The Control Room and the Fleet
> **Working claim:** A routing policy is not shipped once; it is *operated*. Models join and leave the fleet, providers degrade, traffic drifts, and a config change can re-route a third of your traffic in one deploy.

Key Takeaways
- The Control Room and the Fleet is a chapter about model routing and inference control planes, not a generic AI adoption note.
- The operating rule is to send each request to the cheapest path that still meets quality, latency, residency, and risk requirements.
- The failure mode to watch is polished output without evidence, owner, cost line, or rollback path.
- The useful next step is an artifact a future teammate can replay without folklore.
Model routing works when each request goes to the cheapest path that still meets quality, latency, residency, and risk requirements.
Working claim: A routing policy is not shipped once; it is operated. Models join and leave the fleet, providers degrade, traffic drifts, and a config change can re-route a third of your traffic in one deploy. Operating a router means observability that watches per-route cost, latency, quality, and fallback rate; a disciplined lifecycle for adding and retiring models; canary rollouts for policy changes; and runbooks for the incidents you will have. The control room is where the air-traffic-control metaphor stops being a metaphor.
What the control room watches
A router's monitoring is not the same as a model's monitoring. A model's dashboard watches latency and error rate; a router's dashboard watches the distribution of decisions and their consequences, per route. The four signals every routed system must surface, broken out by route (lane, model, slice, tenant):
- Per-route cost: money by lane and slice, so a cost spike is localized (Chapter 15's attribution, live).
- Per-route latency: p50 and p95/p99 by lane, so the cascade's escalating tail (Chapter 16) is visible, not averaged away.
- Per-route quality: the four-box matrix and false-cheap rate by slice (Chapter 12), from shadow labels (Chapter 14), so quality regressions surface before complaints do.
- Per-route fallback rate, how often each lane fails over (Chapter 10), so a degrading provider is caught early by its rising fallback rate, before it becomes an outage.
-- The router control-room view: one row per route, the four signals side by side.
CREATE VIEW route_health AS
SELECT
decision_lane, chosen_model, slice_key, risk_tier,
count(*) AS requests,
sum(cost_usd) AS cost,
percentile_cont(0.50) WITHIN GROUP (ORDER BY latency_ms) AS p50_latency,
percentile_cont(0.95) WITHIN GROUP (ORDER BY latency_ms) AS p95_latency,
avg(CASE WHEN false_cheap THEN 1.0 ELSE 0.0 END) AS false_cheap_rate,
avg(CASE WHEN escalated THEN 1.0 ELSE 0.0 END) AS escalation_rate,
avg(CASE WHEN failed_over THEN 1.0 ELSE 0.0 END) AS fallback_rate,
avg(CASE WHEN cache_hit THEN 1.0 ELSE 0.0 END) AS cache_hit_rate
FROM routing_outcomes
WHERE ts > now() - interval '1 hour'
GROUP BY decision_lane, chosen_model, slice_key, risk_tier;
-- Alerts read this view: false_cheap_rate up on a high-risk slice, fallback_rate
