Ten Playbooks
> **Working claim:** Everything in this book converges on a single recurring decision shape, and the fastest way to internalize it is to apply it ten times to ten different systems.

Research spine
This chapter is grounded in FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance, RouteLLM: Learning to Route LLMs with Preference Data, and OpenAI API pricing.
Key Takeaways
- Ten Playbooks is a chapter about model routing and inference control planes, not a generic AI adoption note.
- The operating rule is to send each request to the cheapest path that still meets quality, latency, residency, and risk requirements.
- The failure mode to watch is polished output without evidence, owner, cost line, or rollback path.
- The useful next step is an artifact a future teammate can replay without folklore.
Model routing works when each request goes to the cheapest path that still meets quality, latency, residency, and risk requirements.
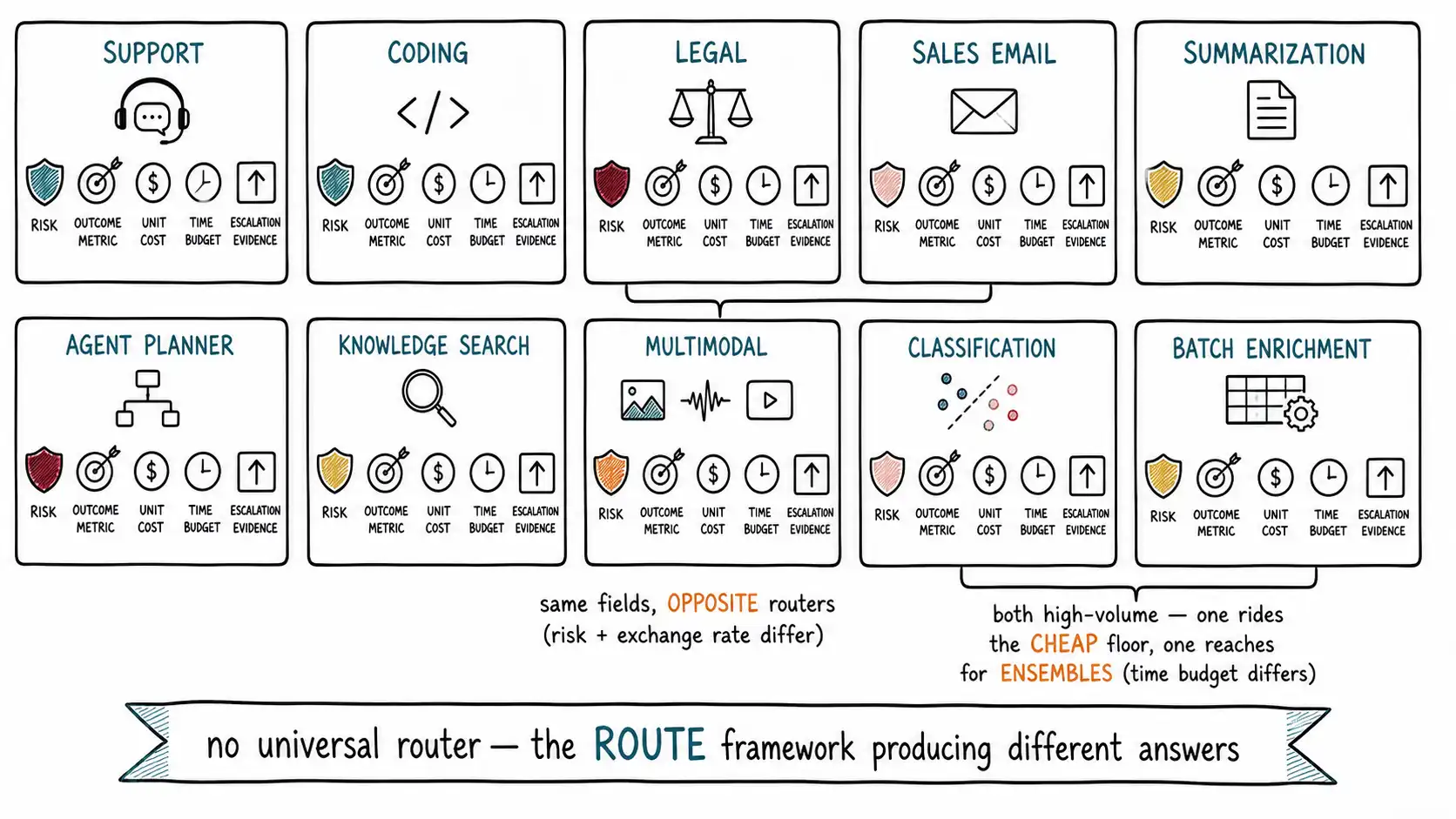
Working claim: Everything in this book converges on a single recurring decision shape, and the fastest way to internalize it is to apply it ten times to ten different systems. Each playbook below states the same fields, routing signals, candidate models, the cheap path, the escalation path, the evals, the cost and latency targets, and the failure risks, because that field set is the ROUTE framework made operational. The point is not to copy a playbook; it is to see the shape repeat and learn to fill it in for the system you actually have.
