The Cost Waterfall
> **Working claim:** "Cost per request" is not one number; it is a waterfall of components, and a router that models only the first model call is optimizing the smallest part of the bill.

Key Takeaways
- The Cost Waterfall is a chapter about model routing and inference control planes, not a generic AI adoption note.
- The operating rule is to send each request to the cheapest path that still meets quality, latency, residency, and risk requirements.
- The failure mode to watch is polished output without evidence, owner, cost line, or rollback path.
- The useful next step is an artifact a future teammate can replay without folklore.
Model routing works when each request goes to the cheapest path that still meets quality, latency, residency, and risk requirements.
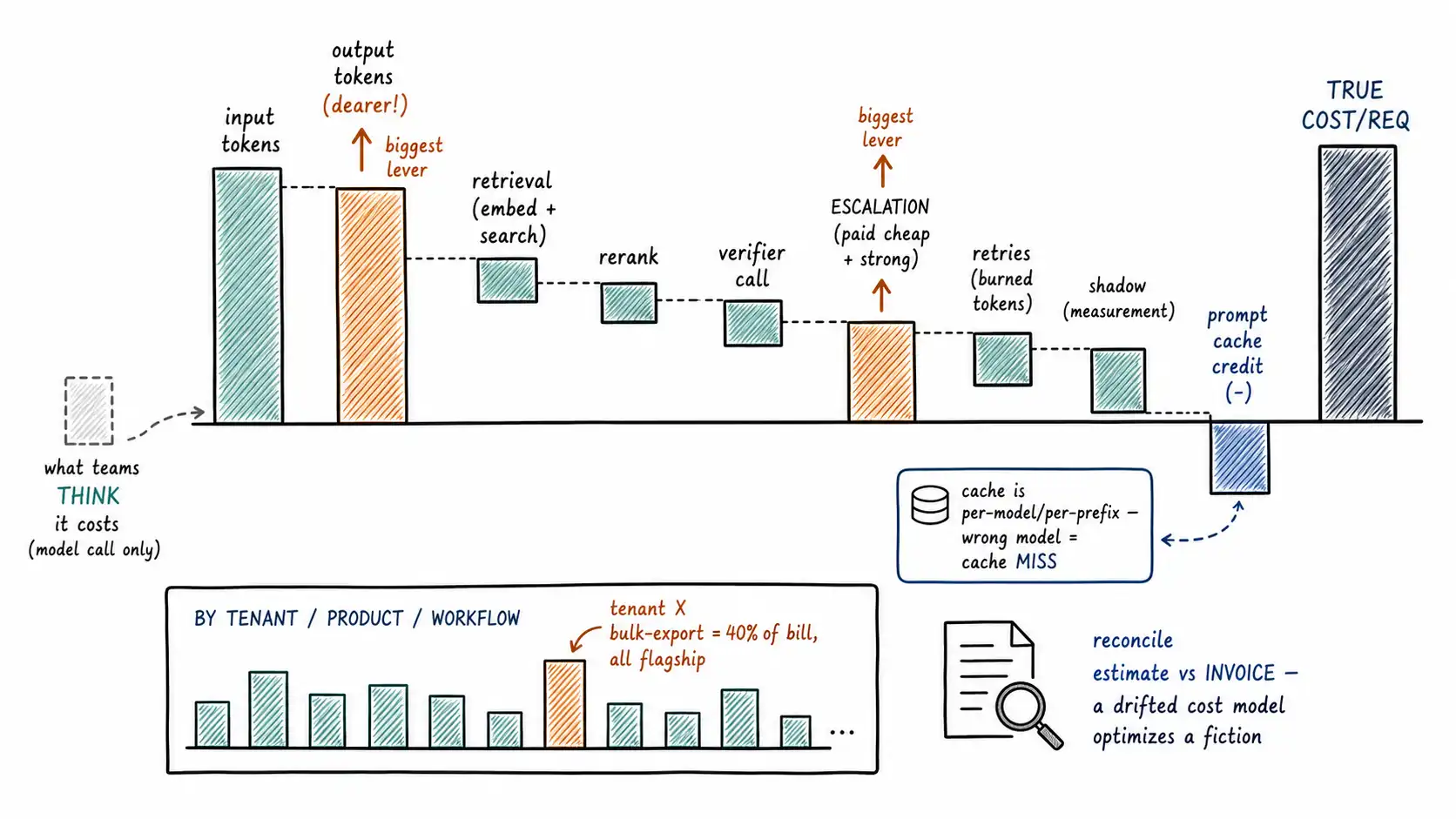
Working claim: "Cost per request" is not one number; it is a waterfall of components, and a router that models only the first model call is optimizing the smallest part of the bill. Input and output tokens are priced asymmetrically, retries and escalations and reranking stack on top, caching can erase most of the input cost or not depending on routing, and the bill belongs to a tenant, a product, and a workflow that finance needs to see. Cost engineering is reading the whole waterfall, not the headline token price.
