Regret, Oracles, and Cost-Weighted Quality
> **Working claim:** The right way to grade a router is to compare it to the best decision it *could* have made. That comparison is *regret*, the quality (or cost) the router gave up by its choice versus an oracle's choice.

Key Takeaways
- Regret, Oracles, and Cost-Weighted Quality is a chapter about model routing and inference control planes, not a generic AI adoption note.
- The operating rule is to send each request to the cheapest path that still meets quality, latency, residency, and risk requirements.
- The failure mode to watch is polished output without evidence, owner, cost line, or rollback path.
- The useful next step is an artifact a future teammate can replay without folklore.
Model routing works when each request goes to the cheapest path that still meets quality, latency, residency, and risk requirements.
Working claim: The right way to grade a router is to compare it to the best decision it could have made. That comparison is regret, the quality (or cost) the router gave up by its choice versus an oracle's choice. Regret turns a tangle of quality, cost, and the four-box matrix into a single, optimizable number, and it reveals the thing accuracy hides: a router can be 95% accurate and still leave most of the available value on the table, or be only 90% accurate and capture nearly all of it.
The oracle: the best a router could do
Imagine a perfect router, an oracle, that knows, for every request, exactly which model will produce an acceptable answer at the lowest cost. The oracle never false-cheaps (it never sends a request to a model that will fail it) and never false-expensives (it never escalates a request the cheap model would have handled). The oracle is not buildable, it would require knowing the outcome before generating, but it is measurable in hindsight: on a labeled dataset where you know how every model did on every request, you can compute what the oracle would have chosen, and therefore the oracle's cost and quality.
The oracle is the benchmark. Your router's job is not "be accurate"; it is "get close to the oracle." Two routers with the same accuracy can be wildly different distances from the oracle, because accuracy ignores which requests they got wrong and how much it cost. The oracle gives you the achievable frontier (Chapter 2 again, now as an evaluation target), and regret measures the gap to it.
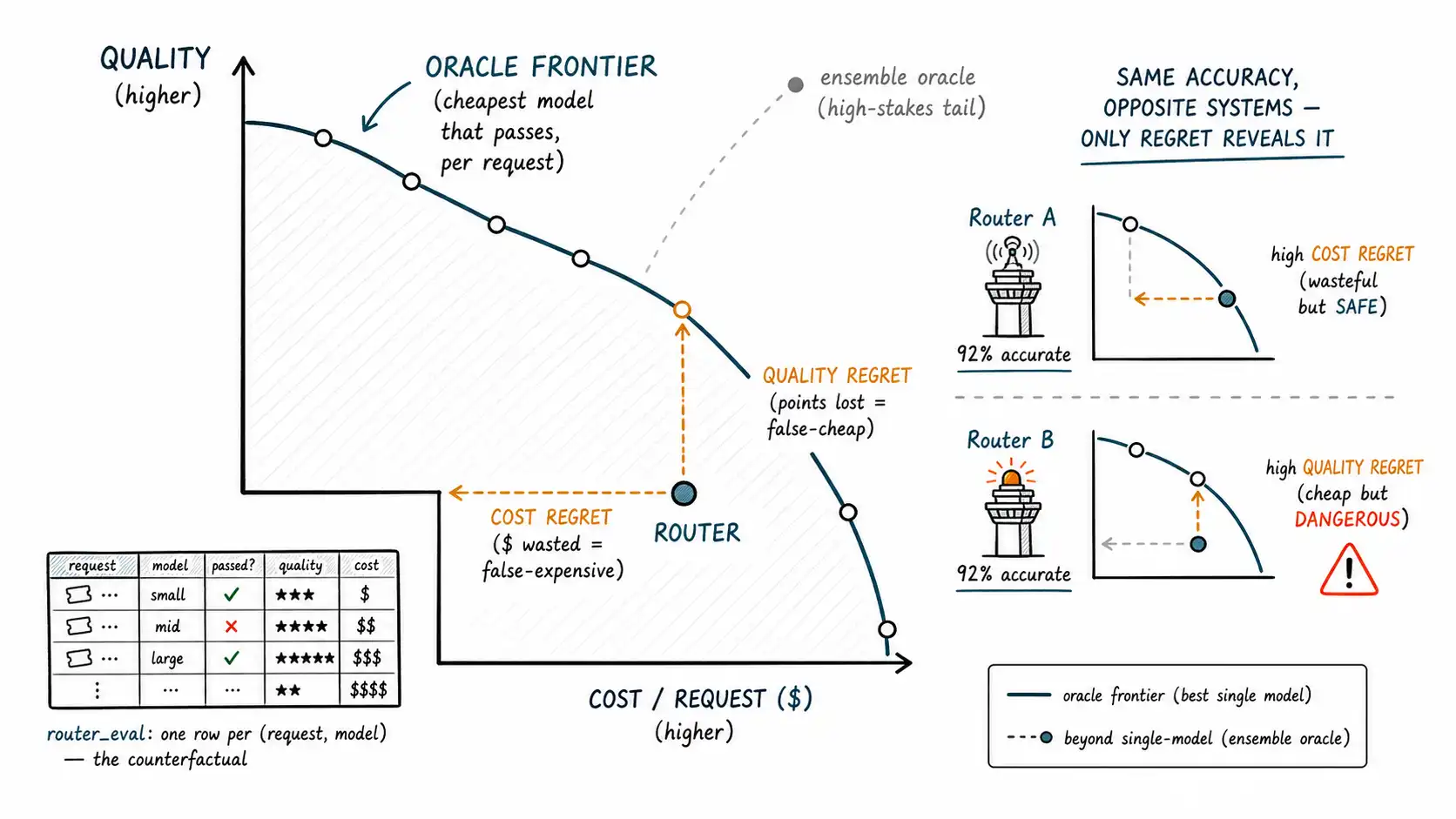
Regret, precisely
Regret is the value lost by the router's choice relative to the oracle's. It comes in two flavors, and a routed system has both:
- Quality regret: at the same cost budget, how much quality did the router give up versus the oracle? If the oracle achieves 94% quality at your cost level and your router achieves 91%, your quality regret is 3 points. This is the cost of false-cheap errors, requests sent to a model that failed them.