How to read a playbook
Each playbook is the ROUTE framework instantiated. Risk sets the floor and the eligible set;Outcome metric is the eval;Unit cost is the cost target and the cheap/escalation paths;Time budget is the latency target;Escalation evidence is the verifier or signal that justifies climbing. The fields are deliberately identical across all ten so you can compare systems and see how the same framework produces different routers when the risk, the outcome metric, and the latency budget differ. The targets are illustrative, your numbers come from your traffic (Chapter 1) and your frontier (Chapter 2).
1. Customer support assistant
- Routing signals: intent (FAQ / status / billing / dispute), tenant tier, whether a side-effecting action is requested, conversation length.
- Risk: mostly low (FAQ, status), spiking to high on billing disputes and account actions. Risk floor: actions require human approval (Chapter 17).
- Candidate models: small for FAQ/status; mid + verifier for billing; flagship or human for disputes and actions.
- Cheap path: small model answers FAQ/status directly, no escalation.
- Escalation path: cascade on billing (small → verify consistency → flagship); disputes route straight to flagship; account-changing actions route to a human.
- Evals: resolution rate and escalation-to-human rate by intent; false-cheap rate on billing (the slice that hurts).
- Cost target: the FAQ majority near the cheap floor; blended cost a fraction of flagship-everywhere.
- Latency target: interactive, sub-2s TTFT; FAQ must not cascade.
- Failure risks: false-cheap on a billing dispute (wrong money answer); routing an action to a model instead of a human; cross-tenant data leak via mis-scoped retrieval.
2. Coding assistant
- Routing signals: task (completion / generation / refactor / debug), whether tests exist, code size, language.
- Risk: medium, wrong code is caught by tests if tests exist, high if it touches security or infra.
- Candidate models: small/specialist for completion; code-specialist (Chapter 2's specialist lane) for generation; flagship for hard debugging.
- Cheap path: specialist model generates; run the tests as the verifier (Chapter 9, the strongest possible signal, deterministic).
- Escalation path: tests fail → escalate to flagship → run tests again; tests still fail → return with a flag, never silently ship failing code.
- Evals: test pass-rate at each rung; compile rate; for refactors, behavior-preservation checks.
- Cost target: completion at the cheap floor (huge volume); generation amortized by the test-gated cascade stopping early.
- Latency target: completion needs very fast TTFT (inline); generation tolerates seconds.
- Failure risks: shipping code that passes tests but is insecure (tests are not a security review); a runaway cascade on a genuinely impossible task; false-cheap on security-relevant code.
3. Legal / policy assistant
- Routing signals: domain (contract / regulation / advice), whether the answer is shown to a client vs. an internal lawyer, jurisdiction.
- Risk: high throughout: this is a high-risk domain, so the risk floor (Chapter 5) pushes most requests to strong models regardless of difficulty.
- Candidate models: flagship for interpretation; ensemble (Chapter 11) for high-stakes clause analysis; human for anything client-facing and binding.
- Cheap path: narrow, only routine retrieval/summarization of known documents goes to a mid model, and only with strict citation verification.
- Escalation path: citation/grounding verifier (every claim tied to a source clause) → flagship → human review for binding outputs.
- Evals: citation accuracy (no unsupported claims); faithfulness; expert agreement on a sampled set.
- Cost target: secondary to quality, the exchange rate (Chapter 13) heavily favors quality; this is not a cost-optimization domain.
- Latency target: generous; correctness dominates.
- Failure risks: false-cheap on a clause interpretation (the trap quadrant, Chapter 5); a fluent unsupported citation; routing a binding answer past human review.
4. Sales email assistant
- Routing signals: template vs. freeform, personalization depth, send volume.
- Risk: low, a mediocre sales email is a soft cost, not a harm. This is the opposite of the legal assistant on the risk axis.
- Candidate models: small for templated/bulk; mid for personalized; rarely flagship.
- Cheap path: small model for the bulk majority; no cascade (low risk tolerates some misses).
- Escalation path: mid model for high-value accounts (a business escalation signal, not a difficulty one: escalate by deal size).
- Evals: reply-rate / human-edit-rate as the outcome metric (Chapter 13's O); A/B by model on conversion.
- Cost target: aggressive, high volume, low risk, the ideal cheap-routing case.
- Latency target: mostly batch-eligible (Chapter 15's cheap tier); drafts are not real-time.
- Failure risks: over-spending by escalating low-value sends; brand/tone errors at scale; an abuse vector if "high-value account" can be spoofed to force the expensive lane.
