first. Difficulty asks "can a cheap model get this right?" Risk asks "what does it cost us if it gets it wrong?" A request can be trivially easy and catastrophically risky at the same time, and a router that only estimates difficulty will route that request to the cheap lane because it looks easy, which is exactly how the worst incidents happen.
The two-axis plane, and why one axis is not enough
The previous chapter argued that difficulty is multi-signal and that length is not it. This chapter argues something stronger and easy to miss: difficulty is not the only thing the router needs, and on its own it is dangerous. There is a second, independent axis, risk, and it must be read before difficulty, because it can override difficulty entirely.
Put the two axes on a plane. The horizontal axis is difficulty: how likely is a cheap model to be right? The vertical axis is risk: how bad is it if the answer is wrong? Every request lands somewhere on this plane, and the four quadrants demand four different policies.
| Low risk | High risk | |
|---|---|---|
| Easy | Cheap lane. The happy majority. | The trap quadrant. Looks routable-to-cheap; must not be. |
| Hard | Cascade / verify-then-escalate. | Strong model and/or human. The expensive tail. |
The bottom-right (hard + high-risk) is obvious and gets handled: it looks scary and everyone routes it carefully. The top-left (easy + low-risk) is the cheap majority and also handled. The dangerous cell is the top-right: easy but high-risk. A request that a difficulty estimator confidently labels "easy" but whose wrong answer is catastrophic. A one-axis router, even a sophisticated, well-calibrated difficulty estimator, sends this request to the cheap lane, because on the only axis it measures, the request is easy. The wrongness is not in the difficulty estimate. It is in measuring only difficulty.
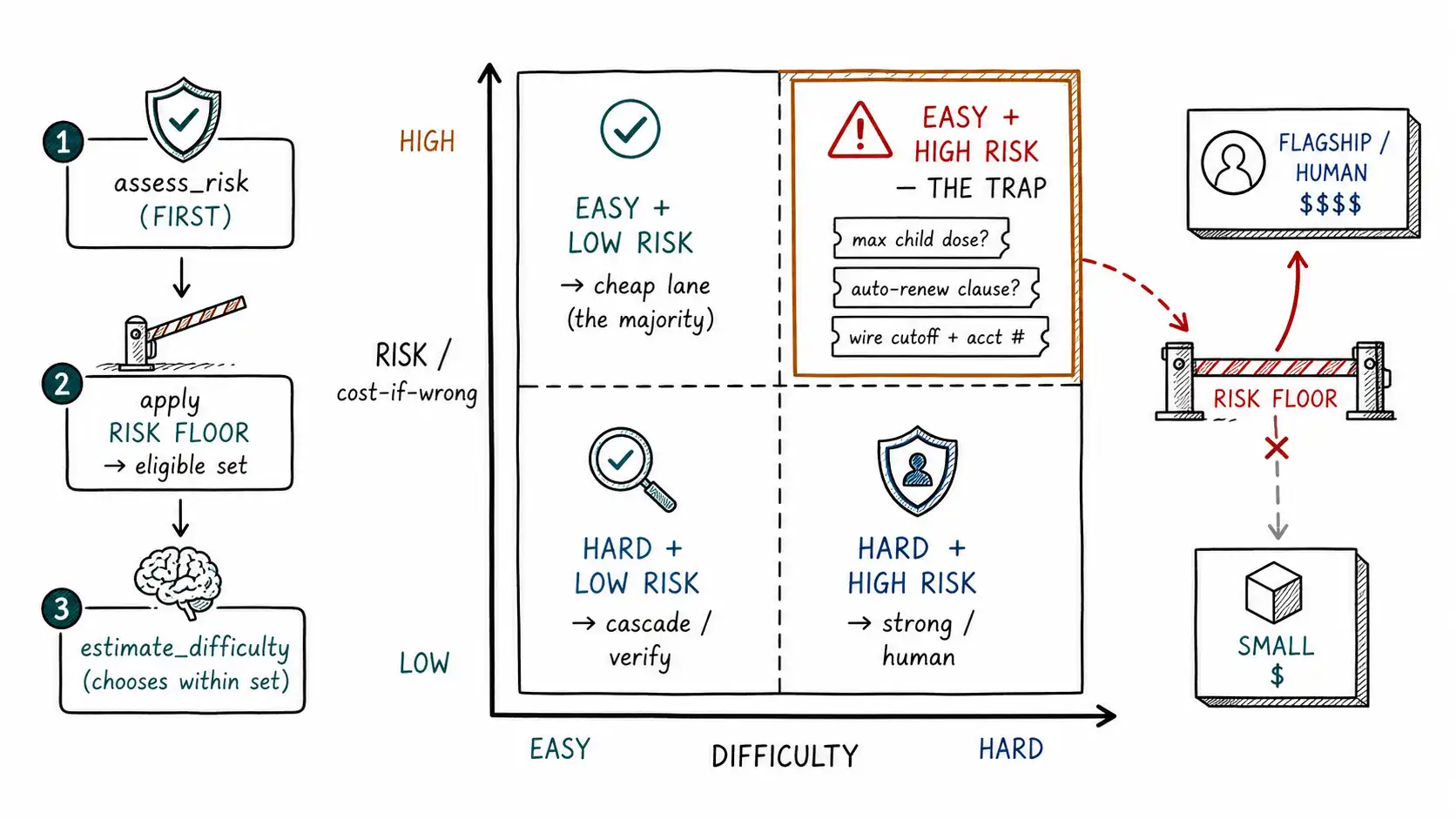
Examples that live in the trap quadrant
The trap quadrant is not hypothetical. It is full of the requests that turn into incidents.