- Cost regret: at the same quality level, how much extra did the router spend versus the oracle? If the oracle reaches your quality at $0.004/request and you spend $0.006, your cost regret is $0.002/request. This is the cost of false-expensive errors, unnecessary escalations.
A perfect router has zero regret on both axes (it sits on the oracle frontier). A real router has some of each, and the regret numbers tell you which kind of mistake is costing you more, which is exactly the actionable signal the four-box matrix (Chapter 12) pointed at, now quantified in the currencies that matter. FrugalGPT and RouteLLM both implicitly minimize regret, they trace a cost-quality curve and try to push it toward the oracle frontier, and reporting regret directly is how you tell whether your own router is doing the same or just moving on the line between two single models.
# Regret against an oracle, computed on a labeled dataset where we know how
# EVERY eligible model did on EVERY request (from shadow execution, Ch. 14).
def oracle_choice(request_outcomes, quality_bar, model_cost):
# Cheapest model that clears the bar on THIS request (the perfect decision).
passing = [m for m, ok in request_outcomes.items() if ok] # models that succeeded
if not passing:
return None, float("inf") # nobody could; human/flagship
best = min(passing, key=lambda m: model_cost[m])
return best, model_cost[best]
def regret(dataset, router, quality_bar, model_cost):
router_cost = oracle_cost = 0.0
router_correct = oracle_correct = 0
n = len(dataset)
for ex in dataset:
# What the router did:
chosen = router.choose(ex.request)
router_cost += model_cost[chosen]
router_correct += ex.outcomes[chosen] # did chosen model succeed?
# What the oracle would have done:
o_model, o_cost = oracle_choice(ex.outcomes, quality_bar, model_cost)
oracle_cost += o_cost
oracle_correct += 1 if o_model else 0
return {
"router_quality": router_correct / n, "oracle_quality": oracle_correct / n,
"quality_regret": (oracle_correct - router_correct) / n, # points lost
"router_cost": router_cost / n, "oracle_cost": oracle_cost / n,
"cost_regret": (router_cost - oracle_cost) / n, # $ wasted
}The function reports the router and the oracle side by side and the two regrets between them. The oracle quality is the ceiling (the best any router could do with this fleet), and the gap to it is what tuning targets, a far more honest progress metric than "router accuracy went up, " because it is relative to the achievable best rather than to zero.
Cost-weighted quality: one number when you need one
Two regret numbers are right but sometimes you need one number to optimize or to put on a dashboard, to answer "is policy B better than policy A?" The single number is cost-weighted quality: a scalar that combines quality and cost via an explicit exchange rate. The exchange rate is a business decision, how many dollars is one quality point worth?, and making it explicit is the value, because every routing decision implicitly assumes one and an implicit exchange rate is one nobody can argue with or audit.
# Cost-weighted utility. The exchange rate (dollars per quality point) is an
# EXPLICIT business input, set per slice by risk (Ch. 5).
def utility(quality, cost, dollars_per_quality_point):
# Higher is better. Quality measured in [0,1]; convert points to dollars and subtract cost.
return quality * dollars_per_quality_point - cost
def compare_policies(dataset, policy_a, policy_b, rate_by_slice, model_cost, judge):
def score(policy):
total = 0.0
for ex in dataset:
m = policy.choose(ex.request)
q = 1.0 if judge(ex, ex.answers[m]) else 0.0
rate = rate_by_slice[slice_of(ex.request)] # risk-dependent exchange rate
total += utility(q, model_cost[m], rate)
return total / len(dataset)
return {"policy_a": score(policy_a), "policy_b": score(policy_b)}The crucial detail is rate_by_slice: the dollars-per-quality-point exchange rate is not global. On a high-risk slice a quality point is worth a great deal (you will happily pay more to get it), so the rate is high and the utility function tolerates expensive routing; on a low-risk slice the rate is low and the utility function punishes unnecessary cost. This is, once more, the per-slice risk weighting that has run through the whole book, now expressed as the exchange rate in the objective function the router optimizes. A routed system that optimizes one global cost-weighted quality number under-serves its risky slices and over-spends on its safe ones, the same failure as a global threshold, in the objective rather than the threshold.
