Failover, Local-vs-Cloud, and the Provider Mesh
> **Working claim:** Everything so far assumed the model you chose is *available*. In production it sometimes is not, providers rate-limit, time out, return errors, and have outages.

Key Takeaways
- Failover, Local-vs-Cloud, and the Provider Mesh is a chapter about model routing and inference control planes, not a generic AI adoption note.
- The operating rule is to send each request to the cheapest path that still meets quality, latency, residency, and risk requirements.
- The failure mode to watch is polished output without evidence, owner, cost line, or rollback path.
- The useful next step is an artifact a future teammate can replay without folklore.
Model routing works when each request goes to the cheapest path that still meets quality, latency, residency, and risk requirements.
Working claim: Everything so far assumed the model you chose is available. In production it sometimes is not, providers rate-limit, time out, return errors, and have outages. Failover is the routing pattern that keeps the system answering when a chosen model cannot, and it is a different discipline from quality routing: it triggers on availability, picks an equivalent substitute, and must never become a backdoor that bypasses the quality and governance constraints the primary route enforced.
Failure is not difficulty (again, because it matters)
Chapter 3 drew the line and this chapter lives on it: a cascade escalates because an answer was insufficient; a failover escalates because a call did not complete. The triggers are operational, timeout, rate limit (HTTP 429), server error (5xx), connection failure, provider outage, and the correct response is a different available path, not a stronger one. The single most common failover bug is treating every operational failure as a reason to escalate to the flagship "to be safe, " which converts a transient provider hiccup into a cost blowup: a brief rate-limit spike on the cheap model sends a flood of traffic to the flagship, and the bill spikes for no quality reason at all.
OpenAI's production best practices lay out the availability discipline this chapter routes around, exponential backoff with jitter on retries, respecting rate-limit headers, setting timeouts, and degrading gracefully. The routing addition is: where to retry. A naive system retries the same endpoint; a routed system has a mesh of providers and can retry on an equivalent one, which is both faster (no waiting for the rate limit to clear) and more resilient (survives a full provider outage).
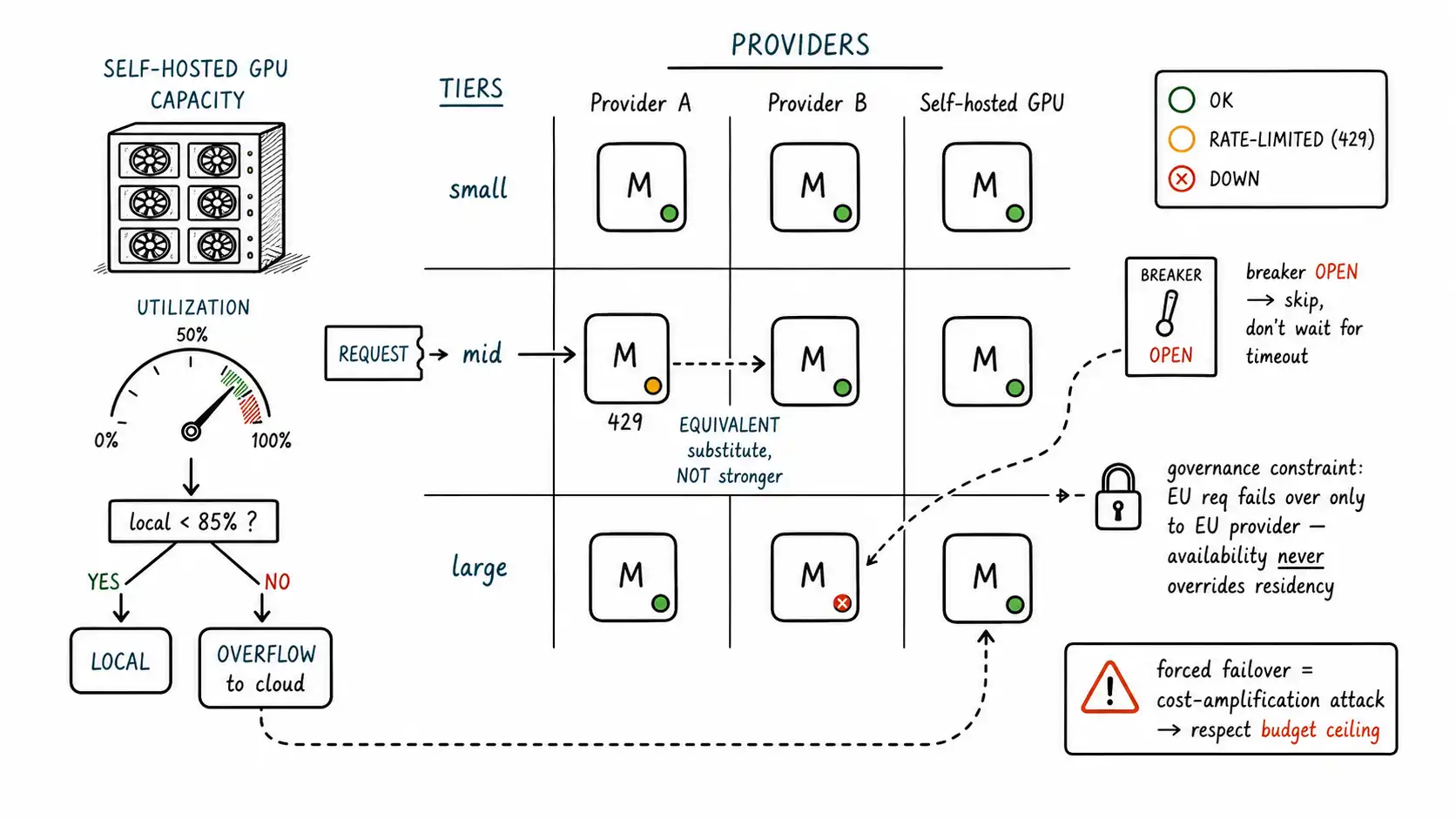
The provider mesh
The provider mesh is the fleet (Chapter 1) viewed through the availability lens: for each tier, you have more than one provider capable of serving it, so that the loss of any one provider does not lose the tier. A mid tier might be served by provider A's mid model and provider B's mid model; if A rate-limits or goes down, B serves the tier. The mesh turns single points of failure into degradable redundancy.