-- up on a provider, p95_latency up on an interactive slice, cost up on a tenant.The recurring discipline: *per-route, per-slice, never just the average. * The whole book has argued that the average hides the slices that matter, and operations is where that argument becomes alerting. An alert on average quality misses a regression confined to one high-risk slice; an alert on average cost misses a tenant's runaway workflow. The control-room view groups by route and slice so the alerts fire on the localized problem, which is the only kind of problem that turns into an incident.
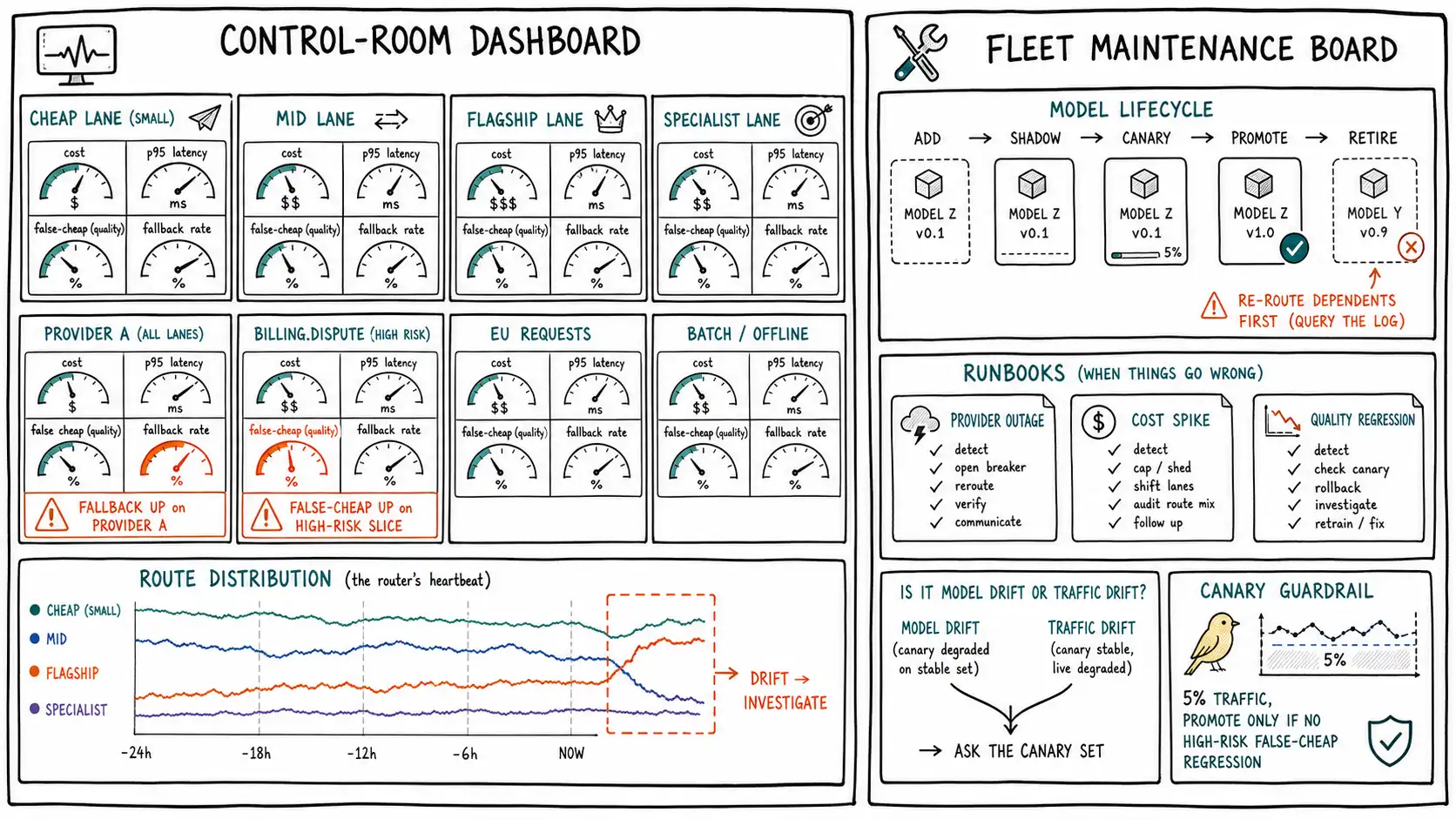
Route distribution drift
The most router-specific operational signal is route distribution drift: the fraction of traffic going to each lane over time. The route distribution is a fingerprint of the router's behavior, and when it shifts without a policy change, something in the world moved (Chapter 14's drifts). A sudden climb in the flagship's share might mean traffic got harder (traffic drift), the cheap model regressed and the cascade is escalating more (model drift), or an abuse campaign is forcing expensive routes (Chapter 17). A drop in the cheap lane's share is money leaking. Watching the route distribution as a time series, and alerting on sharp shifts, catches these before the cost or quality consequences fully land. The route distribution is the router's heartbeat, and a healthy router's heartbeat is stable unless you changed the policy or the world changed underneath it.
Canarying a policy change
A routing policy change is a deploy that can re-route large fractions of traffic instantly, which makes it as dangerous as a code deploy and deserving of the same care. The discipline is canary rollout: apply the new policy to a small slice of traffic, compare its four signals against the current policy on equivalent traffic, and promote only if it wins on the metrics that matter (cost-weighted quality, Chapter 13) without regressing the ones that bite (false-cheap on high-risk slices).
# canary-rollout.yaml - promote a new routing policy by evidence, not by faith.
canary:
candidate_policy: "route-policy@2025-06-20"
baseline_policy: "route-policy@2025-06-10"
traffic_split: 0.05 # 5% to candidate, stratified across slices
duration_hours: 24 # enough volume to measure rare slices
promote_if: # ALL must hold to auto-promote
- metric: cost_weighted_quality
direction: ">="
vs_baseline_margin: 0.0 # at least as good overall
- metric: false_cheap_rate_high_risk
direction: "<="
vs_baseline_margin: 0.0 # NEVER regress safety on high-risk slices
- metric: p95_latency_interactive
direction: "<="
vs_baseline_margin: 1.10 # tolerate up to 10% latency regression
rollback_if: # ANY triggers immediate rollback
- metric: false_cheap_rate_high_risk
direction: ">"
threshold_abs: 0.02 # hard ceiling regardless of baseline
- metric: error_rate
direction: ">"
threshold_abs: 0.05The asymmetry in the promotion gates mirrors the book's central asymmetry: a candidate policy may not regress false-cheap on high-risk slices at all (the dangerous error), but is allowed a small latency regression (a tolerable cost). The canary is the place the four-box matrix and regret stop being analysis and become a gate, a policy that looks better in offline evaluation but raises false-cheap on the riskiest slice is rejected by the canary before it touches most of the traffic. This is the NIST AI RMF "manage" function operationalized: changes to an automated decision system are validated and reversible.
