The Latency Budget
> **Working claim:** Latency is the currency a cost-obsessed router forgets, and it is the one users feel.

Key Takeaways
- The Latency Budget is a chapter about model routing and inference control planes, not a generic AI adoption note.
- The operating rule is to send each request to the cheapest path that still meets quality, latency, residency, and risk requirements.
- The failure mode to watch is polished output without evidence, owner, cost line, or rollback path.
- The useful next step is an artifact a future teammate can replay without folklore.
Model routing works when each request goes to the cheapest path that still meets quality, latency, residency, and risk requirements.
Working claim: Latency is the currency a cost-obsessed router forgets, and it is the one users feel. A cascade buys cheapness with seconds; a fallback buys availability with a timeout's worth of waiting; an ensemble buys quality with either latency or cost. Every routing pattern spends latency somewhere, and on interactive paths latency is a hard ceiling, not a soft preference, a perfect answer that arrives after the user has given up is worth zero.
Where the latency goes
A routed request's latency is, like its cost, a sum of components, and the routing decisions add or remove time at each step:
- Routing overhead: intent classification (a model call), risk assessment, difficulty estimation, slice lookup. Usually small, but a model-based router adds a model call before the model call.
- Retrieval: embedding the query and searching the vector store, if RAG-shaped.
- The model call(s): the dominant term, and the term that grows with output length, because generation is sequential: a model producing 2,000 tokens takes roughly twice as long as one producing 1,000, regardless of how fast it starts.
- Verification: the verifier call (Chapter 9), in series before the answer is accepted.
- Escalation, if the cascade climbs, another full model call plus another verification, in series, on top of everything already spent.
- Fallback, if a call times out before failing over, the request waits out the timeout before the substitute even starts.
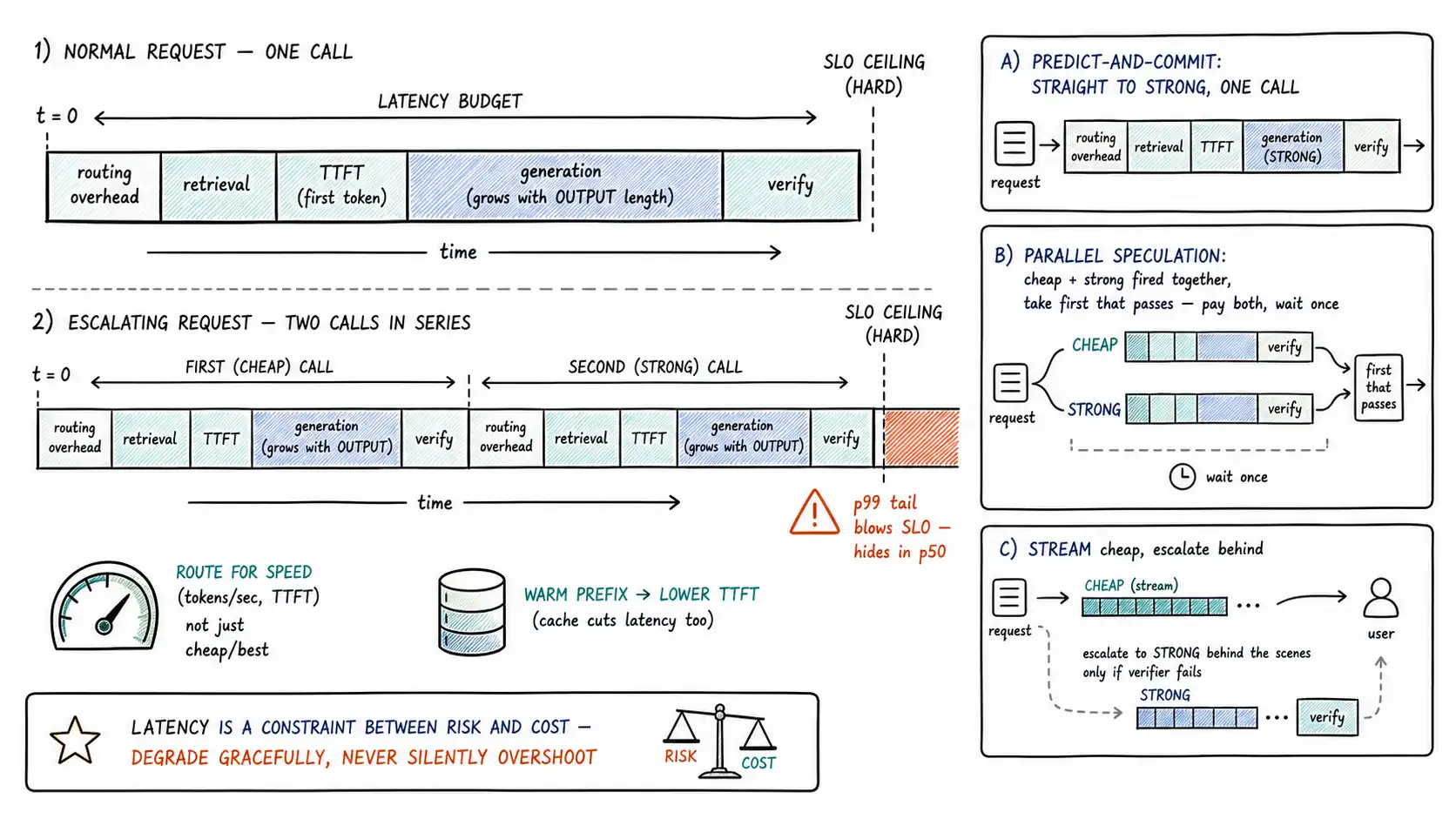
The two that surprise teams are escalation and fallback, because they are conditional, they only happen on some requests, so they hide in the p50 and erupt in the p99. A cascade that escalates 10% of the time has a p50 latency of one model call and a p99 of three (cheap + verifier + strong), and a latency SLO measured at p50 will look healthy while the escalating tail blows the SLO badly. Latency, even more than cost, must be watched at the tail (p95/p99), because the tail is where the conditional routing costs live.
Output length dominates, and routing should know it
