Static, Dynamic, Cascade, Fallback, Ensemble: Five Words That Are Not Synonyms
> **Working claim:** "Routing" is used as one word for at least five different architectures, and they have different costs, different failure modes, and different reasons to exist.

Key Takeaways
- Static, Dynamic, Cascade, Fallback, Ensemble: Five Words That Are Not Synonyms is a chapter about model routing and inference control planes, not a generic AI adoption note.
- The operating rule is to send each request to the cheapest path that still meets quality, latency, residency, and risk requirements.
- The failure mode to watch is polished output without evidence, owner, cost line, or rollback path.
- The useful next step is an artifact a future teammate can replay without folklore.
Model routing works when each request goes to the cheapest path that still meets quality, latency, residency, and risk requirements.
Working claim: "Routing" is used as one word for at least five different architectures, and they have different costs, different failure modes, and different reasons to exist. A team that says "we have routing" without saying which kind usually has a tangle of two or three of them fighting each other. Naming them precisely is the first design decision, not a vocabulary nicety.
The five architectures
The word "routing" hides five distinct things. Here they are, each defined by when the decision is made and how many models a single request touches.
Static routing decides where a request goes from properties known before any model runs, task type, tenant, a length threshold, a content flag. One request touches one model. The decision is a lookup, deterministic and cheap, and it never reconsiders."Code requests go to the code specialist; everything else goes to the workhorse" is static routing.
Dynamic routing also picks one model up front, but the decision uses a learned or computed prediction of the request's difficulty or the likely winner, not just static properties. One request still touches one model, but the routing function is a model itself (a classifier, an embedding-based predictor, a preference-trained router). RouteLLM is dynamic routing in this precise sense: it trains a router on human-preference data to predict, before generation, whether the weak or strong model should handle the query, and routes accordingly, a single model call, chosen by a smarter upstream decision.
Cascade is sequential. A request goes to a cheap model first; a verifier checks the result; if the verifier is satisfied, the request stops there; if not, it escalates to a stronger model and the verifier runs again. One request may touch several models, but only as far up the ladder as it needs to climb. FrugalGPT's LLM cascade is the canonical version: it runs models in increasing order of cost and stops at the first whose answer a learned scorer deems good enough. The defining property is that the decision to use a bigger model is made after seeing the cheap model's actual answer, not predicted in advance.
Fallback looks like a cascade but is not. A fallback escalates on failure, not on difficulty: the primary model timed out, returned an error, hit a rate limit, or the provider is down, so the request is retried on a different model or provider. The trigger is operational, not quality-driven. A fallback exists to keep the system available; a cascade exists to make it cheap-but-correct. They use similar machinery (try one, then try another) and answer completely different questions, and the most common confusion in this entire chapter is treating one as the other.
Ensemble runs multiple models on the same request on purpose and combines their outputs: by voting, by reranking, or by generative fusion. Unlike a cascade, an ensemble does not stop early; it pays for several models every time in order to buy quality no single model offers. LLM-Blender is the reference: it runs several LLMs, ranks their candidate outputs pairwise, and then fuses the top candidates into a single answer that beats any individual model. Ensembles are the most expensive pattern and the only one whose purpose is to exceed the best single model rather than approximate it cheaply.
