The Bill That Broke the One-Model Religion
> **Working claim:** A single-model architecture is not a neutral default. It is a bet that your workload is uniform, that every request deserves the same model.

Key Takeaways
- The Bill That Broke the One-Model Religion is a chapter about model routing and inference control planes, not a generic AI adoption note.
- The operating rule is to send each request to the cheapest path that still meets quality, latency, residency, and risk requirements.
- The failure mode to watch is polished output without evidence, owner, cost line, or rollback path.
- The useful next step is an artifact a future teammate can replay without folklore.
Model routing works when each request goes to the cheapest path that still meets quality, latency, residency, and risk requirements.
Working claim: A single-model architecture is not a neutral default. It is a bet that your workload is uniform, that every request deserves the same model. Real workloads are never uniform, and the bet is settled, eventually, by either the finance team or the incident channel. The router exists because the workload is a distribution, and a distribution wants a distribution of responses.
Two failures with opposite knobs
Start with the arithmetic that ends most one-model religions, because the arithmetic is the whole argument compressed.
Suppose you run a million requests a month. Suppose your flagship model costs, all-in, roughly two cents per request once you count the input context, the output, and the second call you make to check the first. A small model, on the same requests, costs roughly a fifth of a cent. The flagship bill is $20, 000 a month; the small-model bill is $2,000. That ten-to-one ratio is not exotic. FrugalGPT opens by observing that pricing across popular LLM APIs can differ "by two orders of magnitude", a hundred-to-one between the cheapest and the most expensive options: so a ten-to-one gap between your cheap lane and your flagship is a conservative, everyday spread.