The fleet lifecycle: adding and retiring models
Models are not permanent. Providers release new ones, deprecate old ones, and the frontier moves (Chapter 2). Operating the fleet means a disciplined lifecycle for each model, add, shadow, canary, promote, retire, that never lets a model into live routing decisions on faith.
Adding a model starts with shadow (Chapter 14): the new model runs in shadow on a sample of real traffic, graded but not served, until you have measured its quality, cost, and latency on your slices, populating its rows in the router_eval table so you know where it sits on your frontier, not the leaderboard's. RouteLLM's transfer-learning finding is relevant: a good router may route sensibly to a new model without retraining, but you still must measure the new model before trusting the route. Only after shadow shows it earns a place on the frontier does it enter routing via canary.
Retiring a model is the more dangerous operation, because routes depend on it. A model that is an escalation target for several slices cannot be removed without first re-routing those slices to a replacement, or escalations will fail. The retirement runbook: identify every route that depends on the model (query the decision log), establish a replacement on the frontier, canary the policy that re-routes to the replacement, and only then remove the model from the fleet. Removing a model that something still routes to is a self-inflicted outage, and the decision log is what tells you what depends on what.
# Model onboarding checklist, enforced as code before a model can serve.
ONBOARDING_GATES = [
"shadow_volume >= 5000 requests across all target slices",
"measured quality recorded per slice in router_eval",
"measured cost reconciled against provider invoice (Ch. 15)",
"measured p95 latency per slice within SLO for target lanes",
"capability manifest written and reviewed (Ch. 17)",
"data-residency / provider allowlist eligibility confirmed (Ch. 17)",
"added to drift canary baseline (Ch. 14)",
"rollback plan: which model handles its routes if it's pulled",]
def can_promote_to_live(model, gates=ONBOARDING_GATES):
return all(gate_passed(model, g) for g in gates) # all-or-nothingRunbooks for the incidents you will have
Three incidents are common enough to pre-write. A pre-written runbook turns a 2 a. m. scramble into a checklist.
Provider outage. Detected by fallback rate spiking on a provider and its circuit breaker opening (Chapter 10). Runbook: confirm the outage is the provider (not your network), verify the mesh is failing over within allowlist constraints (Chapter 17, failover must stay compliant), check that the failover load is not overwhelming the substitute provider, watch the cost (failover loses cache discounts and may use pricier substitutes), and for high-risk slices confirm they are routing to humans rather than silently degrading. Do not disable the circuit breaker to "force retries", that is the retry storm.
Cost spike. Detected by per-tenant or per-route cost crossing a threshold. Runbook: localize via the attribution query (Chapter 15), which tenant, slice, lane? Distinguish legitimate growth (more traffic) from a routing problem (escalation rate up → check verifier threshold or a model regression, Chapter 14) from abuse (one tenant forcing expensive routes → apply the budget guard, Chapter 17). The escalation-rate breakout tells you whether the spike is volume (route distribution stable, more requests) or behavior (route distribution shifted toward expensive lanes).
Quality regression on a route. Detected by false-cheap rate rising on a slice (Chapter 12, from shadow labels). Runbook: check the drift canary (Chapter 14), did a model regress? If yes, re-route the slice away from the regressed model via a canaried policy change and raise the issue with the provider. If no model regressed, the traffic got harder (traffic drift), re-tune the slice's verifier threshold or difficulty boundaries. The diagnostic fork is always model drift vs. traffic drift, and the canary set is what distinguishes them.
Chapter summary
A routing policy is operated, not shipped once: the control room watches per-route, per-slice cost, latency (p95/p99, where the cascade's escalating tail lives), quality (the four-box false-cheap rate from shadow labels), and fallback rate (a degrading provider's early warning), never the average, because the average hides the slices that turn into incidents. The most router-specific signal is route distribution drift: the lane shares are the router's heartbeat, and a shift without a policy change means traffic, model, or price drift (or abuse) moved the world underneath the policy, so alerting on sharp distribution shifts catches problems before their cost and quality consequences fully land. A policy change re-routes traffic instantly and deserves code-deploy discipline: canary it on a stratified slice, promote only on cost-weighted-quality wins with a hard rule that false-cheap on high-risk slices may never regress (the book's asymmetry as a deploy gate, the NIST AI RMF "manage" function made reversible). The fleet has a lifecycle, add, shadow, canary, promote, retire, where a new model must be measured in shadow on your slices before it serves (a leaderboard rank is not a route), and retiring a model requires re-routing its dependents first (query the decision log) or you self-inflict an outage. Finally, pre-write the three common runbooks, provider outage (verify compliant failover, watch the substitute load and cost, never disable the breaker), cost spike (localize by attribution; distinguish volume from escalation-behavior from abuse), and quality regression (the diagnostic fork is always model drift vs. traffic drift, distinguished by the canary set), so the incident is a checklist, not a 2 a. m. scramble.
Internal map
For the larger argument, keep this chapter connected to Model Routing, The Economics of Inference, the smaller-model margin argument, and A Field Guide to Evals.