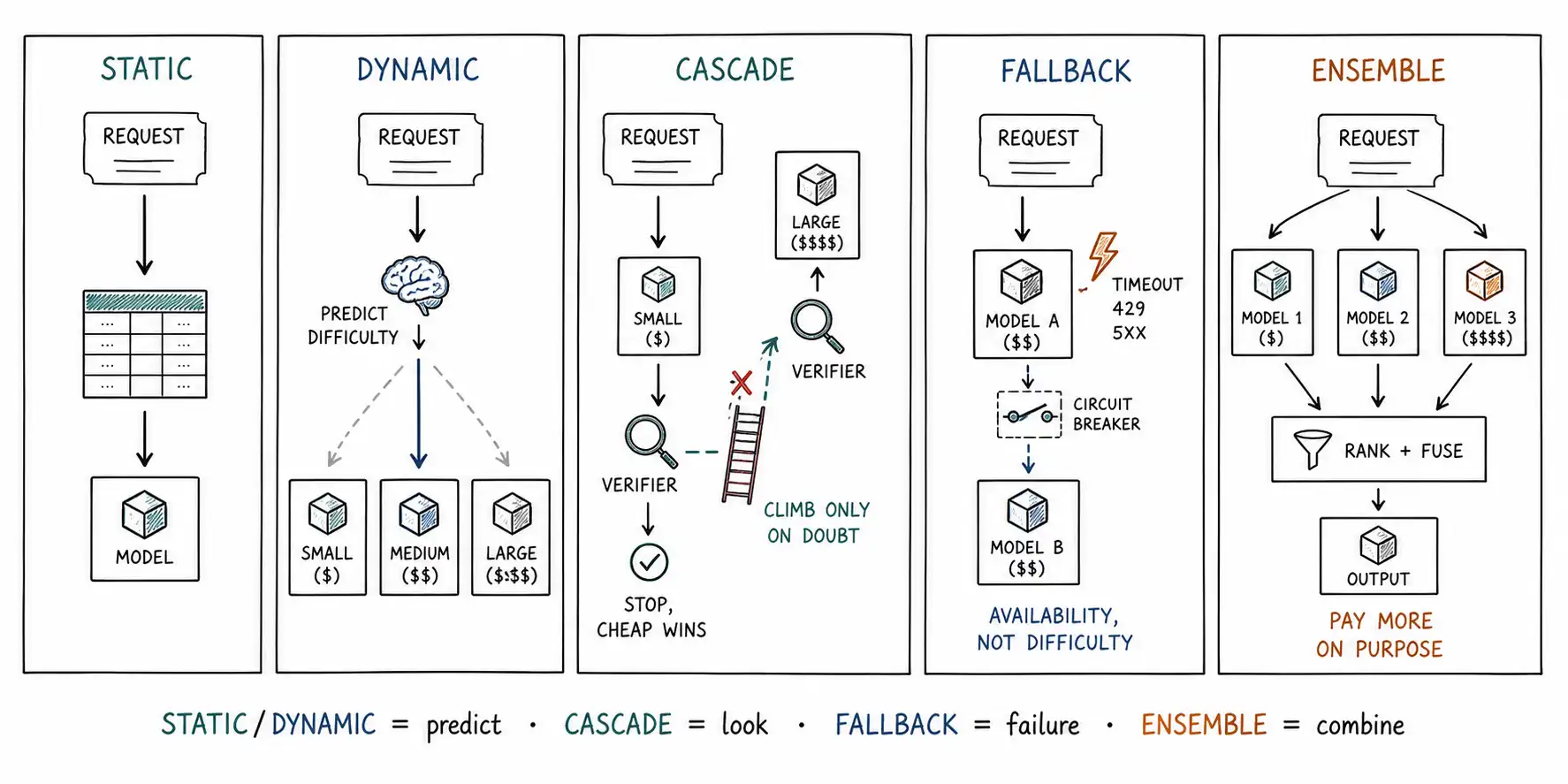
The decision in one table
| Architecture | Decision made | Decision based on | Models per request | Primary purpose | Primary failure mode |
|---|---|---|---|---|---|
| Static | Before any call | Fixed properties (task, tenant, length) | 1 | Simple, predictable routing | Misroutes when properties mislead (length lies) |
| Dynamic | Before any call | Learned difficulty / win prediction | 1 | Right-size per request, one call | Router model is itself wrong / drifts |
| Cascade | After cheap call | The cheap model's actual answer + verifier | 1 to N (climbs on doubt) | Cheapest-that-works | Verifier is wrong → false stop or runaway escalation |
| Fallback | After failure | Errors, timeouts, rate limits, outages | 1 + retries | Availability | Retry storms; masking real degradation |
| Ensemble | Always (parallel) | Multiple outputs combined | N (every time) | Exceed best single model | Pure cost multiplier; combiner can be worse than best member |
The table is the chapter. Most of the rest of the book is elaborating one row at a time. But two distinctions in it cause more production grief than the others, so they get their own sections.