The bill is a waterfall, not a line item
When a team says a request "costs two cents, " they almost always mean the cost of one model call on the served model. The real cost of a routed request is a waterfall, and every component is a place the router's decisions add or remove money:
- Input tokens to the served model, the prompt, the context, the retrieved passages, the tool schemas.
- Output tokens from the served model, priced differently (usually higher) than input.
- Retrieval: the embedding call and vector search if the request is RAG-shaped.
- Reranking: a reranker model call if retrieved candidates are reranked.
- Verifier / grader calls: the cascade's verifier (Chapter 9), which is itself a model call on many slices.
- Escalation, when a cascade climbs, you pay for the cheap attempt and the strong model (and the verifier again).
- Retries: failed calls that are retried (Chapter 10) are paid for if they consumed tokens before failing.
- Shadow execution: the labeling cost (Chapter 14), small but real, charged to the measurement budget.
A cost model that captures only line 1 will systematically under-estimate the requests that escalate (lines 5-6) and the RAG requests (lines 3-4), which is exactly the cost the router most needs to weigh when deciding whether to escalate. The escalation decision is a cost decision, and you cannot make it on a cost model that ignores the cost of escalating.
# The cost waterfall for one routed request. Every routing decision touches it.
def request_cost(trace, prices):
c = 0.0
for call in trace.model_calls: # may be multiple (cascade, retries)
c += call.input_tokens * prices[call.model].input_per_tok # asymmetric...
c += call.output_tokens * prices[call.model].output_per_tok # ...output dearer
if call.cached_input_tokens: # cached prefix is discounted
c -= call.cached_input_tokens * (prices[call.model].input_per_tok
- prices[call.model].cached_per_tok)
if trace.used_retrieval:
c += trace.embed_tokens * prices["embed"].per_tok + prices["vector_search"].per_query
if trace.used_rerank:
c += prices["rerank"].per_query
c += trace.failed_call_tokens * prices.avg_input # retries that burned tokens
return cThe function makes the waterfall explicit: it sums over all model calls (so a cascade that climbed is correctly more expensive), credits cached input, and adds retrieval, rerank, and burned-retry tokens. This is the cost a router should estimate before deciding, and reconcile after serving, the cost_usd in the Chapter 1 decision log is this number, not the headline price.
Input/output asymmetry changes routing
A pricing fact with routing consequences: output tokens almost always cost more than input tokens, often several times more. This asymmetry means the shape of a request, how much it reads versus how much it writes, matters as much as its total size.
- A request with a huge input and a tiny output (summarize 50 pages into one sentence) is dominated by input cost. It is cheap to generate and the saving lever is input reduction (caching, compression, retrieval instead of full context).
- A request with a small input and a huge output (write a 5,000-word document from a one-line brief) is dominated by output cost. Here the model choice matters most, because output tokens on the flagship are the expensive ones, and routing the generation to a cheaper model (if quality allows) saves the dominant cost.
The router can use this: for input-dominated requests, the model choice matters less for cost (input is cheaper) and aggressive caching matters more; for output-dominated requests, the model choice is the cost decision and the case for routing to a cheaper generator is strongest. FrugalGPT's prompt-adaptation strategy (reducing input via compression and selection) targets the input-dominated case; cheap-model routing targets the output-dominated case. A cost model that does not separate input from output cannot tell which lever applies.
Caching: the discount the router can win or lose
Prompt caching is the single largest cost lever for systems with a large stable prefix, and Chapter 2 already flagged that it is per-model and per-prefix. Here is the cost-engineering detail: caching discounts the cached input tokens steeply (the provider reuses prior computation), so a request whose 10, 000-token system prompt and document context are cached pays the full rate only on the small variable tail. For a system where most of the input is stable across requests, caching can cut input cost by most of it, which can flip which model is cheapest.
The routing interaction is the trap: routing a request to a different model than the previous request on the same shape means a cache miss on the new model, so the "cheaper" model pays full freight for the prefix and can end up more expensive on that single request. The cost model above credits cached_input_tokens per model, and the router should prefer, all else equal, the model whose relevant prefix is already warm, sometimes staying on a nominally-pricier model is cheaper because its cache is hot. This is cache-aware routing, and ignoring it makes a cost-minimizing router accidentally cost-maximizing by thrashing caches.
