The Cascade Ladder
> **Working claim:** A cascade is the most powerful routing pattern and the easiest to build wrong. Its power is that it escalates on the strongest possible signal, the actual answer, judged by a verifier.

Key Takeaways
- The Cascade Ladder is a chapter about model routing and inference control planes, not a generic AI adoption note.
- The operating rule is to send each request to the cheapest path that still meets quality, latency, residency, and risk requirements.
- The failure mode to watch is polished output without evidence, owner, cost line, or rollback path.
- The useful next step is an artifact a future teammate can replay without folklore.
Model routing works when each request goes to the cheapest path that still meets quality, latency, residency, and risk requirements.
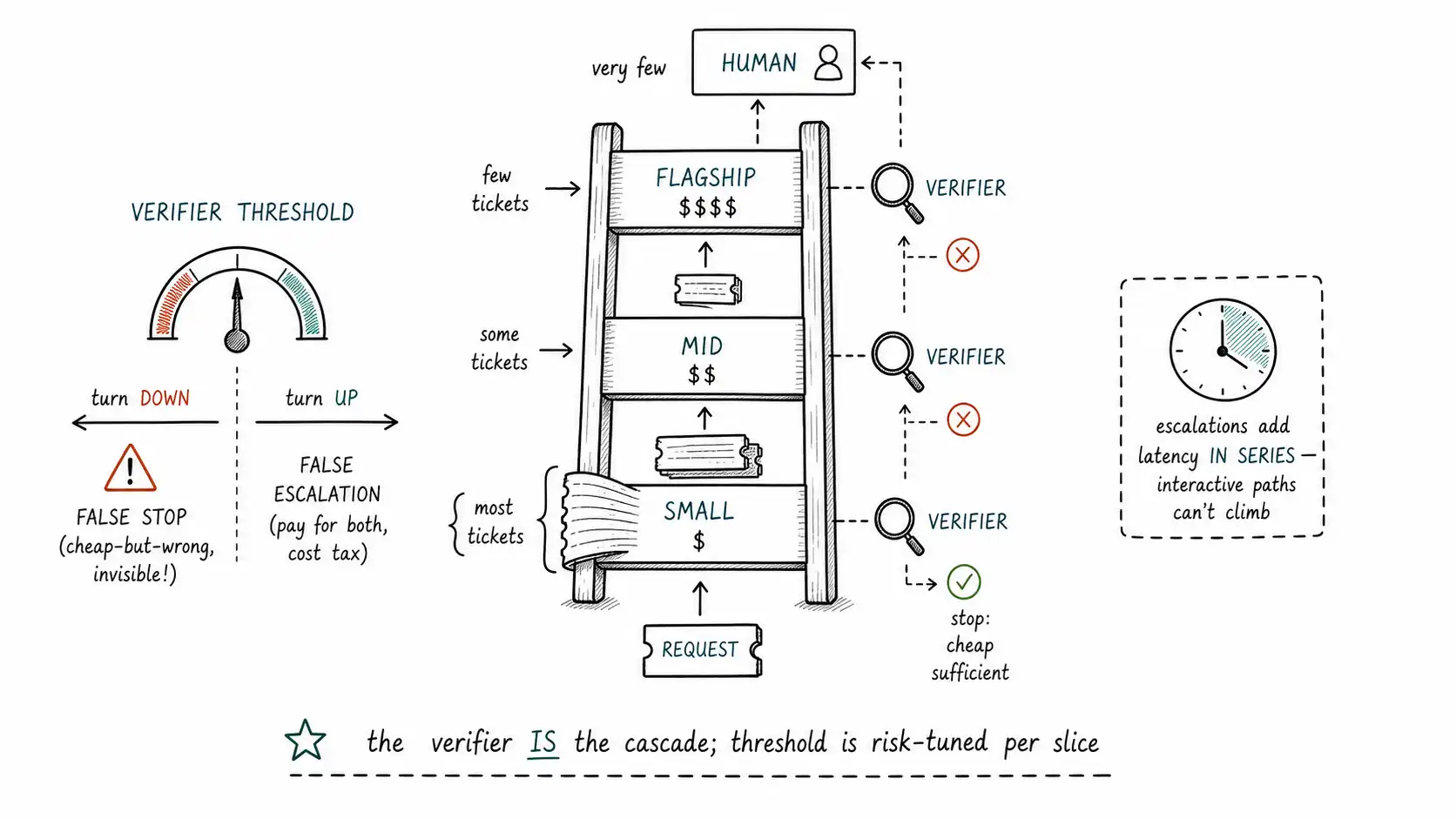
Working claim: A cascade is the most powerful routing pattern and the easiest to build wrong. Its power is that it escalates on the strongest possible signal, the actual answer, judged by a verifier. Its danger is that the verifier is the cascade: a verifier that is too lax lets wrong cheap answers through (false stops), and a verifier that is too strict escalates everything (runaway cost). The cascade does not make the model better; it makes the verifier the most important component in the system.
