Ensembles, Voting, and Rerank-and-Fuse
> **Working claim:** Every pattern so far tried to spend *less*. An ensemble spends *more*, several models on the same request, every time, to buy an answer better than any single model can give.

Key Takeaways
- Ensembles, Voting, and Rerank-and-Fuse is a chapter about model routing and inference control planes, not a generic AI adoption note.
- The operating rule is to send each request to the cheapest path that still meets quality, latency, residency, and risk requirements.
- The failure mode to watch is polished output without evidence, owner, cost line, or rollback path.
- The useful next step is an artifact a future teammate can replay without folklore.
Model routing works when each request goes to the cheapest path that still meets quality, latency, residency, and risk requirements.
Working claim: Every pattern so far tried to spend less. An ensemble spends more, several models on the same request, every time, to buy an answer better than any single model can give. That only pays off in two places: high-stakes requests where quality dwarfs cost, and offline work where the expensive answer is computed once and cached forever. And the combiner that merges the models is itself a component with quality of its own: a bad combiner can make three good models worse than one.
The pattern that runs against the grain
Cascades, dynamic routers, and failover all share a goal: touch the fewest, cheapest models that suffice. An ensemble inverts that. It deliberately runs multiple models on the same request and combines their outputs, paying for all of them every time. It is the one routing pattern whose purpose is not to approximate the best single model cheaply but to exceed it, to produce an answer no member could have produced alone.
This is a real capability, not a hope. LLM-Blender demonstrates it cleanly: running several LLMs on a task, ranking their candidate outputs pairwise to find the best, and then fusing the top candidates into a single generated answer that outperforms any individual model and outperforms simply picking the best candidate. The mechanism is that different models make different errors and have different strengths; an ensemble that combines them well captures the union of their strengths and cancels some of their independent errors. The catch is in "combines them well", the combiner is where ensembles succeed or fail.
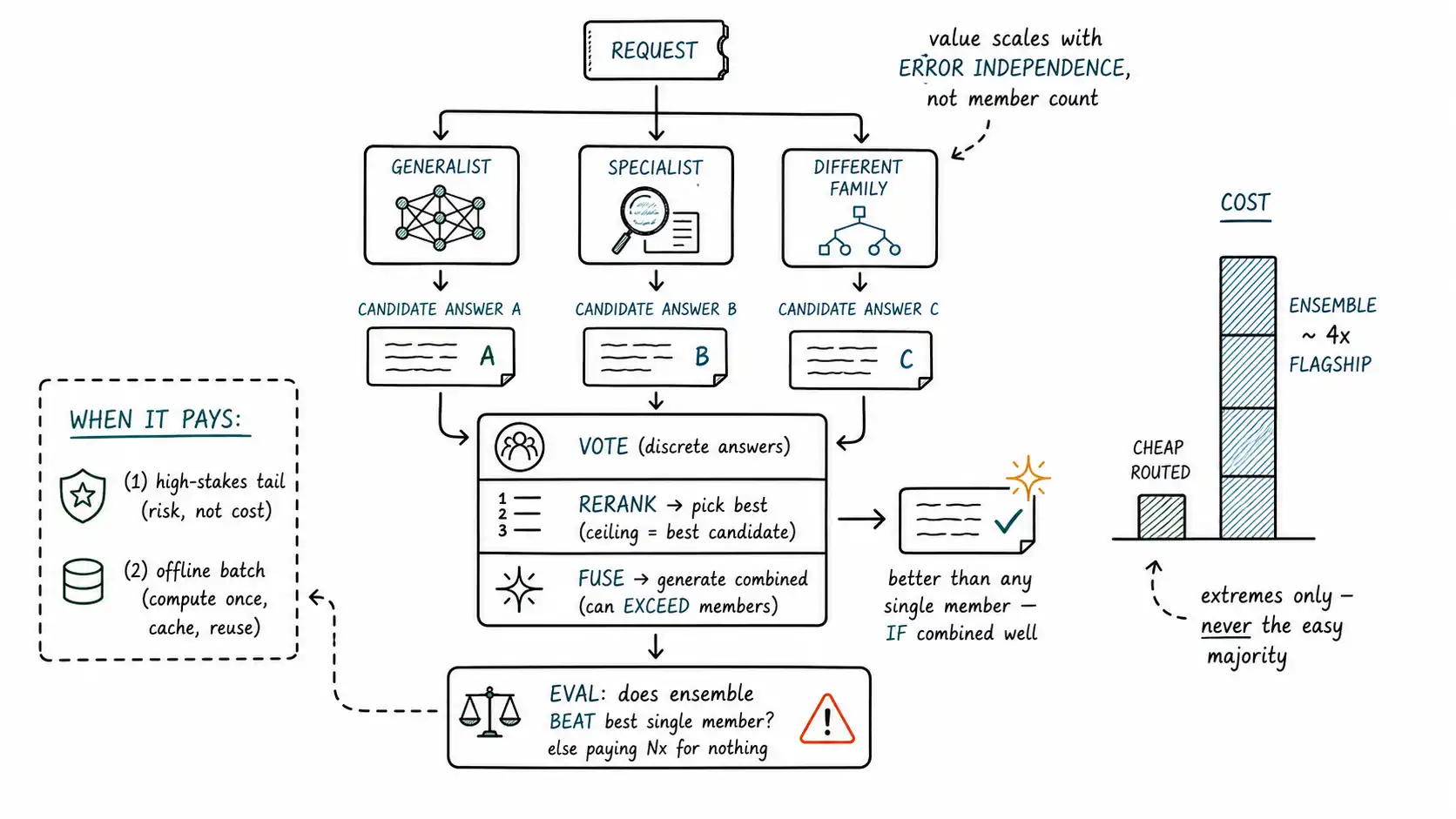
Three ways to combine
There are three combining strategies, in ascending order of sophistication and cost.