# Cache-aware cost estimate: the "cheaper" model may be dearer if its cache is cold.
def effective_cost(request, model, cache_state, prices):
n_in, n_out = estimate_tokens(request, model)
prefix_tokens = stable_prefix_tokens(request)
warm = cache_state.is_warm(model, prefix_hash(request)) # this model, this prefix
cached = prefix_tokens if warm else 0
billable_in = n_in - cached
return (billable_in * prices[model].input_per_tok
+ cached * prices[model].cached_per_tok
+ n_out * prices[model].output_per_tok)
# Route by effective_cost, not sticker cost. A cold cache can erase the cheap model's edge.Batch APIs: cost for the patient
For latency-insensitive work (offline enrichment, overnight processing, the batch slices of Chapter 19), providers offer batch APIs at a steep discount relative to real-time. This is a routing axis: a request with no interactive latency requirement can route to a batch lane at a fraction of the real-time price. The cost model should treat "batch-eligible" as a property that unlocks a cheaper price tier, and the router should send everything that can tolerate the delay to batch. The mistake is paying real-time prices for work that had no real-time requirement, overnight report generation served through the interactive path is money set on fire for latency nobody needed. OpenAI's production best practices note batch processing among the levers for cost-efficient operation, and for a router it is simply another tier: the cheapest one, available to the patient.
Cost attribution: whose bill is it?
The aggregate bill is the easy number; the useful number is attribution, which tenant, product, team, and workflow generated the cost."The bill is too high" is not actionable; "tenant X's bulk-export workflow is 40% of the bill and routes everything to the flagship" is. Cost attribution requires that every cost is tagged at the moment it is incurred, with the dimensions finance and product will slice by. This is a logging-schema decision (the Chapter 1 decision log, extended) made before the bill is a problem, because retrofitting attribution onto unattributed cost logs is the same nightmare as retrofitting deletion onto a memory store.
-- Cost attribution: who generated the spend, on what, through which route?
-- Built on the decision log; every routed request contributes one row.
SELECT
tenant,
product_surface,
task_type,
decision_lane, -- 'small' | 'cascade' | 'ensemble' | ...
count(*) AS requests,
sum(cost_usd) AS total_cost,
sum(cost_usd) / sum(count(*)) OVER () AS share_of_total, -- fraction of bill
avg(cost_usd) AS cost_per_req,
avg(CASE WHEN escalated THEN 1.0 ELSE 0.0 END) AS escalation_rate,
sum(CASE WHEN escalated THEN escalation_cost_usd ELSE 0 END) AS escalation_spend
FROM routing_outcomes
WHERE ts > now() - interval '30 days'
GROUP BY tenant, product_surface, task_type, decision_lane
ORDER BY total_cost DESC
LIMIT 50; -- the 50 biggest spend bucketsThis query is the FinOps view of the router. It surfaces the buckets worth optimizing (the top spenders), the slices with high escalation spend (where the cascade is climbing a lot, investigate the verifier threshold, Chapter 9), and per-tenant cost (which feeds usage-based pricing and abuse detection, Chapter 17). The escalation-spend column is especially valuable: it isolates the cost of climbing, which is the cost the router most directly controls and the first place to look when the bill grows faster than traffic.
A cost model is an eval artifact
A closing reframe connecting to the evaluation movement. The cost model is not just an operational tool; it is an evaluation artifact, and like every artifact it must be validated against reality, the OpenAI evals guide discipline applied to cost. Periodically reconcile your estimated per-request cost (what the router predicted) against the actual provider invoice (what you were charged). A persistent gap means your cost model is wrong, usually because it missed a waterfall component (forgotten rerank calls, uncounted retries, mis-modeled caching), and a wrong cost model means every routing decision that traded cost against quality was made on bad numbers. The reconciliation is a routine, not a one-time check, because providers change pricing and your usage patterns change. A router whose cost model has drifted from the invoice is optimizing a fiction, and the fiction always favors whichever component the model forgot.
Chapter summary
"Cost per request" is a waterfall, not a line item: input tokens, output tokens, retrieval, reranking, verifier calls, escalation (you pay the cheap attempt and the strong model), retries that burned tokens, and shadow-execution measurement cost, and a cost model that captures only the served model call under-estimates exactly the escalating and RAG requests whose cost the router most needs to weigh, since the escalation decision is a cost decision. Input and output are priced asymmetrically (output is dearer), so request shape matters: input-dominated requests (big read, small write) are saved by caching and compression while model choice barely moves their cost, and output-dominated requests (small brief, long generation) are saved by routing the generation to a cheaper model, FrugalGPT's prompt-adaptation targets the first, cheap routing the second. Prompt caching is the largest lever for stable-prefix systems but is per-model/per-prefix, so routing to a "cheaper" model can trigger a cache miss that makes it dearer; route by effective (cache-aware) cost, not sticker cost. Batch APIs are a cheap tier for the patient: paying real-time prices for latency-insensitive work is money burned. Cost attribution by tenant, product, workflow, and decision lane turns "the bill is too high" into "tenant X's bulk export is 40% of it on the flagship, " and the escalation-spend column isolates the cost of climbing, the router's most direct lever. Finally, the cost model is an eval artifact: reconcile estimated cost against the actual invoice as a routine, because a drifted cost model makes every cost-quality routing tradeoff on bad numbers and the error always favors whichever waterfall component it forgot.
Internal map
For the larger argument, keep this chapter connected to Model Routing, The Economics of Inference, the smaller-model margin argument, and A Field Guide to Evals.