- "What's the maximum safe dose of [drug] for a child?" Linguistically simple, low perplexity, a cheap model answers fluently. Wrong answer: physical harm. Difficulty: low. Risk: extreme.
- "Does this contract clause auto-renew?" A short yes/no a cheap model will assert confidently. Wrong answer: a client signs a multi-year obligation they did not intend. Difficulty: deceptively low. Risk: high.
- "What's the wire transfer cutoff and account number for vendor X?" A lookup-shaped question. Wrong answer: money sent to the wrong place. Difficulty: low. Risk: severe and irreversible.
- "Is this transaction fraudulent?" Can look like a simple classification. Wrong answer in either direction: a real customer blocked, or a real fraud waved through. Difficulty: variable. Risk: high.
- "Reset the production database password to the value in this message." An instruction-following task a cheap model executes happily. Risk: catastrophic and exactly the kind of high-blast-radius action that should be gated by a human, not a model tier.
Each of these is easy on the difficulty axis and unacceptable on the cheap lane on the risk axis. The router must catch them before the difficulty estimator ever runs, because the difficulty estimator's correct answer ("easy") is the wrong routing decision.
Risk as a floor, not a feature
The structural fix is to treat risk differently from every other signal. Difficulty, ambiguity, length, tool-need, those are features that the router weighs and trades off. Risk is not a feature to weigh; it is a floor that gates eligibility before any tradeoff happens. A high-risk request has a minimum eligible model tier (and possibly a mandatory human or validator) that no amount of "but it looks easy and cheap" can lower.
This mirrors how risk frameworks treat consequence. The NIST AI Risk Management Framework organizes around the idea that AI risk is a function of both likelihood and impact (consequence), and that high-impact contexts warrant stronger controls regardless of how confident the system is. Translated to routing: a high-impact request warrants a stronger model and more verification regardless of predicted difficulty. Risk and difficulty are the likelihood-and-impact pair, and you cannot collapse them into one number without losing the impact dimension exactly where it matters most.
# Risk is read FIRST and gates eligibility. Difficulty only operates
# on the models risk leaves on the table.
RISK_FLOOR = {
"low": "small-hosted", # any model down to the cheap lane
"medium": "mid-hosted", # no cheaper than mid
"high": "flagship", # flagship floor; cheap lane forbidden
"critical": "human", # model may draft, human must approve/own
}
def route(request, fleet):
risk = assess_risk(request) # FIRST. Independent of difficulty.
floor = RISK_FLOOR[risk]
if floor == "human":
return route_to_human(request, model_may_draft=True)
eligible = [m for m in fleet if m.tier >= tier_of(floor)] # risk gates the set
if not eligible:
return route_to_human(request) # nothing meets the floor -> escalate
# ONLY NOW does difficulty pick among the risk-eligible models.
difficulty = estimate_difficulty(request)
return choose_by_difficulty(eligible, difficulty)The order of operations is the entire point. assess_risk runs before estimate_difficulty, and difficulty only ever chooses among the models that survived the risk floor. A request in the trap quadrant, easy but high-risk, has floor == "flagship", so even though estimate_difficulty would happily pick the cheap model, the cheap model is not in the eligible set. Risk removed it before difficulty got a vote.
What feeds the risk assessment
Risk is assessed from signals largely orthogonal to difficulty, which is why a difficulty estimator cannot infer it. The main ones:
- Domain. Medical, legal, financial, safety-critical, and security-sensitive domains carry intrinsic risk. A request about drug dosing is high-risk independent of its phrasing. Domain is usually classifiable from task type and content.
- Action vs. answer. A request that triggers an action (sends money, changes a record, runs a tool with side effects) is riskier than one that returns text, because text can be reviewed before it matters and actions often cannot. Tool-using agent steps (Chapter 11's territory, revisited in governance) deserve risk weighting for their side effects, not their linguistic difficulty.
- Irreversibility. Can the wrong answer be undone? A wrong summary is editable; a wrong wire transfer is not. Irreversibility raises risk sharply.
