Introduction: The Tower
A company I will call the desk, the details are composited from several real support organizations, but the shape is exact, built a customer-support assistant in the first flush of capable chat models. The engineering was clean.

Research spine
This chapter is grounded in FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance, RouteLLM: Learning to Route LLMs with Preference Data, and OpenAI API pricing.
Key Takeaways
- Introduction: The Tower is a chapter about model routing and inference control planes, not a generic AI adoption note.
- The operating rule is to send each request to the cheapest path that still meets quality, latency, residency, and risk requirements.
- The failure mode to watch is polished output without evidence, owner, cost line, or rollback path.
- The useful next step is an artifact a future teammate can replay without folklore.
Model routing works when each request goes to the cheapest path that still meets quality, latency, residency, and risk requirements.
A company I will call the desk, the details are composited from several real support organizations, but the shape is exact, built a customer-support assistant in the first flush of capable chat models. The engineering was clean. A request came in, the application assembled a prompt with the customer's recent tickets and the relevant help-center articles, and sent it to the strongest model the company could buy. The answers were excellent. Reviewers gave them high marks. The pilot expanded. The assistant started handling tens of thousands of conversations a day, and for a while everyone was happy.
Then finance ran the numbers for the quarter, and the room went quiet. The assistant was good, and good was bankrupting them. The unit economics that worked at a thousand conversations a day did not work at fifty thousand. Each conversation made several model calls, one to understand the request, one or two to draft, one to check tone, and each call went to the flagship at the flagship's price. Gross margin on the support product, once comfortable, had gone negative. The model that made the demo sing was a line item that grew linearly with success, and success was the problem.
So the team did the obvious thing, which was the wrong thing. They swapped the flagship for the cheapest capable model across the board. The bill fell by an order of magnitude overnight, and for about a week it looked like a clean win. Then the second-order effects arrived. Escalations to human agents climbed. The cheap model was fine on the routine questions, password resets, shipping status, "where is my refund", but it produced confident, wrong answers on the harder slice: billing disputes with unusual histories, questions that required reading three policy documents and noticing they disagreed, edge cases where the safe answer was "I don't know, let me get a human." Customer satisfaction dropped. A few of the wrong answers became complaints, and one became a small legal matter. The savings on the model bill were real, and they were dwarfed by the cost of the wrongness.
The team had run the same experiment twice, with opposite knobs, and gotten two failures. The flagship-everything system was correct and unaffordable. The cheap-everything system was affordable and unreliable. The instinct after two failures is to split the difference, pick a "medium" model and hope, but a medium model everywhere is just a third way to be wrong about a workload that was never uniform to begin with.