Now layer in quality. Say the flagship answers 95% of your requests acceptably and the small model answers 80%. Averaged over the whole workload those look like a tolerable 15-point gap. But the average is the lie. Decompose the workload and the 80% resolves into something sharper: the small model is right 99% of the time on the easy majority and 45% of the time on the hard minority, and the flagship is right 99% on the easy majority too, identical, and 80% on the hard minority. On the easy requests, the flagship buys you nothing and costs you ten times as much. On the hard requests, the flagship buys you a real 35 points and is worth every cent. The single number "95% vs 80%" hid both facts.
This is why the two one-model experiments both fail, and fail in instructive ways. Flagship-everywhere is correct and pays the ten-times tax on the seventy percent of traffic that never needed it. Cheap-everywhere captures the savings and eats the 45%-correct disaster on the hard minority, where wrong answers are not merely wrong but expensive, escalations, complaints, churn, occasionally liability. Neither knob is wrong because the model is wrong. They are wrong because a single knob cannot express a workload that has more than one kind of request in it.
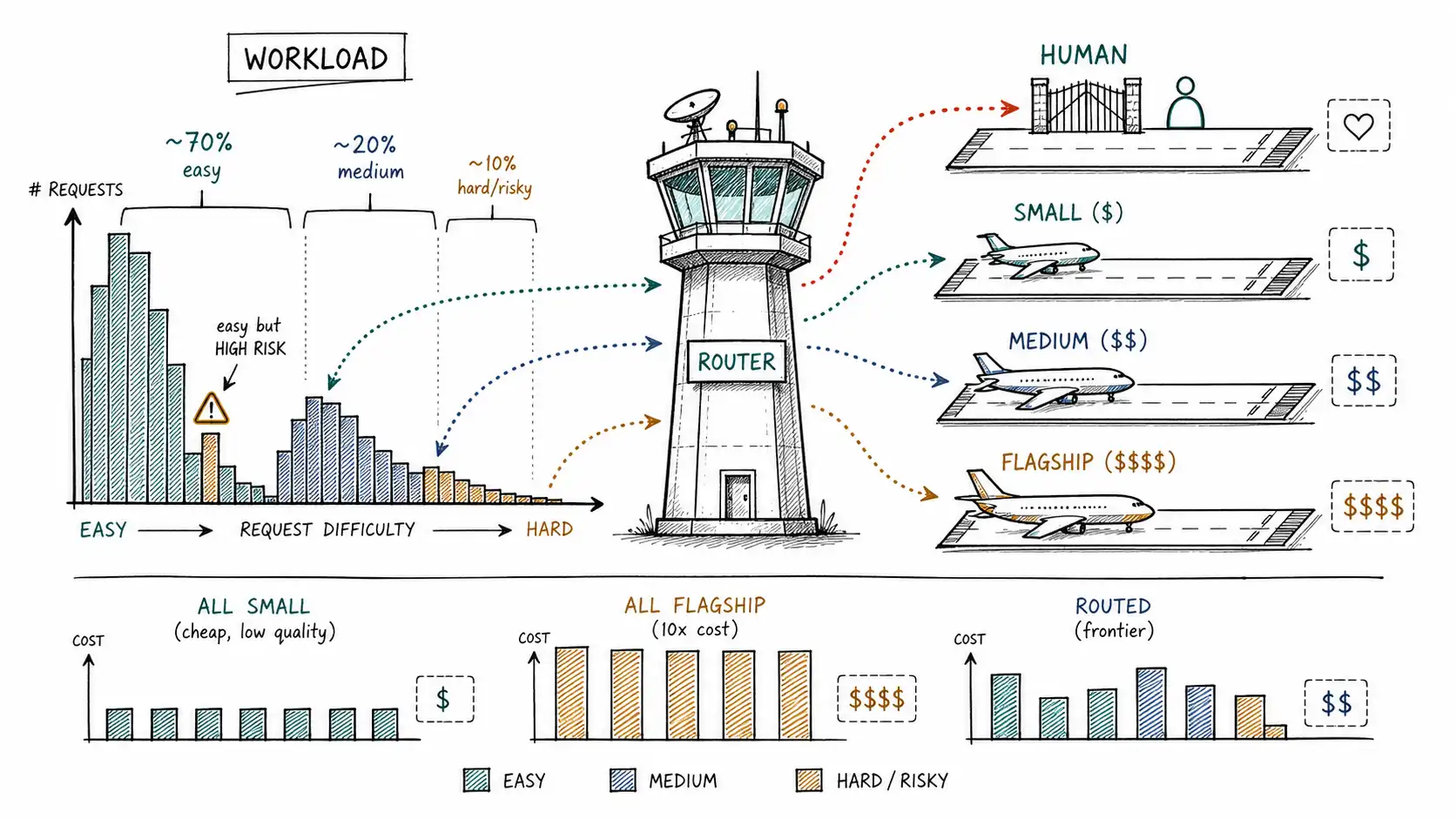
The workload is a distribution
The central object in this book is not a model. It is a distribution, the shape of your traffic across two axes that the rest of the book will keep separating: how hard a request is (can a cheap model get it right?) and how risky it is (what does a wrong answer cost?). Most production workloads, once you measure them, look like the support desk from the introduction: a large easy-and-cheap mass, a medium band, and a small hard-or-dangerous tail. The exact percentages vary, but the shape, fat head, thin expensive tail, is remarkably common, because most real traffic is dominated by routine requests with a long tail of genuinely difficult ones.
The single most valuable thing a team can do before building any router is to measure this distribution on their own traffic, because every downstream decision depends on it. If ninety percent of your traffic is hard, routing buys you little and you should just pay for the strong model. If ninety-nine percent is easy, you barely need a router, just a good default and an escape hatch. Routing earns its complexity in the broad middle, where a large cheap-able majority coexists with a minority that will hurt you if you treat it like the majority.