The single most important latency fact for routing: model latency is driven primarily by output length, not input length, because output is generated token-by-token sequentially while input is processed in parallel. A request that reads 50, 000 tokens and writes 50 is fast (long input, short output); a request that reads 50 tokens and writes 5,000 is slow (short input, long output). This is the mirror of the cost asymmetry from Chapter 15, and it has a routing consequence: for latency-tight requests, the dimension to control is expected output length, and a model that generates faster (higher tokens-per-second, often a smaller model) can beat a higher-quality slower model on a latency-bound request even if both produce the same answer. Routing for latency sometimes means choosing the faster model, not the cheaper or the better one: a third axis the model choice optimizes.
# Estimating routed latency BEFORE deciding, so latency-tight paths route for speed.
def estimate_latency(request, plan, model_speed):
ms = ROUTING_OVERHEAD_MS
if request.used_retrieval:
ms += RETRIEVAL_MS
for step in plan.calls: # cascade may plan multiple
n_out = expected_output_tokens(request)
ms += model_speed[step.model].ttft_ms # time to first token
ms += n_out / model_speed[step.model].tokens_per_sec * 1000 # generation
ms += step.verifier_ms if step.verify else 0
return ms
def route_under_latency_budget(request, fleet, budget_ms):
eligible = risk_eligible(fleet, assess_risk(request)) # risk floor still first
# Among eligible models, keep only those that FIT the latency budget...
fast_enough = [m for m in eligible
if estimate_latency(request, plan_single(m), SPEED) <= budget_ms]
if not fast_enough:
return degrade_gracefully(request, budget_ms) # stream partial / smaller answer
# ...then among those, pick the cheapest that clears the quality bar (the book's rule).
return cheapest_passing(fast_enough, request)The order of operations holds: risk gates eligibility, then latency filters to the models that fit the budget, and only then does the cheapest-that-works rule choose. Latency is a constraint layered between risk and cost, and a request whose budget no eligible model can meet must degrade gracefully (Chapter's resilience theme) rather than blow the budget, stream a partial answer, return a smaller answer, or tell the user it is working, never silently exceed the SLO.
The cascade's latency tax
Chapter 9 flagged it; here is the full accounting. A cascade is cheap because most requests stop at the bottom rung, but the requests that climb pay a steep latency tax: cheap call + verifier + strong call + verifier, all in series. On a slice with a 20% escalation rate, one in five requests experiences roughly triple the latency, and those requests are concentrated in the p90+ tail. For an interactive slice with a tight SLO (say, sub-2-second), a cascade may simply be infeasible, the escalating tail cannot fit the budget no matter how cheap it is.
Three ways to keep cascade economics without the latency tax on interactive paths:
- Predict-and-commit (Chapter 3): use a learned difficulty predictor to send the likely-hard requests straight to the strong model, skipping the doomed cheap attempt. This trades the cascade's strong signal (the actual answer) for one fast call. The slice data (Chapter 7) tells you when prediction is reliable enough to replace looking.