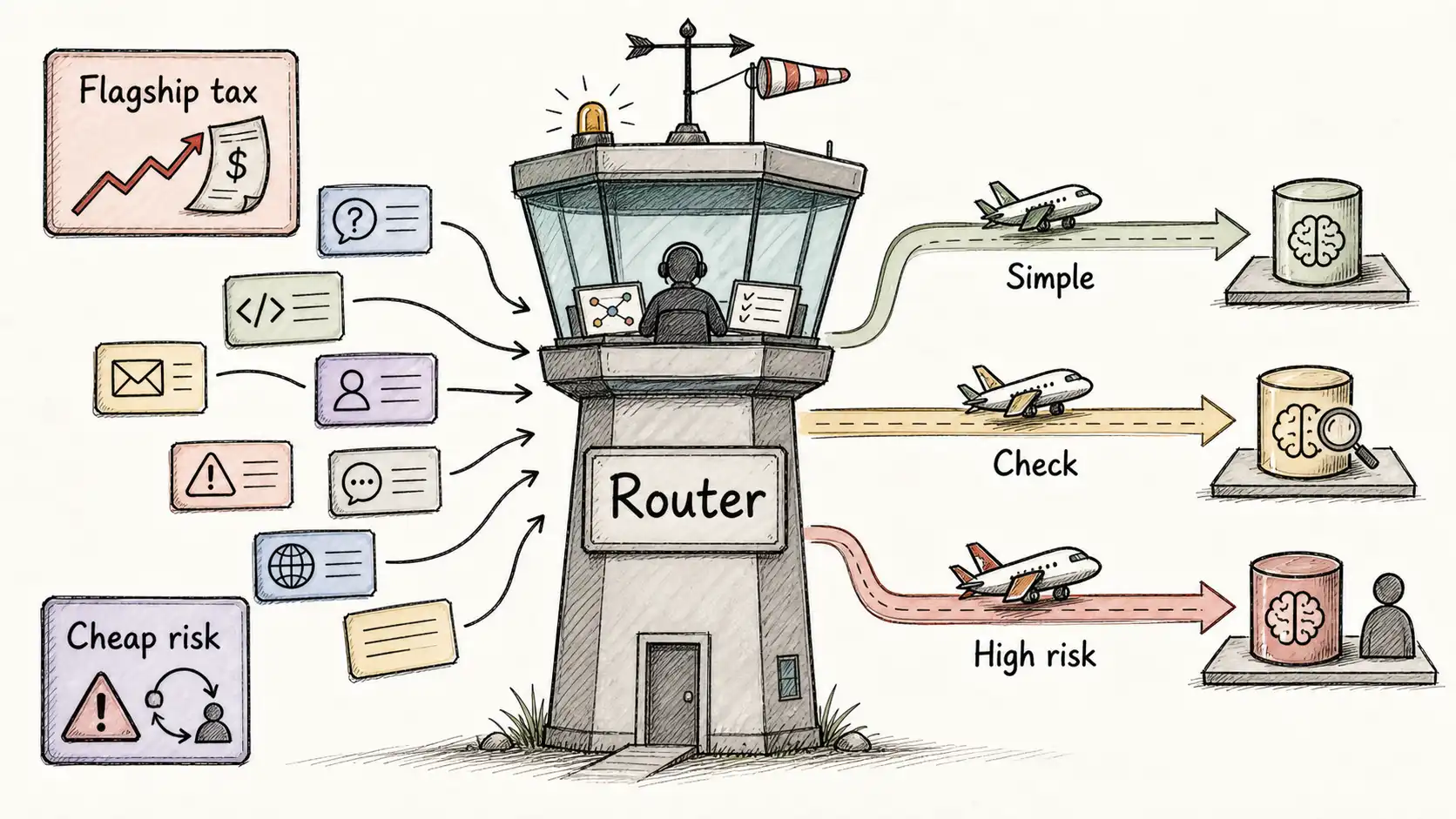
What finally worked started with a measurement nobody had bothered to take. They sampled a week of traffic and had analysts label each conversation by how hard it actually was and how much a wrong answer would cost. The distribution was lopsided in a way that, once seen, could not be unseen. Roughly seventy percent of requests were simple, a small model answered them correctly every time, and using the flagship on them was pure waste. About twenty percent were medium, a small model was right most of the time but wrong often enough to matter, and a medium model or a verify-then-escalate path handled them well. The remaining ten percent were hard or high-risk, genuinely complex reasoning, or low complexity but high blast radius if wrong, and those were the ones that justified the flagship, a human, or both.
The correct architecture was not "cheap model" or "best model." It was a router: a component that looked at each request, estimated how hard and how risky it was, and sent it to the cheapest model that could still answer it correctly, escalating only when the evidence said it should. The seventy percent went cheap and stayed cheap. The twenty percent went to a path that tried cheap, checked the result, and escalated on doubt. The ten percent went straight to the strong lane, and the riskiest of those went to a human. The bill came down by most of what the cheap-everything experiment had saved, and the quality came back up to near where the flagship-everything system had been. The tradeoff had not been abolished. It had been placed under control, request by request.
That control plane, the thing that decides which model flies each request, when to escalate, when to fall back, and how to keep the system safe and affordable under load, is the subject of this book.
Why the one-model reflex is so strong
The reflex is not stupidity. It is the rational response to a real cost: every model you add to a system is a thing you must integrate, evaluate, monitor, secure, and reason about when it breaks. One model is simple. One model has one set of credentials, one latency profile, one failure mode, one bill. The pull toward "just pick one and send everything to it" is the same pull that makes engineers prefer a monolith to a fleet of microservices until the monolith's costs force the issue. Heterogeneity is expensive to operate, so teams avoid it until a bill or an incident makes homogeneity more expensive still.
The trouble is that the workload was never homogeneous. The averages lie about it. A team looking at "average quality: 94%, average cost per request: 1.1 cents" sees a system that is fine, because the average folds a cheap-and-easy majority together with an expensive-and-hard minority and reports a number that describes neither. The seventy percent that a small model nails for a tenth of a cent and the ten percent that a small model fluffs at real cost both vanish into the mean. Routing is, in large part, the discipline of refusing to be fooled by averages, of looking at the workload as a distribution of difficulty and risk, and architecting for the slices rather than the center of mass. A great deal of this book is teaching you to see the slices.
What this book argues
The argument runs in movements, and they build.