Dynamic routing vs. cascade: predict, or look?
This is the deepest fork in the design space, and it is a genuine tradeoff, not a "best practice."
A dynamic router predicts difficulty before running anything and commits to one model. Its advantage is one call: no wasted cheap-model attempt, no second-model latency, the lowest possible cost-and-latency floor when the prediction is right. Its weakness is that the prediction is made blind, without seeing any answer, so it can only use signals available up front, and those signals (Chapter 4-7) are imperfect. When the predictor is wrong, the request gets the wrong model and there is no recovery within the request; the error is silent.
A cascade looks before it escalates: it runs the cheap model, sees the actual answer, and lets a verifier judge it. Its advantage is that the escalation decision uses the strongest possible signal, the answer itself, which is far more informative than any pre-generation prediction. Its weakness is cost and latency: when the cheap model fails, you have paid for it and the strong model, and the verifier, and the user waited for two model calls in series. A cascade is strictly more expensive than dynamic routing on the requests that escalate, and strictly slower on them.
The practical synthesis, used by mature systems, is to combine them: use a dynamic router to send the obviously-hard and obviously-risky requests straight to the strong lane (skip the doomed cheap attempt), use a cheap default for the obviously-easy, and reserve the cascade for the uncertain middle where looking is worth the cost of looking. The router decides whether to predict-and-commit or to look-and-climb based on its confidence in its own prediction. This is the architecture Chapters 8 and 9 build toward.
# Combining dynamic prediction with selective cascading.
# The router predicts; only the UNCERTAIN band actually cascades.
def route(request):
risk = risk_tier(request) # Chapter 5: risk gates first
if risk == "high":
return call_with_floor(request, min_tier="flagship") # no cheap attempt
difficulty = predict_difficulty(request) # Chapters 4-7: a learned predictor in [0,1]
if difficulty < 0.3: # confidently easy: predict-and-commit cheap
return call(request, model="small-hosted")
if difficulty > 0.8: # confidently hard: predict-and-commit strong
return call(request, model="flagship")
# Uncertain middle: LOOK. Run cheap, verify, escalate only on doubt.
cheap_answer = call(request, model="small-hosted")
if verifier_ok(request, cheap_answer):
return cheap_answer
return call(request, model="flagship") # cascade escalationThe shape to notice: the cascade is not the default path. It is the path for the band where neither predict-cheap nor predict-strong is confident enough. Cascading everything pays the look-cost on requests where the prediction was already reliable; predicting everything gives up the strongest signal (the answer) on requests where the prediction is shaky. The router's intelligence is in the boundaries between these bands, which evaluation (Movement IV) tunes.
Fallback vs. cascade: failure is not difficulty
The second grief-causing confusion. A fallback and a cascade both "try another model when the first one doesn't work out, " and teams routinely wire them into the same code path. They must not be the same code path, because the triggers are different and the response should be different.
A cascade escalates because the answer was not good enough, the verifier judged the cheap model's content insufficient. The right response is a stronger model, because the problem is capability. A fallback escalates because the call did not complete, a timeout, a 500, a 429 rate-limit, a provider outage. The right response is a different available model or provider, which might be the same tier or even cheaper, because the problem is availability, not capability. Sending a timed-out cheap request to the flagship "to be safe" is a category error: you do not know the cheap model would have failed on quality; you only know the network or the provider hiccuped. You should retry on an equivalent path first.