The ladder
A cascade is a ladder of models ordered by cost. A request enters at the bottom rung (the cheapest model), produces an answer, and a verifier judges it. If the verifier passes the answer, the request stops, the cheap answer is the final answer. If the verifier rejects it, the request climbs to the next rung (a more capable, more expensive model), which produces a new answer, judged again, climbing until a rung passes or the ladder runs out (where it routes to a human or returns the best attempt with a flag). The request climbs only as far as it needs to, which is the source of the economics: easy requests stop at the bottom and cost almost nothing; hard requests climb and cost more, but only the hard ones do.
FrugalGPT formalizes exactly this and demonstrates its payoff: by running models in increasing order of cost and stopping at the first whose answer a learned scorer accepts, the cascade matches the best individual model "with up to 98% cost reduction" on some benchmarks, because most requests never reach the expensive rungs. The headline number is benchmark-specific, but the mechanism is general, most workloads have a fat easy head, the easy head stops at the bottom rung, and you only pay for the expensive rungs on the thin hard tail.
The verifier is the cascade
Here is the claim that should reframe how you build cascades: the model choice barely matters; the verifier choice is everything. The verifier decides, for every request, whether the cheap answer is good enough. Get the verifier wrong and the cascade fails in one of two directions, both expensive.
A lax verifier passes cheap answers that are actually wrong, a false stop. The request stops at the bottom rung with a wrong answer, the cascade reports success, and the cost graph looks beautiful while the quality quietly rots. This is the dangerous failure because it is invisible: the cascade did its job (stopped early, saved money) and produced garbage, and nothing flags it until a downstream metric or a complaint surfaces. A lax verifier turns a cascade into the cheap-everywhere failure with a verification theater on top.
A strict verifier rejects cheap answers that were actually fine, a false escalation. Every request climbs to the top, you pay for the cheap attempt and the expensive one and the verifier on every request, and your "cost-saving cascade" costs more than flagship-everywhere because of the wasted cheap attempts and verifier calls. A strict verifier turns a cascade into a tax.
The verifier therefore has a precision/recall tradeoff that is the cascade's cost/quality tradeoff, and tuning it is the central act of operating a cascade. This is why Chapter 6 spent so long on verifiers versus self-reported confidence: the verifier is not a detail, it is the load-bearing wall.
Building verifiers in order of reliability
From Chapter 6, the reliability ordering of escalation signals applies directly to cascade verifiers. Build the most reliable one the task admits.