5. Document summarization
- Routing signals: document length, type (transcript / contract / report), required fidelity (gist vs. exhaustive).
- Risk: low for gists, high for compliance/legal summaries (risk follows the use, not the task name).
- Candidate models: small for long-but-easy gists (Chapter 4, length is not difficulty); mid+verifier for high-fidelity; flagship for dense reasoning over the document.
- Cheap path: small model summarizes; cheap because summarization is often a long-input/short-output (input-dominated, Chapter 15) task where model choice matters less for cost.
- Escalation path: faithfulness verifier (does the summary assert anything not in the source?) → escalate on unsupported claims.
- Evals: faithfulness (no hallucinated facts), coverage of key points, compression ratio.
- Cost target: caching the document prefix is the big lever (Chapter 15/16); cache-aware routing keeps the cheap model warm.
- Latency target: moderate; long inputs cost input-latency even with short outputs (Chapter 16).
- Failure risks: confidently hallucinated facts in a summary read as authoritative; false-cheap on a compliance summary; cache thrash if routing flips models per document.
6. Agent tool planner
- Routing signals: plan complexity (number of steps), whether steps have side effects, tool risk.
- Risk: high and action-shaped: a planner that triggers tools is the side-effecting-action case (Chapter 5/17), gated by capability manifests.
- Candidate models: mid for read-only planning; flagship for multi-step plans; every side-effecting step gated by
requires_human_approval_for(Chapter 17). - Cheap path: routine single-tool, read-only steps on a mid model.
- Escalation path: plan-validation verifier (does the plan reference real tools, respect preconditions?) → flagship; any write/payment/send action → human approval, never auto-executed.
- Evals: plan validity, step success rate, and a safety eval that no plan executes a forbidden action without approval.
- Cost target: secondary, agent steps are lower-volume and higher-consequence than chat.
- Latency target: tolerant for planning; the bottleneck is usually tool execution, not the model.
- Failure risks: the biggest blast radius in the book, an action-capable model taking an irreversible action on a wrong plan; prompt injection in a tool result manipulating the next routing/planning step (OWASP, Chapter 17).
7. Enterprise knowledge search
- Routing signals: query type (lookup / synthesis / multi-doc reasoning), permission scope, freshness need.
- Risk: medium, wrong answers mislead employees; permission leaks are high-risk.
- Candidate models: small for direct lookups over retrieved passages; mid/flagship for multi-doc synthesis.
- Cheap path: retrieval + small model for "find and quote" queries (the cheap, high-volume majority).
- Escalation path: grounding verifier (answer supported by retrieved docs?) → escalate for synthesis; conflicting sources → flagship with explicit conflict handling.
- Evals: answer grounding, permission-correctness (never surface a doc the user can't see, a hard rule, Chapter 8/17), retrieval recall.
- Cost target: retrieval cost (embed + search) is part of the waterfall (Chapter 15); cache stable corpora.
- Latency target: interactive; retrieval adds to the budget (Chapter 16).
- Failure risks: surfacing a permissioned document via routing/retrieval (a governance breach, not a quality bug); false-cheap on a multi-doc synthesis that needed reasoning the small model faked.
8. Multimodal document assistant
- Routing signals: modality mix (text / image / table / scanned), extraction vs. reasoning, image count.
- Risk: varies by use; high for documents driving financial or legal decisions.
- Candidate models: specialist OCR/vision models for extraction (a capability eligibility gate, Chapter 17, only vision-capable models are eligible); flagship multimodal for reasoning over extracted content.
- Cheap path: specialist extractor → small text model reasons over the structured extraction (split the task: cheap extraction feeds cheap reasoning).
- Escalation path: extraction-confidence verifier (low OCR confidence, ambiguous tables) → flagship multimodal; reasoning verifier → escalate the reasoning step.
- Evals: extraction accuracy (field-level), downstream reasoning correctness on extracted data.
- Cost target: vision tokens are expensive; route to text-only models once content is extracted to avoid re-paying for image processing.
- Latency target: moderate; extraction is often batch-eligible, reasoning interactive.
- Failure risks: a silent extraction error poisoning correct downstream reasoning (garbage in, confident garbage out); routing a scanned doc to a non-vision model (capability mismatch).
9. High-volume classification
- Routing signals: confidence of a cheap classifier, class rarity, downstream action triggered by the class.
- Risk: depends entirely on the action the class triggers, labeling a ticket is low-risk; flagging fraud is high-risk.
- Candidate models: tiny/fine-tuned classifier for the bulk; mid/flagship only for the uncertain and high-consequence cases.
- Cheap path: the cheap classifier handles the confident majority, this is the highest-volume, most cost-sensitive playbook, the strongest case for aggressive cheap routing (FrugalGPT's home turf).