The router eval dataset
To compute regret and cost-weighted quality you need a router eval dataset with a specific shape: each example is a request plus every eligible model's outcome on it. This is richer than a model eval dataset (request plus correct answer) because it records the counterfactual, what each model would have done, which is what oracle comparison requires.
-- Router eval dataset: one row per (request, model) with the model's outcome.
-- Populated by shadow execution (Ch. 14) so we know how EVERY model did.
CREATE TABLE router_eval (
request_id TEXT NOT NULL,
slice_key TEXT NOT NULL, -- task_type + domain
risk_tier TEXT NOT NULL,
model TEXT NOT NULL,
answer TEXT,
quality_score REAL, -- from the slice-appropriate grader
passed_bar BOOLEAN, -- quality_score >= slice quality bar
cost_usd REAL NOT NULL,
latency_ms INTEGER NOT NULL,
PRIMARY KEY (request_id, model) -- every model's outcome on every request
);
-- The oracle for a request = cheapest model WHERE passed_bar = true.
-- Regret = router's chosen-model outcome vs. that oracle, aggregated.The PRIMARY KEY (request_id, model) is the structural signature: multiple rows per request, one per model, so the oracle (cheapest model WHERE passed_bar) is a query, not a guess. Building this dataset is the single largest evaluation investment in a routed system, and it is the thing that turns router evaluation from anecdote into measurement.
What regret reveals that accuracy hides
Two routers, both 92% accurate. Router A's 8% errors are false-expensive, it over-escalates but never sends a hard request to a weak model. Router B's 8% errors are false-cheap, it under-escalates and ships wrong answers. Accuracy says they are equal. Regret says they are opposites: Router A has high cost regret and near-zero quality regret (it wastes money but is safe); Router B has high quality regret and near-zero cost regret (it is cheap and dangerous). On a high-risk workload Router A is the right system and Router B is an incident waiting to happen, and only the regret decomposition reveals this, the accuracy number actively hides it.
This is the deepest reason the OpenAI evals guide insistence on task-appropriate, decomposed metrics matters more for routers than for single models: a single model's errors are at least all the same kind (wrong answers), but a router's errors come in two opposite kinds with opposite consequences, and any metric that sums them is hiding the one thing you most need to see. Regret, split into quality regret and cost regret and weighted per slice, is the metric that does not hide it.
Ensembles and the oracle ceiling
A closing connection to Chapter 11. The oracle's quality ceiling is "the best single eligible model on each request." But an ensemble (Chapter 11, LLM-Blender) can sometimes exceed the best single model, so on high-stakes slices the oracle ceiling is not the single-model oracle but the ensemble oracle, which is higher and more expensive. When you evaluate a system that uses ensembles on its high-stakes tail, the oracle benchmark must include the ensemble option, or you will under-measure the achievable quality and conclude (wrongly) that you have low quality regret when in fact a better-fused answer was available. The oracle is always "the best achievable decision given the patterns you allow, " and if ensembles are in your toolkit, they are in your oracle.
Chapter summary
The right way to grade a router is against an oracle, the unbuildable-but-measurable perfect router that always picks the cheapest model that will succeed on each request, and the gap to it is regret. Regret has two flavors that a routed system suffers simultaneously: quality regret (points of quality lost at the same cost, the toll of false-cheap errors) and cost regret (dollars wasted at the same quality, the toll of false-expensive errors), and reporting both tells you which mistake is costing more, the four-box matrix made quantitative in real currencies, exactly the cost-quality curve FrugalGPT and RouteLLM push toward the frontier. When you need a single optimizable number, use cost-weighted quality, which combines quality and cost via an explicit dollars-per-quality-point exchange rate, explicit because every routing decision assumes one anyway, and an implicit one cannot be audited, set per slice by risk so high-risk slices value quality points highly and low-risk slices punish waste. Computing all this requires a router eval dataset keyed on (request, model) so every model's counterfactual outcome is recorded and the oracle ("cheapest model that passed the bar") is a query, not a guess; building it is the largest evaluation investment in a routed system. Regret's payoff is that it reveals what accuracy hides: two 92%-accurate routers can be opposites, one wasteful-but-safe (high cost regret), one cheap-but-dangerous (high quality regret), and any metric that sums the two error kinds conceals the single thing you most need to see. And because ensembles can exceed the best single model, the oracle ceiling on high-stakes slices is the ensemble oracle, which must be in the benchmark whenever ensembles are in the toolkit.
Internal map
For the larger argument, keep this chapter connected to Model Routing, The Economics of Inference, the smaller-model margin argument, and A Field Guide to Evals.