The mesh introduces a subtlety: equivalent models from different providers are not identical. They have different quality, different latency, different prices, and, critically, different governance properties (region, data handling, compliance posture). So the failover substitute must be equivalent on the dimensions that matter for this request: a request gated to an EU-region provider (Chapter 17) must fail over only to another EU-region provider, never to a non-EU one just because it was available. Availability does not override governance. This is the rule that keeps failover from becoming a compliance incident.
# Failover within the mesh, respecting tier AND governance constraints.
def call_with_failover(request, tier, constraints):
# Candidate providers for this tier that ALSO satisfy governance constraints.
candidates = mesh.providers_for(tier, satisfying=constraints) # e.g. region=EU
candidates = order_by_health_and_cost(candidates) # prefer healthy+cheap
last_error = None
for provider in candidates:
if circuit_open(provider): # circuit breaker: skip known-down providers
continue
try:
return provider.call(request, timeout=constraints.timeout_ms)
except RateLimited as e: # 429: back off, try next provider immediately
record_rate_limit(provider); last_error = e; continue
except (Timeout, ServerError) as e: # 5xx / timeout: trip breaker, try next
trip_circuit(provider); last_error = e; continue
# Whole tier unavailable within constraints. This is a REAL incident.
if request.risk_tier in ("high", "critical"):
return route_to_human(request) # do NOT silently downgrade a risky request
raise TierUnavailable(tier, last_error) # surface it; don't mask with a wrong tierThe two governance-shaped lines are the point: satisfying=constraints filters the failover candidates to those that meet the request's governance requirements before availability is even considered, and a tier that is fully unavailable within constraints is surfaced as an incident (or routed to a human for risky requests) rather than masked by silently downgrading to a non-compliant or weaker model. Failover degrades availability gracefully; it never degrades governance or risk floors to stay up.
Circuit breakers and retry storms
Two failure modes of failover itself deserve naming, because failover done naively creates the outages it was meant to survive.
A retry storm happens when many requests hit a degraded provider, all retry simultaneously, and the synchronized retries overwhelm the recovering provider (or the next one in line). The fixes are standard distributed-systems hygiene applied to model calls: exponential backoff with jitter (so retries spread out rather than synchronize), a cap on total retries, and respecting the provider's Retry-After header rather than guessing. OpenAI's guidance is explicit about backoff and rate-limit handling for exactly this reason.
A circuit breaker prevents the system from hammering a provider that is clearly down. After a threshold of failures, the breaker "opens" and the system stops sending requests to that provider for a cooldown window, failing over to the mesh immediately instead of waiting for each request to time out. Periodically it sends a probe ("half-open") to check recovery, and closes when the provider is healthy again. Without a breaker, an outage on one provider means every request to it pays the full timeout before failing over, turning a provider outage into a latency catastrophe across the whole system.
# Circuit breaker state per provider. Stops the system from waiting on a dead provider.
class Breaker:
def __init__(self, fail_threshold=5, cooldown_s=30):
self.failures = 0; self.opened_at = None
self.fail_threshold = fail_threshold; self.cooldown_s = cooldown_s
def is_open(self):
if self.opened_at is None: return False
if time.time() - self.opened_at > self.cooldown_s:
return False # half-open: allow a probe
return True
def record(self, ok):
if ok: self.failures = 0; self.opened_at = None
else:
self.failures += 1
if self.failures >= self.fail_threshold: self.opened_at = time.time()Local vs. cloud: a routing axis, not a religion
A second availability-and-economics decision the mesh embodies: which requests run on locally hosted models (open-weights models on your own GPUs) and which run on cloud provider APIs. This is often framed as an ideological choice, "go local to save money / own your stack" versus "use the frontier APIs", but for a router it is just another routing axis with measurable tradeoffs.