Here is a request taxonomy worth labeling traffic against. It is deliberately two-dimensional, because a one-dimensional "difficulty" label is what gets teams into trouble, it makes them forget that an easy request can be high-risk.
| Slice | Difficulty (can cheap get it right?) | Risk (cost if wrong) | Share (illustrative) | Right lane |
|---|---|---|---|---|
| Routine FAQ, status lookups | Low | Low | 55% | Small, no escalation |
| Light reasoning, single-doc | Low-Med | Low | 18% | Small, verify-then-escalate |
| Multi-doc, conflicting sources | High | Medium | 12% | Cascade or medium+verify |
| Easy question, dangerous domain | Low | High | 6% | Strong or human (risk floor) |
| Genuinely hard reasoning | High | Medium-High | 7% | Strong |
| Ambiguous / out-of-scope | Med | Variable | 2% | Clarify or human |
The fourth row is the one that breaks naive routers."What's the maximum dose?" is a short, simple-looking question a small model will answer fluently. The fluency is the trap. Difficulty is low; risk is high; the request must not go cheap regardless of how easy the prompt looks. Chapter 5 builds risk as a separate gate read before difficulty for exactly this reason.
What "the cheapest model that can still answer correctly" actually means
The subtitle of this book is a constraint with two clauses, and both matter. Cheapest is the objective: among the models eligible for a request, prefer the one with the lowest expected total cost. That can still answer correctly is the constraint: eligibility is gated by quality and risk, not by price. A router that optimizes the first clause while ignoring the second is just the cheap-everywhere failure with extra steps. A router that ignores the first while obsessing over the second is the flagship-everywhere failure dressed up as caution.
The phrase also hides a subtlety that the evaluation movement will return to: correctly is not a single threshold. The bar for "correct enough" depends on the request's risk and its outcome metric (the R and O of ROUTE). A summarization that is 90% faithful might be fine; a financial calculation that is 90% correct is a defect. So "can still answer correctly" is really "clears the quality bar that this request type demands, " and that bar is set per slice, not globally. The router's job is to find the cheapest model whose expected quality on this slice clears that slice's bar, which is why it needs the historical, per-slice performance data that Chapter 7 is about.
Provider choice is not routing architecture
A confusion worth killing early: choosing which providers and models to have is procurement; deciding which one each request uses is routing. They are different activities on different timescales, and teams conflate them constantly.
Procurement is quarterly and deliberate: you evaluate models, negotiate pricing, check data-residency and compliance posture, and assemble a fleet of eligible models, say a small open-weights model you host, a fast mid-tier hosted model, a flagship, and a specialist code model. That is the set of planes on the tarmac. Routing is per-request and automatic: given this request's difficulty, risk, latency budget, and tenant, which of those planes flies it. You can have a beautifully chosen fleet and a terrible router (everything goes to the flagship anyway), or a thin fleet and a sharp router (two models, but the split is right). This book is overwhelmingly about the second activity. It assumes you will do the first competently and gives you the framework, the ROUTE questions, to do it with routing in mind.
Routing as a control plane, not a feature
The mental model that pays off is to treat the router as a control plane: a component logically separate from the model calls, with its own configuration, its own deployability, its own observability, and its own change-management. In a mature system the routing policy, which signals map to which models under which constraints, is a versioned artifact you can canary and roll back, not a thicket of if statements buried in request-handling code. The model calls are the data plane: the actual inference. Keeping them separate is what lets you change routing behavior without redeploying the application, evaluate a new policy in shadow before it touches live traffic, and answer the question every operator eventually asks at 2 a. m., why did this request go where it went?, by reading a decision log rather than re-deriving control flow from source.
Here is the shape of a routing decision log entry. Every routed request should emit one. It is the substrate for the evaluation movement (regret needs it), the operations movement (drift detection reads it), and the governance movement (the audit trail is it).
{
"request_id": "req_8f3a91",
"ts": "2025-06-12T14:03:11Z",
"tenant": "acme-eu",
"task_type": "support.billing_dispute",
"signals": {
"predicted_difficulty": 0.71,
"risk_tier": "medium",
"token_estimate": 2840,
"needs_retrieval": true,
"needs_tools": false,
"latency_budget_ms": 4000
},
"policy_version": "route-policy@2025-06-10",
"decision": {
"lane": "cascade",
"first_model": "small-v2",
"escalated": true,
"escalation_reason": "validator_low_confidence",
"final_model": "flagship-v4"
},
"outcome": {
"cost_usd": 0.019,
"latency_ms": 3120,
"quality_label": null
}
}Notice what is recorded: not just what was chosen, but the signals that drove the choice and the policy version that interpreted them. Without the signals you cannot replay the decision; without the policy version you cannot tell whether a behavior change was traffic drift or a config rollout. quality_label is null at write time and backfilled later by online evaluation (Chapter 14), the decision log is also the place labels eventually land.