- Audience and reliance. Is the answer shown to an internal expert who will sanity-check it, or to an end user who will act on it as authoritative? The same content carries different risk depending on who relies on it and how.
- Regulatory exposure. Some answer types carry compliance consequences (financial advice, medical guidance, legal interpretation) regardless of correctness, because the act of answering is regulated.
- Adversarial signal. A request that looks designed to extract a harmful answer, or to manipulate routing, is high-risk by virtue of intent, a bridge to OWASP's LLM Top 10 concerns like prompt injection and the abuse patterns of Chapter 17.
None of these are difficulty signals. A request can score high on all of them while being linguistically trivial, which is precisely why risk must be its own assessment with its own inputs.
The risk-tier classifier
In practice risk assessment is a fast classifier (a cheap model, a rules engine, or both) that runs at the very front of the pipeline and emits a tier. It must be conservative: when uncertain about risk, round up, because the cost of mis-classifying a high-risk request as low is an incident, while the cost of mis-classifying a low-risk request as high is a slightly-too-expensive answer. The asymmetry is the same one that governs the whole book, false-cheap on a risky request is the expensive error, and it dictates the classifier's bias.
# A conservative risk classifier. Rounds UP on uncertainty.
# Combines cheap deterministic rules (high precision) with a model fallback.
HARD_RULES = [
# (predicate, tier) - deterministic, audited, never overridden downward
(lambda r: r.triggers_side_effecting_tool(), "critical"),
(lambda r: r.domain in {"medical", "legal", "financial_advice"}, "high"),
(lambda r: r.involves_pii or r.involves_payment, "high"),
(lambda r: r.tenant_requires_human_review, "critical"),]
def assess_risk(request):
for predicate, tier in HARD_RULES: # rules win, deterministically
if predicate(request):
log_risk_decision(request, tier, reason="hard_rule")
return tier
# No hard rule fired: ask a cheap classifier, but bias toward caution.
pred = risk_classifier.predict_proba(request) # {"low":.., "medium":.., "high":..}
if pred["high"] > 0.15: # low threshold ON PURPOSE
return "high"
if pred["medium"] > 0.30:
return "medium"
return "low"The thresholds (0.15, 0.30) look low because they are low, the classifier rounds up. A 15% chance a request is high-risk is enough to treat it as high-risk, because the expected cost of an under-classified high-risk request dwarfs the expected cost of an over-classified low-risk one. The hard rules run first and are deterministic and audited, because the highest-risk categories (side-effecting actions, payments, mandated human review) should never depend on a probabilistic classifier's mood.
Risk changes what "correct" even means
A subtle consequence closes the chapter. Risk does not only change which model is eligible; it changes the quality bar the answer must clear and the outcome metric you measure against, the O of ROUTE. On a low-risk summarization, "mostly faithful" is fine. On a high-risk financial calculation, the bar is exact correctness, and the right outcome metric is exact-match, not a fuzzy quality score. This is why Chapter 1 insisted "correct enough" is per-slice: the threshold is a function of risk. A router that uses one global quality threshold under-protects high-risk slices (the threshold is too lax for them) and over-protects low-risk ones (escalating requests that did not need it). The OpenAI evals guide's emphasis on choosing graders appropriate to the task is, in routing terms, the instruction to set the quality bar per risk tier, with stricter graders and higher thresholds where the consequence of error is larger. FrugalGPT's cascades implicitly assume a quality threshold to decide when to stop; risk is what sets that threshold, and it should be set higher for the slices that can hurt you.
Chapter summary
Difficulty ("can a cheap model get this right?") and risk ("what does a wrong answer cost?") are independent axes, and the router must read risk first because risk can override difficulty entirely. On the difficulty-by-risk plane the dangerous cell is the top-right, easy but high-risk, the trap quadrant full of requests like child dosing, auto-renewal clauses, wire-transfer details, and side-effecting actions: linguistically simple, low-difficulty, and catastrophic if wrong. A one-axis router sends these to the cheap lane because on the only axis it measures they are easy; the wrongness is in measuring only difficulty. The fix is to treat risk not as a feature to weigh but as a floor that gates the eligible model set before difficulty gets a vote: assess_risk runs first, applies a minimum tier (up to mandatory human review for critical actions), and difficulty only chooses among the survivors. Risk is fed by signals orthogonal to difficulty, domain, action-vs-answer, irreversibility, audience reliance, regulatory exposure, adversarial intent, which is why a difficulty estimator cannot infer it, and the risk classifier must round up on uncertainty because false-cheap on a risky request is the expensive error (the NIST AI RMF likelihood-times-impact framing). Finally, risk also sets the quality bar and outcome metric per slice: high-risk slices demand stricter graders and higher thresholds, which is the per-slice "correct enough" that the cascade's stopping rule depends on.
Internal map
For the larger argument, keep this chapter connected to Model Routing, The Economics of Inference, the smaller-model margin argument, and A Field Guide to Evals.