# A cascade with a verifier chosen by what the task admits.
# The verifier's quality IS the cascade's quality.
LADDER = ["small-hosted", "mid-hosted", "flagship"] # ascending cost
def cascade(request):
best_answer = None
for i, model in enumerate(LADDER):
if not eligible(model, request): # risk floor / length gate
continue
answer = call(request, model=model)
best_answer = answer
verdict, score = verify(request, answer) # PASS/FAIL + a margin
log_cascade_step(request, model, i, verdict, score)
if verdict == "PASS":
return answer # stop: cheapest sufficient rung
# Ran out of rungs without a PASS:
if request.risk_tier in ("high", "critical"):
return route_to_human(request, draft=best_answer)
return flag_low_confidence(best_answer) # return best attempt, flagged
def verify(request, answer):
# 1. Grounded, deterministic verifiers (most reliable) - use when available.
if request.task_type == "code":
return ("PASS", 1.0) if run_tests(answer) else ("FAIL", 0.0)
if request.expects_json:
return ("PASS", 1.0) if validates(answer, request.schema) else ("FAIL", 0.0)
if request.is_retrieval_grounded:
unsupported = unsupported_claims(answer, request.context)
return ("FAIL", 0.0) if unsupported else ("PASS", 1.0)
# 2. Behavioral consistency (SelfCheckGPT) - when no deterministic check exists.
if request.allow_sampling: # latency budget permits
samples = [call(request, model=answer.model, temperature=0.7) for _ in range(3)]
agree = agreement_score(samples + [answer])
return ("PASS" if agree > 0.8 else "FAIL", agree)
# 3. LLM-as-grader (a DIFFERENT model judging) - fallback when nothing else fits.
return llm_grade(request, answer, grader_model="mid-hosted")The verify function's structure is the chapter's prescription: deterministic grounded checks first (they are reliable and cheap to trust), SelfCheckGPT-style consistency second (behavioral, when latency allows the extra samples), and an LLM grader last, and the grader is a different model from the generator, never the cheap model judging its own work (Chapter 6's witness-vouching-for-itself rule).
Tuning the threshold against the confusion matrix
The verifier emits not just PASS/FAIL but a score (the margin), and the PASS threshold on that score is the knob that sets the cascade's operating point. Tune it against the four-box confusion matrix that Chapter 12 builds in full, but the logic is needed here to tune the cascade:
- Cheap-and-right (stop correctly): the win. Maximize.
- Cheap-and-wrong (false stop): verifier passed a bad answer. The dangerous error. Threshold too low.
- Escalated-and-needed (climb correctly): correct escalation. Necessary cost.
- Escalated-and-wasted (false escalation): verifier rejected a good cheap answer. Pure waste. Threshold too high.
Raising the PASS threshold reduces false stops (good for quality) and increases false escalations (bad for cost); lowering it does the reverse. The right threshold depends on the risk of the slice (Chapter 5): for high-risk slices, set the threshold high (accept more false escalations to avoid false stops, because a wrong answer is catastrophic); for low-risk slices, set it lower (accept some false stops to save cost, because a wrong answer is cheap). The cascade threshold, in other words, is risk-tuned per slice, and a single global threshold under-protects the risky slices and over-spends on the safe ones. This is precisely the per-slice quality bar from Chapter 1, now operationalized as a verifier threshold.
# The PASS threshold is per-slice and risk-tuned. One global threshold is wrong.
PASS_THRESHOLD = {
("billing.dispute", "high"): 0.90, # high risk: strict, avoid false stops
("support.faq", "low"): 0.55, # low risk: lenient, accept some false stops
("code.gen", "medium"): 0.999, # deterministic verifier: tests pass or don't
}
def passes(slice_key, risk, score):
return score >= PASS_THRESHOLD.get((slice_key, risk), 0.85) # conservative defaultHow deep should the ladder be?
A cascade can have two rungs or five. More rungs means finer-grained cost control (a request climbs to exactly the cheapest sufficient rung) but more verifier calls and more latency on the requests that climb. The practical guidance:
- Two rungs (cheap → flagship) is the right default for most systems. It is simple, the verifier runs at most twice, and it captures most of the savings (the easy head stops at rung one). Add rungs only when measurement shows a meaningful middle slice that a mid-tier model handles well, i. e., requests the cheap model fails but the mid model passes, often enough to justify the extra rung.