Voting (consensus) runs N models (or one model N times) and takes the majority or most-agreed answer. It works for tasks with a discrete, comparable answer, a classification label, a multiple-choice pick, a yes/no, a number, where "agreement" is well-defined. It does not work for open-ended generation, where two correct answers can be worded completely differently and "majority" is meaningless. Voting is also the basis of SelfCheckGPT's consistency check, which is voting used as a confidence signal (Chapter 6) rather than as an answer-selection mechanism, the same machinery, a different purpose.
Reranking (selection) runs N models, gets N candidate answers, and uses a ranker to pick the single best one. The ranker is a separate model or scorer that judges candidate quality. This works for open-ended generation because it does not require the answers to match: it just picks the best. LLM-Blender's PairRanker is exactly this: a model trained to compare candidates pairwise and surface the best. Reranking is strictly better than voting for generative tasks, and its quality is bounded by the best candidate any model produced: it can select but not improve.
Fusion (generation) runs N models, gets N candidates, and generates a new answer that combines their strengths, LLM-Blender's GenFuser. Fusion can exceed the best individual candidate, because it can take the correct introduction from one answer and the correct conclusion from another. It is the most powerful and the most expensive (an extra generation pass on top of the N members), and its quality depends entirely on the fuser model's skill at synthesis, a weak fuser can introduce errors that none of the candidates had.
| Combiner | How it picks/builds the answer | Works for | Ceiling | Risk |
|---|---|---|---|---|
| Voting | Majority / most-agreed | Discrete answers (labels, numbers, yes/no) | Best agreed answer | Meaningless on open-ended text |
| Reranking | A ranker selects best candidate | Open-ended generation | Best candidate produced | Ranker picks a bad candidate |
| Fusion | A model generates a combined answer | Open-ended generation | Above best candidate | Fuser introduces new errors |
The combiner is a real component
The chapter's central warning: a naive ensemble can be worse than its best member. Three mediocre models voting can outvote the one correct model. A reranker can systematically prefer fluent-but-wrong answers over terse-but-right ones. A fuser can blend two correct answers into an incorrect synthesis. The ensemble's quality is not max(member_quality); it is a function of the combiner, and the combiner has to be evaluated as carefully as any model in the system.
This is exactly the OpenAI evals guide discipline applied to the combiner: build an eval that compares the ensemble's output against the best single member on your task, and confirm the ensemble actually wins. If it does not, and naive ensembles frequently do not, you are paying N times the cost for negative value. The most common ensemble anti-pattern is shipping a voting or fusion ensemble on faith that "more models = better" without measuring the combiner, and discovering months later that a single model would have been cheaper and better.
# An ensemble whose combiner is EVALUATED, not assumed.
def ensemble_answer(request, members, combiner):
candidates = [call(request, model=m) for m in members] # pay for all, every time
if combiner == "vote":
return majority_vote(candidates) # discrete answers only
if combiner == "rerank":
return rerank_select(request, candidates, ranker=PAIR_RANKER)
if combiner == "fuse":
best_k = rerank_topk(request, candidates, k=3, ranker=PAIR_RANKER)
return generative_fuse(request, best_k, fuser=FUSER_MODEL) # can exceed members
# The eval that MUST pass before trusting any ensemble in production:
def ensemble_beats_best_member(eval_set, members, combiner, judge):
ens_wins = best_member_wins = 0
for ex in eval_set:
ens = ensemble_answer(ex.request, members, combiner)
best = best_single_member(ex.request, members, judge)
if judge.prefers(ens, best): ens_wins += 1
else: best_member_wins += 1
# If the ensemble doesn't clearly win, you're paying N x cost for nothing.
return ens_wins / (ens_wins + best_member_wins)When ensembles earn their cost
An ensemble pays N times for one answer, so it earns its keep only where that multiple is justified. Two situations.