- Escalation path: low classifier confidence (calibrated, Chapter 6) or a high-consequence class → escalate to a stronger model or human review.
- Evals: per-class precision/recall; the four-box matrix (Chapter 12) is exactly the right instrument here; calibration of the cheap classifier's confidence.
- Cost target: the most aggressive in the book, millions of items, the cheap floor dominates the blend.
- Latency target: usually batch (Chapter 15's cheap tier); the patient case.
- Failure risks: false-cheap on the high-consequence class (fraud waved through); over-escalation eating the volume savings; an adversary crafting inputs to trigger the expensive review path (denial-of-wallet, Chapter 17).
10. Offline batch enrichment
- Routing signals: item value, downstream reuse count, whether the output is cached and read many times.
- Risk: the output's risk equals the risk of everything that reads it later, a poisoned enrichment propagates.
- Candidate models: here, the calculus inverts, because latency is irrelevant and outputs are cached and reused, an ensemble (Chapter 11) is often the right default, not the exception. Compute the best possible answer once; amortize across every read.
- Cheap path: even here, the trivial items can use a cheap model, not everything needs the ensemble.
- Escalation path: value-based, high-reuse, high-value items get the ensemble; verifier-gated escalation for the rest.
- Evals: output quality at the slice's bar; and a contamination/poisoning check, since a wrong cached enrichment is read repeatedly (the asymmetry of a write error, echoing the wider series).
- Cost target: per-item cost matters divided by reuse count, a $0.10 ensemble answer read 10, 000 times is $0.00001 per read.
- Latency target: none (batch); the whole point is latency-insensitivity unlocks the cheap batch tier and justifies expensive ensembles.
- Failure risks: a systematic error baked into a cached dataset and propagated to everything that reads it; paying ensemble cost on low-reuse items that didn't earn it.
The shape that repeats
Read across the ten and the lesson is in the variation, not any single row. The legal assistant and the sales assistant fill in the same fields and produce opposite routers, because legal is high-risk-quality-dominated and sales is low-risk-cost-dominated, the R and the exchange rate (Chapter 13) differ, and everything else follows. The high-volume classifier and the offline enrichment both have huge volume, but one optimizes the cheap floor (latency-bound, FrugalGPT-shaped) and the other reaches for ensembles (latency-free, LLM-Blender-shaped), because the T (time budget) differs and unlocks opposite patterns. The coding assistant and the agent planner both have verifiers, but one runs tests (deterministic, safe to trust) and the other gates human approval on side effects (because the blast radius differs). The OpenAI evals guide discipline, measure the outcome metric that matters for this task, is what turns the shared field set into ten different correct answers.
That is the whole book in one observation: there is no universal router, only the same framework producing different routers when risk, outcome metric, cost, latency, and escalation evidence differ. Fill in the fields for your system, measure your distribution, ride your frontier, judge the decisions not the models, watch the slices, lock the doors, and operate the fleet. The question stops being "which model should we use?" and becomes "which model should this request use, and how will we know if the router was wrong?" (see Appendix A: Back Matter for the implementation checklist and glossary that make that answer operational).
Chapter summary
Ten playbooks instantiate the same field set, routing signals, candidate models, cheap path, escalation path, evals, cost target, latency target, failure risks, because that set is the ROUTE framework made operational, and the lesson is in how the same fields produce different routers. Support is mostly cheap with a billing-dispute escalation and human-gated actions; coding cascades on the strongest verifier there is (run the tests); legal is high-risk-throughout with a narrow cheap path and human review for binding outputs; sales email is the low-risk cost-aggressive opposite of legal, escalating by deal size not difficulty; summarization is input-dominated and cache-led with a faithfulness verifier; the agent planner has the biggest blast radius (side-effecting actions human-gated, injection in tool results a real threat); knowledge search makes permission-correctness a hard rule; multimodal splits expensive extraction from cheap downstream reasoning; high-volume classification is FrugalGPT's home turf (cheap floor, calibrated-confidence escalation, the four-box matrix as the native instrument); and offline batch enrichment inverts the calculus, latency-free and cached-for-reuse, it makes ensembles the default and divides cost by reuse count. Reading across them, the legal/sales pair shows the same fields yielding opposite routers because risk and the exchange rate differ, and the classification/enrichment pair shows two high-volume systems reaching for opposite patterns because the time budget differs and unlocks the cheap floor versus the ensemble. There is no universal router, only the ROUTE framework producing different correct answers when risk, outcome metric, cost, latency, and escalation evidence change, which is the whole book: stop asking "which model should we use?" and ask "which model should this request use, and how will we know if the router was wrong?"
Internal map
For the larger argument, keep this chapter connected to Model Routing, The Economics of Inference, the smaller-model margin argument, and A Field Guide to Evals.