- Three rungs (cheap → mid → flagship) earns its place when that middle slice is large. Without it, requests that the cheap model fails jump straight to the flagship, over-paying for the ones a mid model would have handled.
- More than three is rarely worth it; the latency of climbing and the complexity of tuning multiple thresholds usually outweighs the marginal cost savings. The frontier (Chapter 2) is rarely so finely populated that four or five distinct rungs each pay off.
The depth decision is, like everything in routing, a measured one: build the ladder from the rungs the frontier actually offers, and add a rung only when the slice data shows requests that the rung below fails and the rung above passes, frequently enough to matter.
Latency: the cost a cascade hides
The cascade's economics are about money, but its hidden cost is latency. Every escalation adds a full model call in series, the cheap call, then the verifier, then the strong call, then the verifier again, and on an interactive request that climbs, the user waits for all of it. A cascade that looks cheap on the cost graph can look terrible on the p95-latency graph, because the tail of requests that escalate experience double or triple the latency. This is why Chapter 16's latency budget is a hard constraint on cascade depth: a latency-tight interactive request cannot afford to climb, so for those slices you must either skip the cascade (use a dynamic predictor to commit up front, Chapter 3) or run the rungs in parallel and cancel the slower one, paying for both but not waiting for both. The cascade trades latency for cost, and on interactive paths that trade can be the wrong one.
When not to cascade
To close, the conditions under which a cascade is the wrong pattern, because the pattern's power makes it over-applied:
- No verifier exists and sampling is too expensive. A cascade without a reliable verifier is just self-reported confidence in disguise (Chapter 6), and on a latency-tight path you cannot afford consistency sampling. Use a dynamic predictor instead.
- Latency is tight and most requests would climb. If the slice's cheap-model accuracy is low, most requests escalate, and you pay the cheap attempt and the latency for nothing. Predict-and-commit to the strong model directly (the slice data from Chapter 7 tells you this).
- The task is high-stakes enough to want an ensemble. When you want quality above the best single model, a cascade (which only ever returns one model's answer) cannot get you there; you need an ensemble (Chapter 11).
RouteLLM's predict-and-commit approach and FrugalGPT's look-and-climb cascade are the two poles, and the OpenAI evals guide discipline is what tells you which pole a given slice belongs to: measure, on your own data, whether predicting beats cascading for that slice, and let the measurement choose.
Chapter summary
A cascade is a cost-ordered ladder of models: a request enters at the cheapest rung, a verifier judges the answer, and the request climbs only as far as it must, most requests stop at the bottom, which is why FrugalGPT's cascade matches the best model with up to 98% cost reduction on favorable benchmarks. The reframing that matters is that the verifier is the cascade: a lax verifier produces false stops (cheap-but-wrong answers that pass, the dangerous invisible failure that turns a cascade into cheap-everywhere with verification theater), and a strict verifier produces false escalations (good cheap answers rejected, the waste that makes a "saving" cascade cost more than flagship-everywhere). Build verifiers in reliability order, deterministic grounded checks (run the tests, validate the schema, check claims against context) first, SelfCheckGPT-style behavioral consistency second, an LLM grader (a different model, never the cheap model judging itself) last. The PASS threshold is the operating-point knob and must be risk-tuned per slice: strict on high-risk slices to avoid false stops, lenient on low-risk slices to save cost, a single global threshold under-protects the risky and over-spends on the safe. Ladder depth is a measured decision (two rungs default; add a mid rung only when a real middle slice exists), and the cascade's hidden cost is latency, since escalations add full calls in series, making deep cascades wrong for latency-tight interactive paths where you should predict-and-commit (RouteLLM) or run rungs in parallel instead.
Internal map
For the larger argument, keep this chapter connected to Model Routing, The Economics of Inference, the smaller-model margin argument, and A Field Guide to Evals.