| Dimension | Local / self-hosted | Cloud API |
|---|---|---|
| Marginal cost per request | Low (GPU amortized), if utilization is high | Per-token, predictable |
| Fixed cost | High (GPUs idle when traffic is low) | None |
| Latency | Low, no network egress; controllable | Network + provider queue |
| Capability ceiling | Whatever open-weights you can host | Frontier models |
| Data residency / governance | Total control (data never leaves) | Depends on provider terms |
| Operational burden | You run inference, scaling, upgrades | Provider runs it |
| Availability | Your problem | Provider's SLA |
The economics hinge on utilization: a self-hosted model is cheap per request only if the GPUs are busy. At low or spiky traffic, the idle GPU cost can make "cheap" local inference more expensive per request than a cloud API you pay only when you use. So a common mesh pattern is local-first with cloud overflow: route to the self-hosted model while it has capacity (cheap marginal cost on amortized hardware), and overflow to the cloud API when local capacity is saturated, combining the cost advantage of local at steady state with the elastic availability of cloud at peak. This is a routing decision driven by current local utilization, a live signal the router reads.
# Local-first with cloud overflow. Reads live GPU utilization as a routing signal.
def route_local_or_cloud(request, tier):
if tier_served_locally(tier) and local_utilization(tier) < 0.85:
return call_local(request, tier) # cheap marginal cost, low latency
# Local saturated (or this tier isn't hosted locally): overflow to cloud.
return call_with_failover(request, tier, request.constraints)Governance can force local for some requests regardless of economics: a request whose data must never leave your infrastructure (Chapter 17) is pinned to local, and if local is saturated it queues or sheds rather than overflowing to a cloud provider that the data is not permitted to touch. Residency is a constraint that, like risk, vetoes parts of the routing space, here it vetoes the cloud-overflow option entirely.
Caching interacts with the mesh
A cost subtlety the mesh introduces, connecting back to Chapter 2. Prompt caching is per-provider and per-model: a warm cache on provider A does not help a request that fails over to provider B, which pays full freight for the prefix. So failover has a hidden cost: the requests that fail over lose their cache discount. This is usually acceptable (availability beats cache economics, answering at full price beats not answering), but it means a provider with frequent failovers is quietly more expensive than its sticker price suggests, and a flapping provider (repeatedly tripping and recovering the breaker) thrashes caches across the mesh and inflates cost. The monitoring schema (Chapter 18) should track cache-hit rate by provider so a degraded provider's true cost, including the cache misses it causes downstream, is visible, not hidden.
Abuse note: forced failover
A brief security flag, expanded in Chapter 17. An adversary who can reliably trigger failures on your cheap providers (by exhausting their rate limits, for instance) can force traffic onto more expensive providers or tiers: a cost-amplification attack riding on the failover machinery. OWASP's LLM Top 10 names unbounded consumption as a risk class, and forced failover is one of its routes. The defense is that failover must respect cost ceilings and budget guards (Chapter 17), not just availability: if failing over would breach a budget, the system sheds or queues rather than spending its way into an attacker's trap. Availability is a goal, not an unconditional imperative; a failover path with no cost ceiling is a denial-of-wallet vulnerability.
Chapter summary
Quality routing assumes the chosen model is available; failover is the pattern that keeps the system answering when it is not. It triggers on availability failures, timeouts, 429 rate limits, 5xx errors, outages, and its correct response is a different available equivalent path, not a stronger one; treating every operational hiccup as a reason to escalate to the flagship is the common bug that turns a transient rate-limit spike into a cost blowup. The provider mesh gives each tier more than one provider so no single provider is a single point of failure, but equivalent models differ in quality, price, latency, and governance, so failover must pick a substitute equivalent on the dimensions that matter, and a request gated to an EU-region provider fails over only to another EU-region provider, because availability never overrides residency or risk floors; a fully-unavailable tier is surfaced as an incident, not masked by silent downgrade. Failover done naively creates outages: prevent retry storms with backoff-plus-jitter, capped retries, and honored Retry-After headers, and prevent waiting-on-the-dead with circuit breakers that stop sending to a failed provider and probe for recovery. Local-vs-cloud is a routing axis, not a religion, local is cheap per request only at high GPU utilization, so local-first with cloud overflow reads live utilization as a signal, while residency constraints can pin requests to local and force queue-or-shed instead of overflow. Caching is per-provider, so failover loses the cache discount and a flapping provider thrashes caches, track cache-hit-rate by provider. Finally, an adversary who triggers failures can force traffic onto expensive providers (an OWASP unbounded-consumption route), so failover must respect budget ceilings, not just availability.
Internal map
For the larger argument, keep this chapter connected to Model Routing, The Economics of Inference, the smaller-model margin argument, and A Field Guide to Evals.