The baseline comparison every team should run first
Before designing anything, run three systems against a labeled sample of your own traffic and put the results in one table. This single experiment will tell you whether routing is worth building and roughly how much it can save.
# Compare three architectures on the same labeled request sample.
# Each "system" is a function: request -> (answer, model_used, cost_usd, latency_ms)
# `judge` returns True if the answer clears that slice's quality bar.
def evaluate_system(system, samples, judge):
n = len(samples)
correct = total_cost = total_latency = 0
for s in samples:
answer, model, cost, latency = system(s.request)
total_cost += cost
total_latency += latency
if judge(s, answer):
correct += 1
return {
"quality": correct / n,
"cost_per_req": total_cost / n,
"p50_latency_ms": total_latency / n, # use a real percentile in production
}
baselines = {
"all_small": evaluate_system(all_small_system, samples, judge),
"all_flagship": evaluate_system(all_flagship_system, samples, judge),
"routed_v0": evaluate_system(naive_router_system, samples, judge),}A representative result table from this kind of experiment, the pattern the support desk saw, looks like this:
| System | Quality | Cost / req | Relative cost | Notes |
|---|---|---|---|---|
| All small | 80% | $0.002 | 1.0× | Cheap, fails the hard tail |
| All flagship | 95% | $0.020 | 10.0× | Correct, pays the easy-tax |
| Routed (even a naive v0) | 93% | $0.005 | 2.5× | Near-flagship quality at quarter the cost |
The routed system does not match the flagship on quality, it gives up a couple of points on the hardest slice where even the router occasionally sends a hard request to the cheap lane, and it does not match the small system on cost. It lands on the frontier between them, which is the whole point and the subject of the next chapter. RouteLLM reports the same shape from the research side: a trained router can cut cost "by over 2 times in certain cases, without compromising the quality of responses." FrugalGPT pushes the claim further, reporting that an LLM cascade can match the performance of the best individual model "with up to 98% cost reduction" on some benchmarks. Treat those headline numbers as ceilings achieved on favorable benchmarks, not promises for your workload, but the direction is robust across the literature and across production reports: a workload that is a distribution responds well to a system that treats it like one.
Chapter summary
The one-model religion comes in two denominations, flagship-everywhere and cheap-everywhere, and both fail because they bet a heterogeneous workload is uniform. Flagship-everywhere is correct and pays a ten-times tax on the easy majority that never needed it; cheap-everywhere captures the savings and eats the wrong-answer cost on the hard-or-risky minority. The average quality number hides both facts, because it folds a 99%-correct easy mass together with a 45%-correct hard tail. The central object is therefore not a model but a distribution of requests across two axes, difficulty and risk, and the first thing any team should do is measure that distribution on its own traffic, because routing earns its complexity only in the broad middle where a cheap-able majority coexists with a dangerous minority."The cheapest model that can still answer correctly" means: among models made eligible by risk and quality, prefer the cheapest whose expected quality on this slice clears the slice's bar. Provider choice (procurement, quarterly) is not routing architecture (per-request, automatic); a good fleet with a bad router still sends everything to the flagship. Treat the router as a control plane, versioned policy, decision log, observability, separate from the data plane of model calls, and run the three-way baseline (all-small, all-flagship, routed) on labeled traffic before building anything, because that one table tells you whether the frontier is worth chasing.
Internal map
For the larger argument, keep this chapter connected to Model Routing, The Economics of Inference, the smaller-model margin argument, and A Field Guide to Evals.