High-stakes interactive requests where quality dwarfs cost. A critical medical-triage note, a legal-clause interpretation a deal hinges on, a high-value extraction feeding an automated decision, requests where being right is worth paying three or five models and a fuser. Note these are exactly the high-risk slices from Chapter 5, where the risk floor already pushes toward strong models; an ensemble is the next step up from "use the flagship" when even the flagship's single-shot reliability is not enough. The risk axis, not the cost axis, justifies the ensemble.
Offline batch work where latency is irrelevant and the answer is cached and reused. Building a knowledge base, generating training labels, enriching a dataset, producing canonical summaries, here you run the best possible ensemble once per item and amortize its cost across every future read. The per-item ensemble cost, divided by the number of times the cached result is read, can be trivial. Offline is where ensembles are least controversial, because the usual objections (cost, latency) mostly vanish: you are buying the best possible artifact and reusing it.
The places ensembles do not belong are the converse: latency-tight interactive requests (running N models in series blows the latency budget; in parallel it blows the cost budget) and low-stakes high-volume traffic (the easy majority, where even one cheap model suffices and an ensemble is pure waste). An ensemble on the easy majority is the most expensive way to over-serve a request that needed almost nothing.
Ensembles, cascades, and diversity
A design insight that connects the patterns. A cascade and an ensemble can be combined: cascade normally, but for the requests that reach the top of the ladder (the hard ones that even the strong model is uncertain on), ensemble at the top, run the flagship alongside a specialist and fuse, rather than returning a single uncertain flagship answer. This focuses the ensemble's expense exactly where it is justified (the hard tail that escalated all the way up) and avoids paying it on the easy majority that stopped at the bottom rung. The cascade does the cost control; the ensemble does the quality push at the apex.
The other design insight is diversity. An ensemble of N copies of the same model (different temperatures) gives you consistency information (SelfCheckGPT's use) but limited quality gain, because the members share the same blind spots, they make correlated errors. An ensemble of different models (different training, different families, a specialist among generalists) gives a real quality gain, because the members make independent errors that the combiner can cancel. The value of an ensemble scales with the independence of its members' errors, not the count of members. Three near-identical models are barely an ensemble; one generalist, one specialist, and one different-family model is a real one. LLM-Blender's gains come precisely from combining diverse models, and an ensemble built without attention to diversity is paying for redundancy rather than buying coverage.
The cost reality
To close, the arithmetic, because it is the thing that keeps ensembles rare. An ensemble of three flagship-class models plus a fuser costs roughly four flagship calls per request. Against a routed system that sends most traffic to a cheap model, an all-ensemble system is dozens of times more expensive. This is why ensembles live at the extremes, the high-stakes tail and the offline reuse case, and never in the middle. FrugalGPT's entire thesis is the opposite direction (spend less on the easy majority), and the two coexist precisely because they target opposite ends of the workload: cascades and cheap routing for the fat easy head, ensembles for the thin high-stakes tail. A system that understands its workload as a distribution (Chapter 1) uses both, cheap routing where most of the volume is, ensembles where the value is, and uses neither everywhere.
Chapter summary
An ensemble runs against the grain of every other pattern: it spends more, several models on the same request, every time, to produce an answer no single member could, which LLM-Blender demonstrates by ranking diverse candidates and fusing the best into an output that beats any individual model. There are three combiners in ascending power and cost: voting (majority over discrete answers; meaningless on open-ended text, and the same machinery SelfCheckGPT uses as a confidence signal), reranking (a ranker selects the best candidate; ceiling is the best candidate produced), and fusion (a model generates a combined answer that can exceed every candidate). The central warning is that the combiner is a real component, a naive ensemble can be worse than its best member, because mediocre models can outvote the right one, a reranker can prefer fluent-but-wrong, and a fuser can blend two correct answers into an incorrect one, so the combiner must be evaluated against the best single member before it is trusted, or you are paying N times cost for negative value. Ensembles earn their keep only at the extremes: high-stakes slices (justified by the risk axis, not cost, the next step up from "use the flagship") and offline batch work (compute once, cache, reuse, amortizing the multiple), and never on the latency-tight or low-stakes high-volume middle. Combine them with cascades by ensembling only at the apex of the ladder where hard requests escalated, and remember that ensemble value scales with the error independence of diverse members, not their count, three near-identical models are redundancy, not coverage. The arithmetic (an ensemble is roughly four flagship calls) is why ensembles stay rare and coexist with FrugalGPT-style cheap routing: opposite ends of the same workload distribution.
Internal map
For the larger argument, keep this chapter connected to Model Routing, The Economics of Inference, the smaller-model margin argument, and A Field Guide to Evals.