- Parallel speculation: fire the cheap and strong models simultaneously; if the verifier accepts the cheap answer when it returns, use it and cancel/ignore the strong one; otherwise use the strong one (which is already in flight). This pays for both models on escalating requests (cost) but does not wait for them in series (latency): a cost-for-latency trade that latency-tight, cost-tolerant slices should take.
- Stream the cheap answer, escalate behind it: begin streaming the cheap model's answer immediately for perceived latency, and escalate only if the verifier rejects it mid-stream. This improves perceived latency (the user sees tokens fast) at the cost of occasionally having to correct a streamed answer, acceptable for some UX, unacceptable where a wrong partial answer is harmful (high-risk slices, again).
The latency budget, in short, constrains which routing patterns a slice may use. Cost-tolerant low-latency slices favor parallel speculation; cost-sensitive latency-tolerant slices favor deep cascades; and the wrong pairing (a deep cascade on a tight interactive SLO) is a common, measurable mistake.
Streaming changes the metric that matters
For interactive requests, the metric users feel is not total latency but time to first token (TTFT), how long until something appears, followed by a steady stream. A streaming response with fast TTFT feels responsive even if total generation takes several seconds, because the user sees progress. This changes routing for interactive paths: a model with fast TTFT can deliver a better experience than a faster-total model with slow TTFT, and the router optimizing for perceived latency optimizes TTFT first. OpenAI's production best practices recommend streaming precisely for this perceived-latency benefit, and a router that serves interactive traffic should treat TTFT as a first-class routing signal, distinct from total latency. The danger is that streaming commits you to the streamed model, once tokens are out, escalating means contradicting what the user already saw, so streaming and cascading are in tension, and the resolution (stream the cheap answer but be ready to correct, or only stream after the verifier passes) is a UX-and-risk decision per slice.
Prompt caching cuts latency too
A point Chapter 15 made for cost applies equally to latency. Prompt caching reduces not only the cost of the cached prefix but its processing latency, a cached prefix does not need to be re-processed, so TTFT drops sharply for requests whose large prefix is warm. For a system with a big stable system prompt or document context, caching is a latency lever as much as a cost lever, and the same cache-aware routing logic applies: routing to a model whose prefix is warm is faster as well as cheaper, and routing to a cold model pays the prefix-processing latency the warm model would have skipped. Cache-aware routing optimizes two currencies at once.
Long context and latency
A connection to RULER and the long-context theme of the wider series. Long inputs cost latency to process even when output is short, and, more importantly, a model's effective capability degrades at length (RULER), so a long-context request routed to a model near its effective limit pays both the latency of the long input and a quality risk. For long-context slices, the routing decision must weigh that a long-context-capable model may be slower (more input to process) but a cheaper short-context model may be ineligible (Chapter 4's length-gates-eligibility) or unreliable at that length. Length, again, gates eligibility and informs latency, never difficulty, and on long-context slices the latency cost of the input is a real term the budget must include, not an afterthought dominated by output.
Chapter summary
Latency is the currency a cost-obsessed router forgets and the one users feel; every pattern spends it somewhere, a cascade buys cheapness with seconds, a fallback buys availability with a timeout's wait, an ensemble buys quality with latency or cost. Routed latency is a sum (routing overhead, retrieval, the model call, verification, conditional escalation, conditional fallback), and the conditional terms (escalation, fallback) hide in p50 and erupt in p99, so latency must be watched at the tail. The dominant term is output length, because generation is sequential while input is parallel, the mirror of Chapter 15's cost asymmetry, so latency-tight requests should sometimes route to the faster model (high tokens-per-second, fast TTFT), a third axis beside cheap and best. The order of operations puts latency as a constraint between risk (gates eligibility) and cost (cheapest-that-works): filter to models that fit the budget, then pick the cheapest passing one, and degrade gracefully (partial/smaller answer) when none fit rather than silently overshoot the SLO. The cascade's latency tax (climbing requests pay cheap+verify+strong+verify in series, concentrated in the tail) can make deep cascades infeasible on tight interactive SLOs; keep the economics without the tax via predict-and-commit, parallel speculation (pay both, wait once), or stream-and-correct, so the budget constrains which patterns a slice may use. For interactive paths the felt metric is time-to-first-token, which streaming optimizes but which commits you to the streamed model (in tension with cascading), and prompt caching cuts TTFT as well as cost, so cache-aware routing optimizes both currencies. Finally, long inputs cost latency and risk quality near a model's effective limit (RULER), so length gates eligibility and informs latency, never difficulty, and on long-context slices the input's latency is a real budget term, not an afterthought.
Internal map
For the larger argument, keep this chapter connected to Model Routing, The Economics of Inference, the smaller-model margin argument, and A Field Guide to Evals.