One model is a product decision, not a law, comes first. We replace the question "which model is best?" with the picture of a cost-quality frontier, many models scattered across a plane of price and capability, with a router tracing a path along the efficient edge rather than camping at one corner. We separate five words that get used as synonyms and are not: static routing, dynamic routing, cascade, fallback, and ensemble. They are different architectures with different failure modes, and conflating them produces systems that are neither.
What makes a request hard is the core of the early book, because a router is only as good as the signals it reads. We dismantle the single most common heuristic, prompt length, and show how it misclassifies difficulty in both directions. We treat risk as a separate axis from difficulty, read before it, because a short easy question with a catastrophic wrong-answer cost should not go cheap no matter how easy it looks. We look hard at confidence and model self-assessment, both of which are seductive and unreliable, and at the signals that actually carry information: task type, domain sensitivity, retrieval and tool needs, ambiguity, historical performance by slice, and learned routers trained on what cheap and expensive models actually did.
Routing patterns is the catalog. Static rules, intent and tier routing, the cascade ladder where a request climbs only when the rung below it fails a check, provider failover and local-versus-cloud meshes, and the ensemble family, voting, reranking, and generative fusion, where you pay more than one model on purpose to buy quality you cannot get from any single one. Each pattern comes with its diagram, its config, and the conditions under which it is the right tool and the conditions under which it is a trap.
Evaluation is where the book gets uncomfortable, because a router can make every individual model look fine while the system fails. The unit of evaluation is the routing decision, not the model output. We build the four-box confusion matrix, cheap-and-right, cheap-and-wrong, escalated-and-needed, escalated-and-wasted, and the concept of regret: what the router lost by the choice it made versus the choice an oracle would have made. We build cost-weighted quality, escalation precision and recall, shadow routing to collect labels cheaply, and online evaluation that survives provider drift and model upgrades.
Cost and latency engineering makes the economics concrete: the cost waterfall from input tokens through retries and second-model escalations, the asymmetry between input and output pricing, prompt caching and batch APIs, the latency budget and where it gets spent, and cost attribution by tenant, product, and workflow so that "the bill is too high" becomes "the bill is too high here, because of this."
Safety, security, and governance treats the router as a thing that can do harm: send a regulated document to a forbidden provider, route a high-risk question to a weak model, bypass a guardrail, or be manipulated by an adversary into forcing every request down the most expensive lane to exhaust a budget. We build capability manifests, residency and tenant restrictions, audit trails, and defenses against the abuse patterns unique to routed systems.
Operating the router closes the technical core: observability for route distribution, the drift that creeps in when traffic or models change, canarying a new routing policy, the runbooks for a provider outage and a cost spike and a quality regression on a single route, and the lifecycle of adding, shadow-testing, promoting, and retiring a model from the fleet without an incident.
Playbooks ends the book with ten concrete systems, support, coding, legal, sales email, summarization, agent planning, knowledge search, multimodal documents, high-volume classification, and offline batch, each stated as routing signals, candidate models, cheap path, escalation path, evals, cost target, latency target, and the failure risks specific to that domain.
How to read this book
It is written to be read in order, because the movements build, but it is also written so an engineer in the middle of a specific fire can open to the relevant chapter and find a usable artifact: a YAML policy, a router function, a confusion matrix, a SQL query, a runbook. The code is deliberately about routing infrastructure, difficulty and confidence estimation, cascade and fallback control flow, cost and latency models, per-task model-selection policy, shadow and canary routing, decision and failure matrices, and a monitoring schema for per-route cost, latency, quality, and fallback rate. There are no bare single-model API calls in this book that exist only to show you how to call a model. Every code example shows selection, escalation, fallback, or evaluation, because those are the things a router is made of.
Throughout, the tone is operational and skeptical of slogans."Small models are good enough now" is a slogan; the truth is that small models are good enough for most requests and dangerous for some, and the whole job is telling which is which."Always use the best model" is a slogan; the truth is that the best model on the easy majority is a tax you pay for not having built a router. The skepticism is aimed at the religion, not at the models.
A demo only needs a good answer once, on a request the demonstrator chose. A product needs a defensible answer repeatedly, across a distribution of difficulty and risk it did not choose, under budget pressure, latency limits, provider outages, model deprecations, and the occasional adversary. The desk's flagship system gave a good answer once, in the demo, and an unaffordable one at scale. Its cheap system gave an affordable answer and a dangerous one. The rest of this book is about the third thing, the tower that decides, for each request, which plane should fly.
Turn the page. The runway is busy, the weather is changing, and somewhere in the inbound stream is a request that will look easy and cost you everything if you send it to the wrong lane.
Internal map
For the larger argument, keep this chapter connected to Model Routing, The Economics of Inference, the smaller-model margin argument, and A Field Guide to Evals.