The failure matrix below disentangles them. It is the contract every routed request handler should implement explicitly.
| Trigger | Category | Correct response | Wrong response (common) |
|---|---|---|---|
| Verifier says answer insufficient | Quality | Escalate to stronger model (cascade) | Treat as outage; failover blindly |
| Timeout on model call | Availability | Retry equivalent model/provider (fallback); then escalate only if pattern persists | Escalate to flagship every timeout (cost blowup) |
| HTTP 429 rate limit | Availability | Back off + route to alternate provider of same tier | Hammer the same endpoint (retry storm) |
| HTTP 5xx / provider outage | Availability | Failover to alternate provider; open a circuit breaker | Retry same provider in a tight loop |
| Content-safety refusal | Policy | Route to human or a policy-appropriate path | Retry on a different model to "get past" the refusal |
| Malformed / unparseable output | Quality-ish | One reformat retry, then escalate | Infinite reparse loop |
The last row of the wrong response column, "retry on a different model to get past the refusal", is worth flagging because it is both a quality bug and a governance bug: routing around a safety refusal is exactly the kind of guardrail bypass Movement VI is about. A failover path that is allowed to pick any model can become an accidental safety-bypass path. Fallback must respect the same capability and policy constraints as primary routing.
Ensembles: paying more on purpose
Ensembles are the odd member of the family because every other architecture is trying to spend less, and an ensemble is trying to spend more, deliberately, every time, to get an answer better than any single model. They earn their cost only in two situations. The first is high-stakes requests where the marginal quality is worth a multiple of the cost: a critical extraction, a legal summary, a medical triage note, where being right matters far more than being cheap and you would happily pay three models to agree. The second is offline settings, batch enrichment, dataset construction, label generation, where latency is irrelevant and you are buying the best possible output to cache and reuse, so the per-item ensemble cost is amortized across every future read of that result.
LLM-Blender is worth understanding precisely because it shows ensembling is not just "majority vote." It does two things: a ranker that compares candidate outputs pairwise to find the best among them, and a fuser that generates a new answer combining the strengths of the top candidates, and the fused answer outperforms simply picking the single best candidate. The lesson for a router is that the combiner is a real component with its own quality, not a free max(). A naive ensemble that takes a majority vote among three mediocre models can be worse than one good model, because the combiner imported the errors. If you build an ensemble, evaluate the combiner as carefully as you evaluate the members, and never assume more models means more quality.
Where the router lives
Across all five architectures, the router is a control-plane component (Chapter 1's framing) that sits in front of the model calls and implements the chosen architecture as policy. The OpenAI production best practices guidance, on timeouts, retries with backoff, rate-limit handling, and graceful degradation, is, read through a routing lens, largely about the fallback row of this taxonomy: how to keep the data plane available. The other rows (static, dynamic, cascade, ensemble) are about which model to call when calls do succeed. A complete router implements both: a selection policy (static/dynamic/cascade/ensemble) for the happy path and a resilience policy (fallback) for the failure path, kept conceptually separate even when they share an HTTP client.
Chapter summary
"Routing" names five different architectures, separated by when the decision is made and how many models a request touches. Static routing picks one model from fixed properties before any call;dynamic routing picks one model from a learned difficulty or win prediction (RouteLLM); cascade runs a cheap model, looks at the answer through a verifier, and climbs to a stronger model only on doubt (FrugalGPT); fallback retries on a different path when a call fails for operational reasons; and ensemble runs several models every time and combines them to exceed the best single model (LLM-Blender). The deepest fork is dynamic-vs-cascade, predict and commit (one call, blind, cheap when right) versus look and climb (strongest signal, but pay for two calls on escalation), and mature systems combine them, committing on the confidently-easy and confidently-hard ends and cascading only the uncertain middle. The most damaging confusion is fallback-vs-cascade: a cascade escalates on quality and the fix is a stronger model, while a fallback escalates on availability and the fix is an equivalent available model, so routing a timed-out request to the flagship "to be safe, " or retrying a safety refusal on another model to "get past" it, are both category errors (and the second is a guardrail bypass). Ensembles are the lone pay-more pattern, justified only on high-stakes or offline-cacheable work, and their combiner is a real component that can make three mediocre models worse than one good one. A complete router keeps a selection policy and a resilience policy conceptually separate even when they share a client.
Internal map
For the larger argument, keep this chapter connected to Model Routing, The Economics of Inference, the smaller-model margin argument, and A Field Guide to Evals.